 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Argoverse: 3D Tracking and Forecasting with Rich Maps
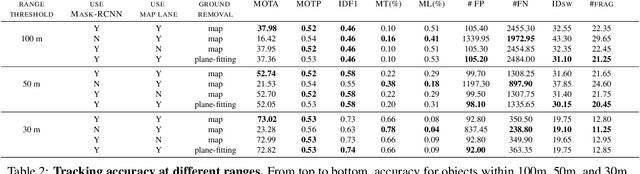
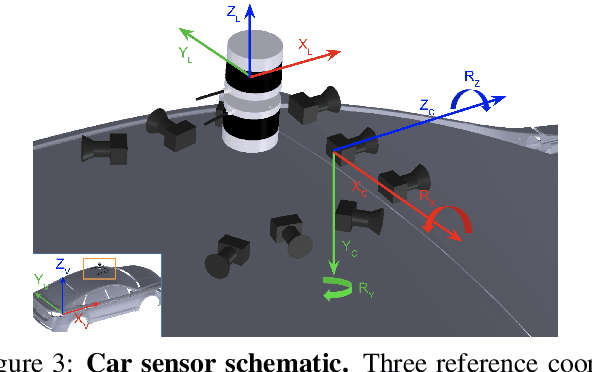
Nov 06, 2019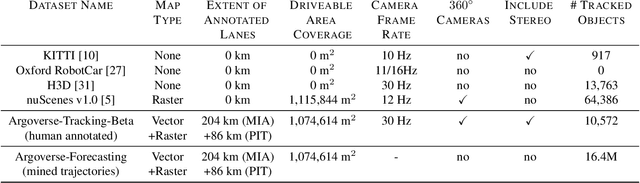

We present Argoverse -- two datasets designed to support autonomous vehicle machine learning tasks such as 3D tracking and motion forecasting. Argoverse was collected by a fleet of autonomous vehicles in Pittsburgh and Miami. The Argoverse 3D Tracking dataset includes 360 degree images from 7 cameras with overlapping fields of view, 3D point clouds from long range LiDAR, 6-DOF pose, and 3D track annotations. Notably, it is the only modern AV dataset that provides forward-facing stereo imagery. The Argoverse Motion Forecasting dataset includes more than 300,000 5-second tracked scenarios with a particular vehicle identified for trajectory forecasting. Argoverse is the first autonomous vehicle dataset to include "HD maps" with 290 km of mapped lanes with geometric and semantic metadata. All data is released under a Creative Commons license at www.argoverse.org. In our baseline experiments, we illustrate how detailed map information such as lane direction, driveable area, and ground height improves the accuracy of 3D object tracking and motion forecasting. Our tracking and forecasting experiments represent only an initial exploration of the use of rich maps in robotic perception. We hope that Argoverse will enable the research community to explore these problems in greater depth.
Coordinated Multi-Agent Imitation Learning
May 25, 2018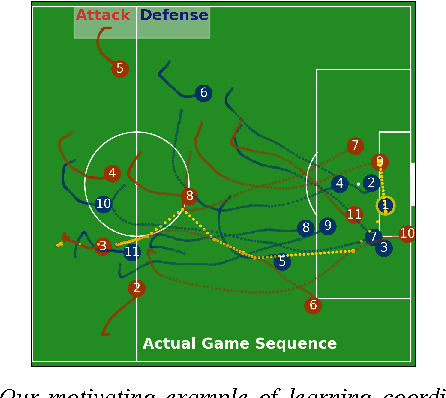
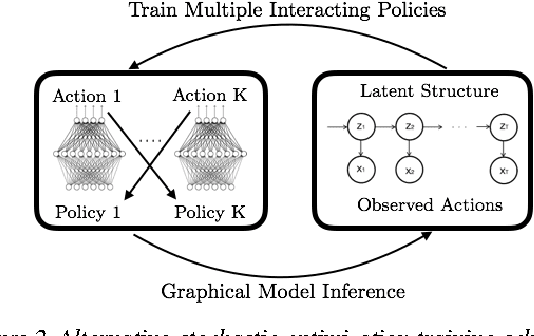
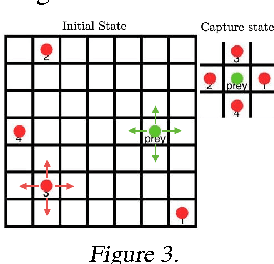
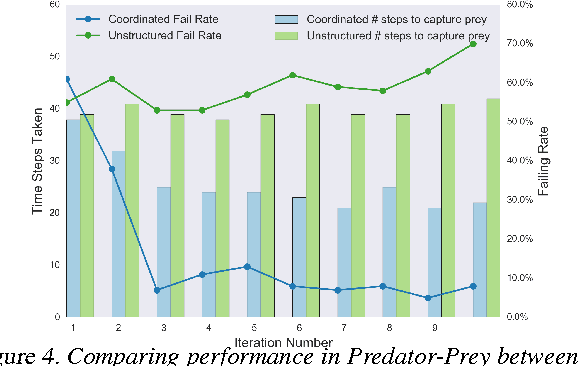
We study the problem of imitation learning from demonstrations of multiple coordinating agents. One key challenge in this setting is that learning a good model of coordination can be difficult, since coordination is often implicit in the demonstrations and must be inferred as a latent variable. We propose a joint approach that simultaneously learns a latent coordination model along with the individual policies. In particular, our method integrates unsupervised structure learning with conventional imitation learning. We illustrate the power of our approach on a difficult problem of learning multiple policies for fine-grained behavior modeling in team sports, where different players occupy different roles in the coordinated team strategy. We show that having a coordination model to infer the roles of players yields substantially improved imitation loss compared to conventional baselines.
* International Conference on Machine Learning 2017
Domain Adaptation through Synthesis for Unsupervised Person Re-identification
Apr 26, 2018
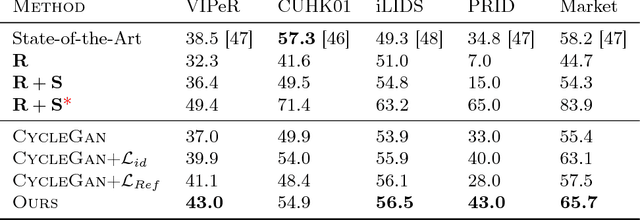

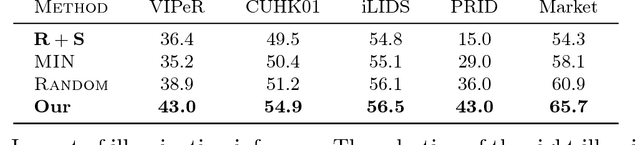
Drastic variations in illumination across surveillance cameras make the person re-identification problem extremely challenging. Current large scale re-identification datasets have a significant number of training subjects, but lack diversity in lighting conditions. As a result, a trained model requires fine-tuning to become effective under an unseen illumination condition. To alleviate this problem, we introduce a new synthetic dataset that contains hundreds of illumination conditions. Specifically, we use 100 virtual humans illuminated with multiple HDR environment maps which accurately model realistic indoor and outdoor lighting. To achieve better accuracy in unseen illumination conditions we propose a novel domain adaptation technique that takes advantage of our synthetic data and performs fine-tuning in a completely unsupervised way. Our approach yields significantly higher accuracy than semi-supervised and unsupervised state-of-the-art methods, and is very competitive with supervised techniques.
Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification
Mar 27, 2018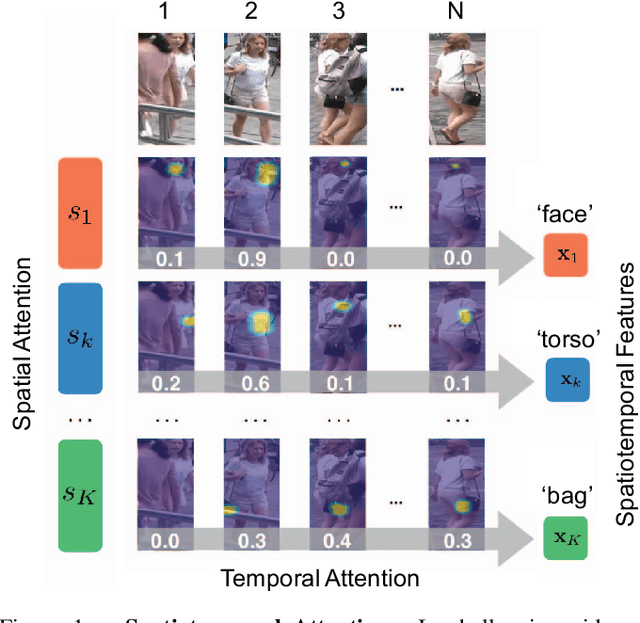
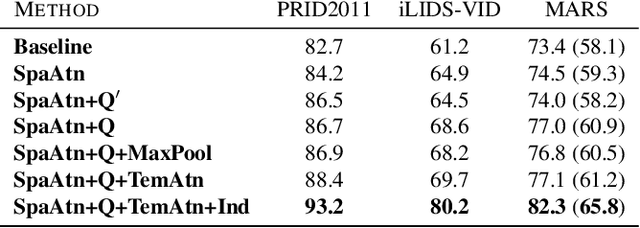
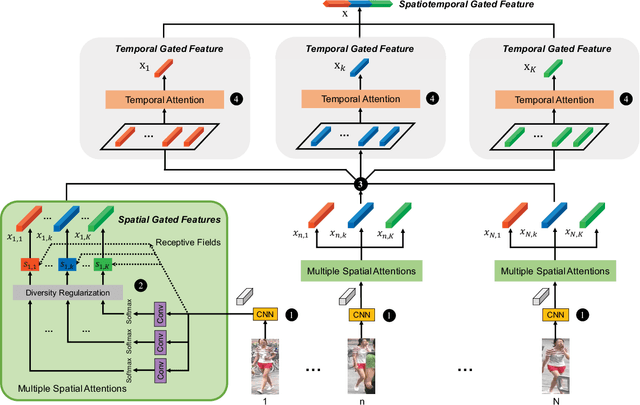
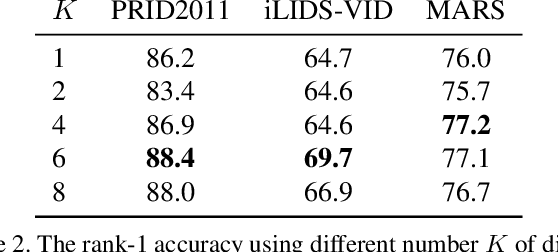
Video-based person re-identification matches video clips of people across non-overlapping cameras. Most existing methods tackle this problem by encoding each video frame in its entirety and computing an aggregate representation across all frames. In practice, people are often partially occluded, which can corrupt the extracted features. Instead, we propose a new spatiotemporal attention model that automatically discovers a diverse set of distinctive body parts. This allows useful information to be extracted from all frames without succumbing to occlusions and misalignments. The network learns multiple spatial attention models and employs a diversity regularization term to ensure multiple models do not discover the same body part. Features extracted from local image regions are organized by spatial attention model and are combined using temporal attention. As a result, the network learns latent representations of the face, torso and other body parts using the best available image patches from the entire video sequence. Extensive evaluations on three datasets show that our framework outperforms the state-of-the-art approaches by large margins on multiple metrics.
Smooth Imitation Learning for Online Sequence Prediction
Jun 03, 2016
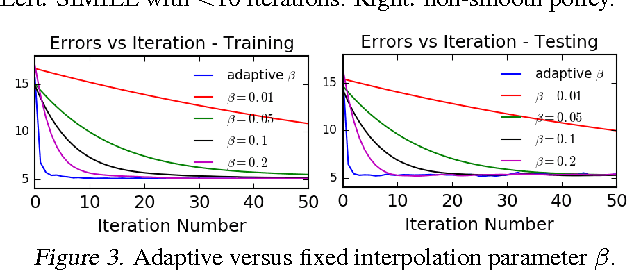
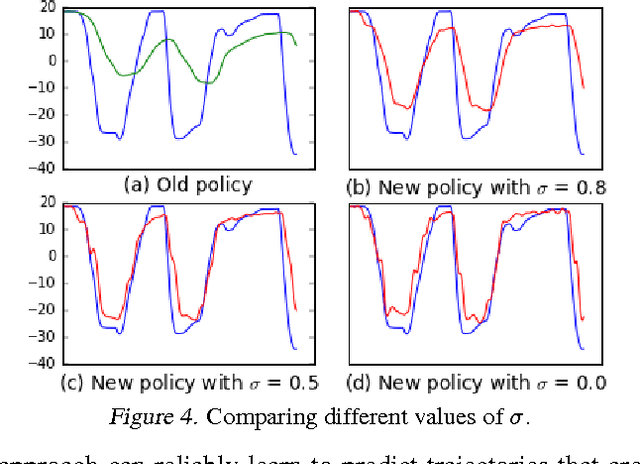
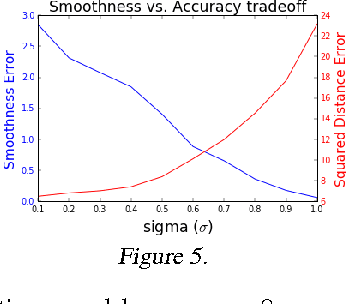
We study the problem of smooth imitation learning for online sequence prediction, where the goal is to train a policy that can smoothly imitate demonstrated behavior in a dynamic and continuous environment in response to online, sequential context input. Since the mapping from context to behavior is often complex, we take a learning reduction approach to reduce smooth imitation learning to a regression problem using complex function classes that are regularized to ensure smoothness. We present a learning meta-algorithm that achieves fast and stable convergence to a good policy. Our approach enjoys several attractive properties, including being fully deterministic, employing an adaptive learning rate that can provably yield larger policy improvements compared to previous approaches, and the ability to ensure stable convergence. Our empirical results demonstrate significant performance gains over previous approaches.