 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Gaze Generation for Videos with Autoregressive Diffusion
Mar 26, 2026Predicting human gaze in video is fundamental to advancing scene understanding and multimodal interaction. While traditional saliency maps provide spatial probability distributions and scanpaths offer ordered fixations, both abstractions often collapse the fine-grained temporal dynamics of raw gaze. Furthermore, existing models are typically constrained to short-term windows ($\approx$ 3-5s), failing to capture the long-range behavioral dependencies inherent in real-world content. We present a generative framework for infinite-horizon raw gaze prediction in videos of arbitrary length. By leveraging an autoregressive diffusion model, we synthesize gaze trajectories characterized by continuous spatial coordinates and high-resolution timestamps. Our model is conditioned on a saliency-aware visual latent space. Quantitative and qualitative evaluations demonstrate that our approach significantly outperforms existing approaches in long-range spatio-temporal accuracy and trajectory realism.
GeneVA: A Dataset of Human Annotations for Generative Text to Video Artifacts
Sep 10, 2025

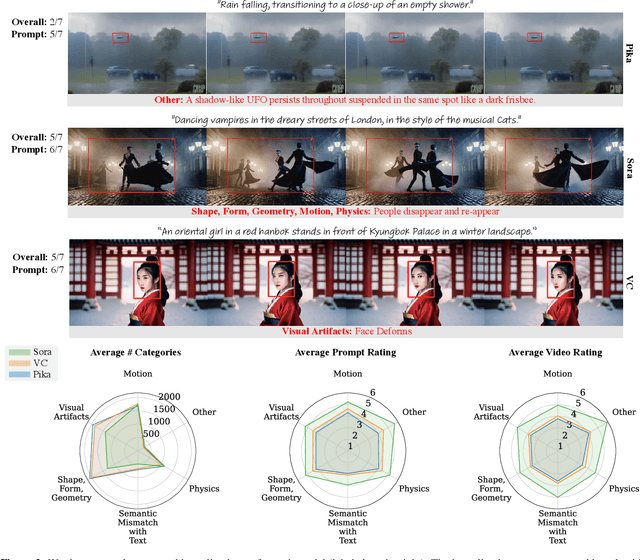
Recent advances in probabilistic generative models have extended capabilities from static image synthesis to text-driven video generation. However, the inherent randomness of their generation process can lead to unpredictable artifacts, such as impossible physics and temporal inconsistency. Progress in addressing these challenges requires systematic benchmarks, yet existing datasets primarily focus on generative images due to the unique spatio-temporal complexities of videos. To bridge this gap, we introduce GeneVA, a large-scale artifact dataset with rich human annotations that focuses on spatio-temporal artifacts in videos generated from natural text prompts. We hope GeneVA can enable and assist critical applications, such as benchmarking model performance and improving generative video quality.
Cost-Aware Routing for Efficient Text-To-Image Generation
Jun 17, 2025



Diffusion models are well known for their ability to generate a high-fidelity image for an input prompt through an iterative denoising process. Unfortunately, the high fidelity also comes at a high computational cost due the inherently sequential generative process. In this work, we seek to optimally balance quality and computational cost, and propose a framework to allow the amount of computation to vary for each prompt, depending on its complexity. Each prompt is automatically routed to the most appropriate text-to-image generation function, which may correspond to a distinct number of denoising steps of a diffusion model, or a disparate, independent text-to-image model. Unlike uniform cost reduction techniques (e.g., distillation, model quantization), our approach achieves the optimal trade-off by learning to reserve expensive choices (e.g., 100+ denoising steps) only for a few complex prompts, and employ more economical choices (e.g., small distilled model) for less sophisticated prompts. We empirically demonstrate on COCO and DiffusionDB that by learning to route to nine already-trained text-to-image models, our approach is able to deliver an average quality that is higher than that achievable by any of these models alone.
StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
Apr 05, 2023Our paper seeks to transfer the hairstyle of a reference image to an input photo for virtual hair try-on. We target a variety of challenges scenarios, such as transforming a long hairstyle with bangs to a pixie cut, which requires removing the existing hair and inferring how the forehead would look, or transferring partially visible hair from a hat-wearing person in a different pose. Past solutions leverage StyleGAN for hallucinating any missing parts and producing a seamless face-hair composite through so-called GAN inversion or projection. However, there remains a challenge in controlling the hallucinations to accurately transfer hairstyle and preserve the face shape and identity of the input. To overcome this, we propose a multi-view optimization framework that uses "two different views" of reference composites to semantically guide occluded or ambiguous regions. Our optimization shares information between two poses, which allows us to produce high fidelity and realistic results from incomplete references. Our framework produces high-quality results and outperforms prior work in a user study that consists of significantly more challenging hair transfer scenarios than previously studied. Project page: https://stylegan-salon.github.io/.
A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch
Aug 05, 2022


We address the problem of retrieving images with both a sketch and a text query. We present TASK-former (Text And SKetch transformer), an end-to-end trainable model for image retrieval using a text description and a sketch as input. We argue that both input modalities complement each other in a manner that cannot be achieved easily by either one alone. TASK-former follows the late-fusion dual-encoder approach, similar to CLIP, which allows efficient and scalable retrieval since the retrieval set can be indexed independently of the queries. We empirically demonstrate that using an input sketch (even a poorly drawn one) in addition to text considerably increases retrieval recall compared to traditional text-based image retrieval. To evaluate our approach, we collect 5,000 hand-drawn sketches for images in the test set of the COCO dataset. The collected sketches are available a https://janesjanes.github.io/tsbir/.
Argoverse: 3D Tracking and Forecasting with Rich Maps
Nov 06, 2019

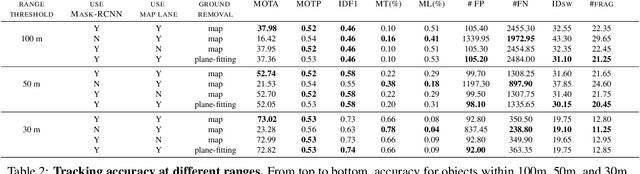
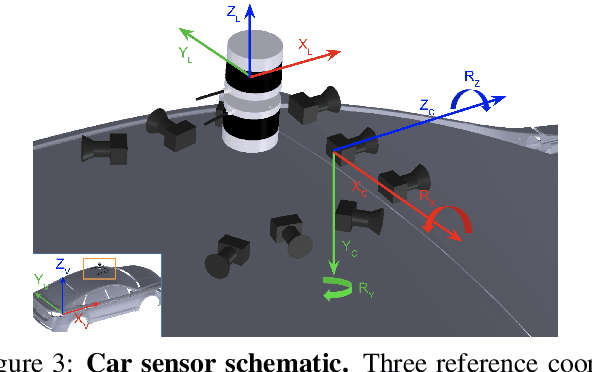
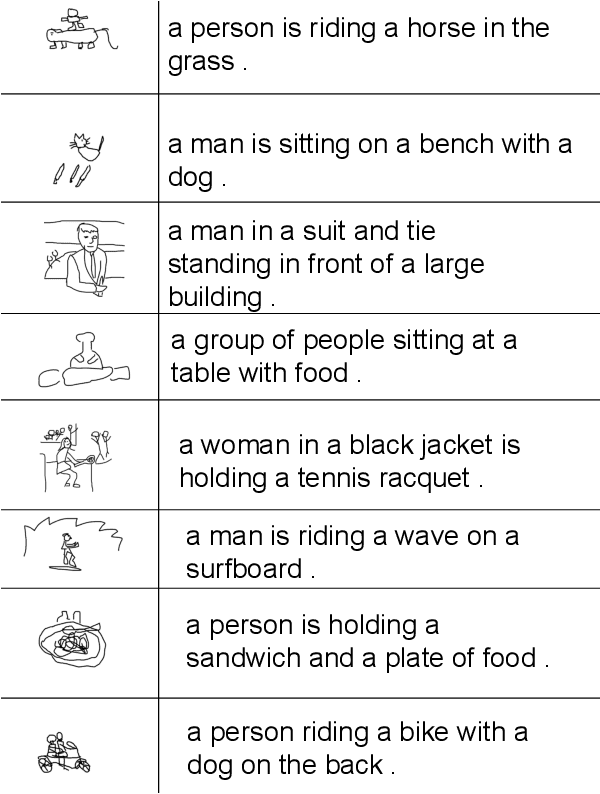
We present Argoverse -- two datasets designed to support autonomous vehicle machine learning tasks such as 3D tracking and motion forecasting. Argoverse was collected by a fleet of autonomous vehicles in Pittsburgh and Miami. The Argoverse 3D Tracking dataset includes 360 degree images from 7 cameras with overlapping fields of view, 3D point clouds from long range LiDAR, 6-DOF pose, and 3D track annotations. Notably, it is the only modern AV dataset that provides forward-facing stereo imagery. The Argoverse Motion Forecasting dataset includes more than 300,000 5-second tracked scenarios with a particular vehicle identified for trajectory forecasting. Argoverse is the first autonomous vehicle dataset to include "HD maps" with 290 km of mapped lanes with geometric and semantic metadata. All data is released under a Creative Commons license at www.argoverse.org. In our baseline experiments, we illustrate how detailed map information such as lane direction, driveable area, and ground height improves the accuracy of 3D object tracking and motion forecasting. Our tracking and forecasting experiments represent only an initial exploration of the use of rich maps in robotic perception. We hope that Argoverse will enable the research community to explore these problems in greater depth.
Kernel Mean Matching for Content Addressability of GANs
May 14, 2019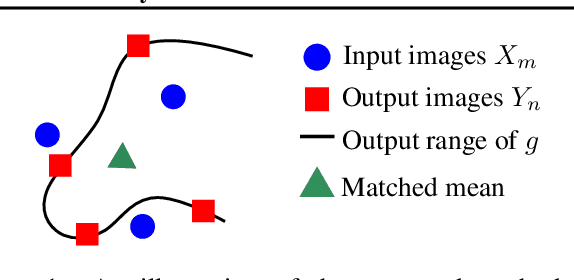
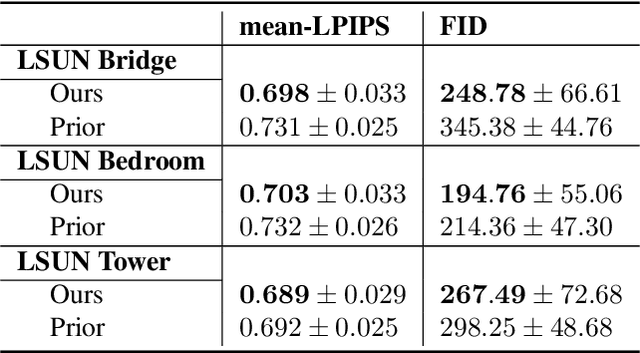


We propose a novel procedure which adds "content-addressability" to any given unconditional implicit model e.g., a generative adversarial network (GAN). The procedure allows users to control the generative process by specifying a set (arbitrary size) of desired examples based on which similar samples are generated from the model. The proposed approach, based on kernel mean matching, is applicable to any generative models which transform latent vectors to samples, and does not require retraining of the model. Experiments on various high-dimensional image generation problems (CelebA-HQ, LSUN bedroom, bridge, tower) show that our approach is able to generate images which are consistent with the input set, while retaining the image quality of the original model. To our knowledge, this is the first work that attempts to construct, at test time, a content-addressable generative model from a trained marginal model.
Informative Features for Model Comparison
Oct 27, 2018
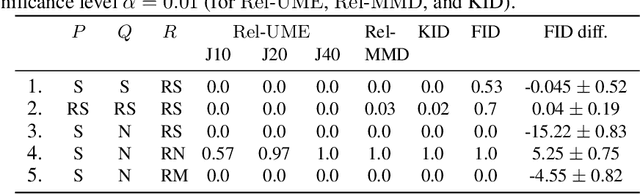


Given two candidate models, and a set of target observations, we address the problem of measuring the relative goodness of fit of the two models. We propose two new statistical tests which are nonparametric, computationally efficient (runtime complexity is linear in the sample size), and interpretable. As a unique advantage, our tests can produce a set of examples (informative features) indicating the regions in the data domain where one model fits significantly better than the other. In a real-world problem of comparing GAN models, the test power of our new test matches that of the state-of-the-art test of relative goodness of fit, while being one order of magnitude faster.
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
Apr 14, 2018



In this paper, we investigate deep image synthesis guided by sketch, color, and texture. Previous image synthesis methods can be controlled by sketch and color strokes but we are the first to examine texture control. We allow a user to place a texture patch on a sketch at arbitrary locations and scales to control the desired output texture. Our generative network learns to synthesize objects consistent with these texture suggestions. To achieve this, we develop a local texture loss in addition to adversarial and content loss to train the generative network. We conduct experiments using sketches generated from real images and textures sampled from a separate texture database and results show that our proposed algorithm is able to generate plausible images that are faithful to user controls. Ablation studies show that our proposed pipeline can generate more realistic images than adapting existing methods directly.
Let's Dance: Learning From Online Dance Videos
Jan 23, 2018
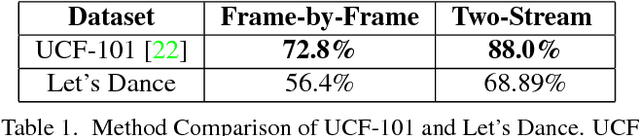

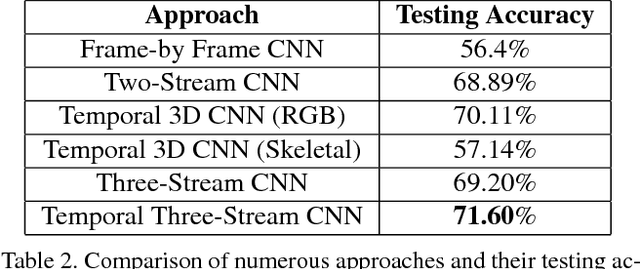
In recent years, deep neural network approaches have naturally extended to the video domain, in their simplest case by aggregating per-frame classifications as a baseline for action recognition. A majority of the work in this area extends from the imaging domain, leading to visual-feature heavy approaches on temporal data. To address this issue we introduce "Let's Dance", a 1000 video dataset (and growing) comprised of 10 visually overlapping dance categories that require motion for their classification. We stress the important of human motion as a key distinguisher in our work given that, as we show in this work, visual information is not sufficient to classify motion-heavy categories. We compare our datasets' performance using imaging techniques with UCF-101 and demonstrate this inherent difficulty. We present a comparison of numerous state-of-the-art techniques on our dataset using three different representations (video, optical flow and multi-person pose data) in order to analyze these approaches. We discuss the motion parameterization of each of them and their value in learning to categorize online dance videos. Lastly, we release this dataset (and its three representations) for the research community to use.