 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless sEMG-IMU Wearable for Real-Time Squat Kinematics and Muscle Activation
Dec 22, 2025This work presents the design and implementation of a wireless, wearable system that combines surface electromyography (sEMG) and inertial measurement units (IMUs) to analyze a single lower-limb functional task: the free bodyweight squat in a healthy adult. The system records bipolar EMG from one agonist and one antagonist muscle of the dominant leg (vastus lateralis and semitendinosus) while simultaneously estimating knee joint angle, angular velocity, and angular acceleration using two MPU6050 IMUs. A custom dual-channel EMG front end with differential instrumentation preamplification, analog filtering (5-500 Hz band-pass and 60 Hz notch), high final gain, and rectified-integrated output was implemented on a compact 10 cm x 12 cm PCB. Data are digitized by an ESP32 microcontroller and transmitted wirelessly via ESP-NOW to a second ESP32 connected to a PC. A Python-based graphical user interface (GUI) displays EMG and kinematic signals in real time, manages subject metadata, and exports a summary of each session to Excel. The complete system is battery-powered to reduce electrical risk during human use. The resulting prototype demonstrates the feasibility of low-cost, portable EMG-IMU instrumentation for integrated analysis of muscle activation and squat kinematics and provides a platform for future biomechanical applications in sports performance and rehabilitation.
Talking to GDELT Through Knowledge Graphs
Mar 10, 2025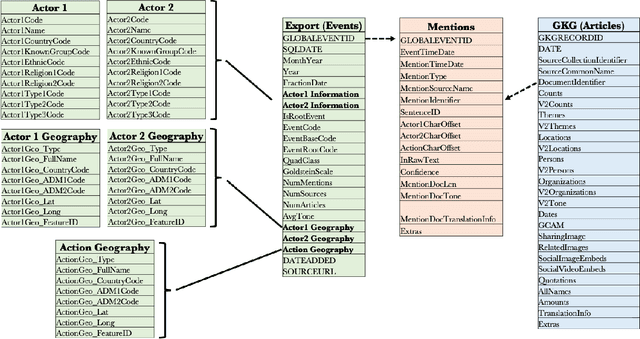
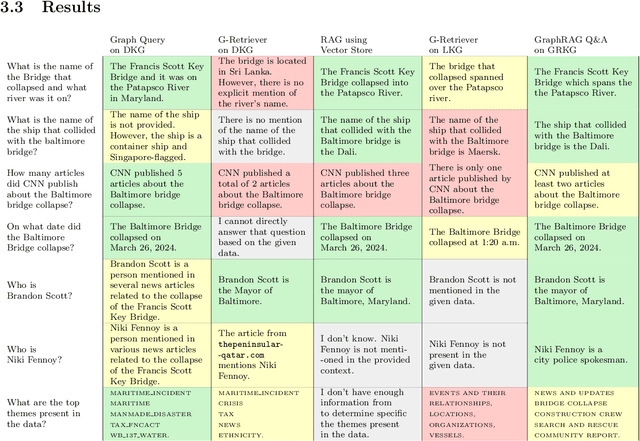
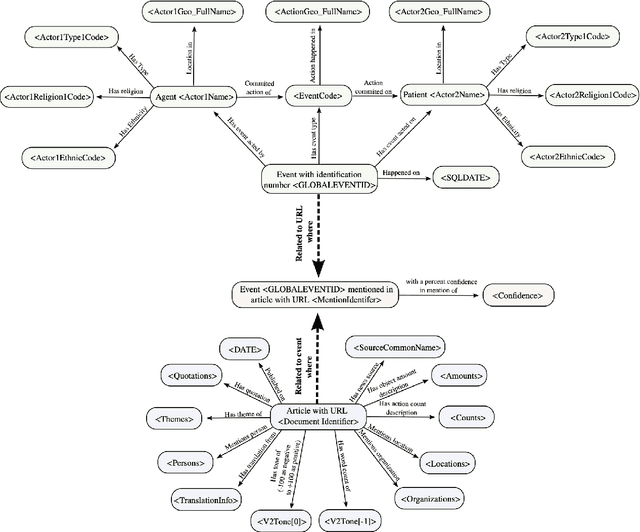
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
What Matters in Range View 3D Object Detection
Jul 25, 2024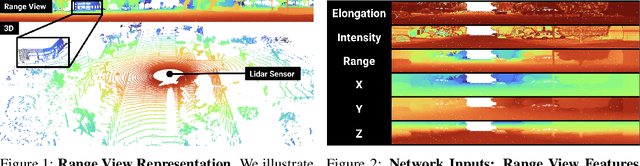
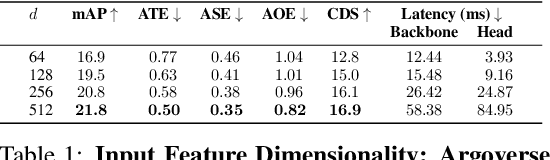
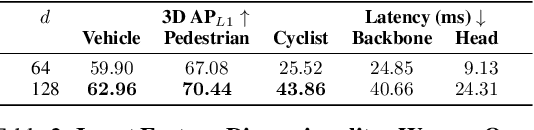
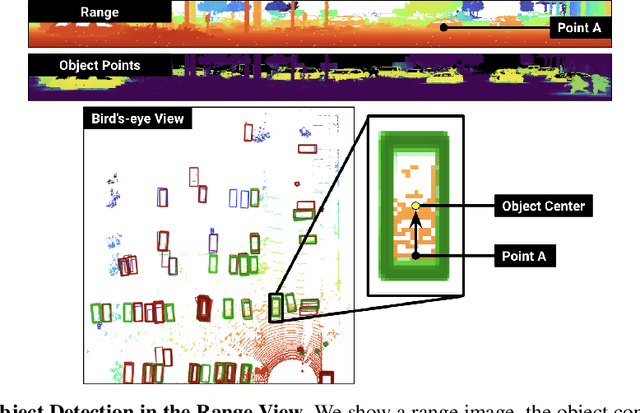
Lidar-based perception pipelines rely on 3D object detection models to interpret complex scenes. While multiple representations for lidar exist, the range-view is enticing since it losslessly encodes the entire lidar sensor output. In this work, we achieve state-of-the-art amongst range-view 3D object detection models without using multiple techniques proposed in past range-view literature. We explore range-view 3D object detection across two modern datasets with substantially different properties: Argoverse 2 and Waymo Open. Our investigation reveals key insights: (1) input feature dimensionality significantly influences the overall performance, (2) surprisingly, employing a classification loss grounded in 3D spatial proximity works as well or better compared to more elaborate IoU-based losses, and (3) addressing non-uniform lidar density via a straightforward range subsampling technique outperforms existing multi-resolution, range-conditioned networks. Our experiments reveal that techniques proposed in recent range-view literature are not needed to achieve state-of-the-art performance. Combining the above findings, we establish a new state-of-the-art model for range-view 3D object detection -- improving AP by 2.2% on the Waymo Open dataset while maintaining a runtime of 10 Hz. We establish the first range-view model on the Argoverse 2 dataset and outperform strong voxel-based baselines. All models are multi-class and open-source. Code is available at https://github.com/benjaminrwilson/range-view-3d-detection.
An Empirical Analysis of Range for 3D Object Detection
Aug 08, 2023LiDAR-based 3D detection plays a vital role in autonomous navigation. Surprisingly, although autonomous vehicles (AVs) must detect both near-field objects (for collision avoidance) and far-field objects (for longer-term planning), contemporary benchmarks focus only on near-field 3D detection. However, AVs must detect far-field objects for safe navigation. In this paper, we present an empirical analysis of far-field 3D detection using the long-range detection dataset Argoverse 2.0 to better understand the problem, and share the following insight: near-field LiDAR measurements are dense and optimally encoded by small voxels, while far-field measurements are sparse and are better encoded with large voxels. We exploit this observation to build a collection of range experts tuned for near-vs-far field detection, and propose simple techniques to efficiently ensemble models for long-range detection that improve efficiency by 33% and boost accuracy by 3.2% CDS.
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
NukeLM: Pre-Trained and Fine-Tuned Language Models for the Nuclear and Energy Domains
May 25, 2021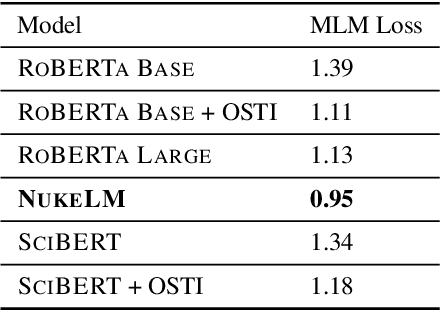
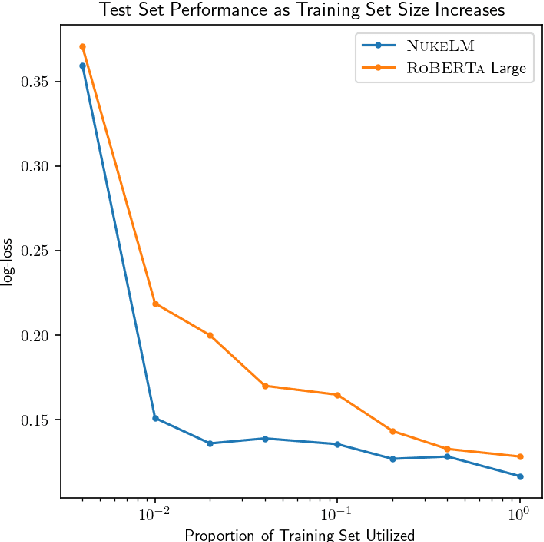
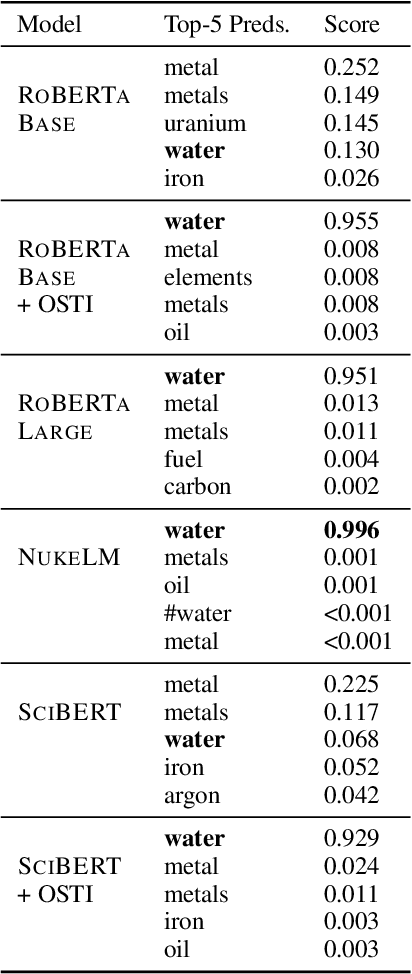
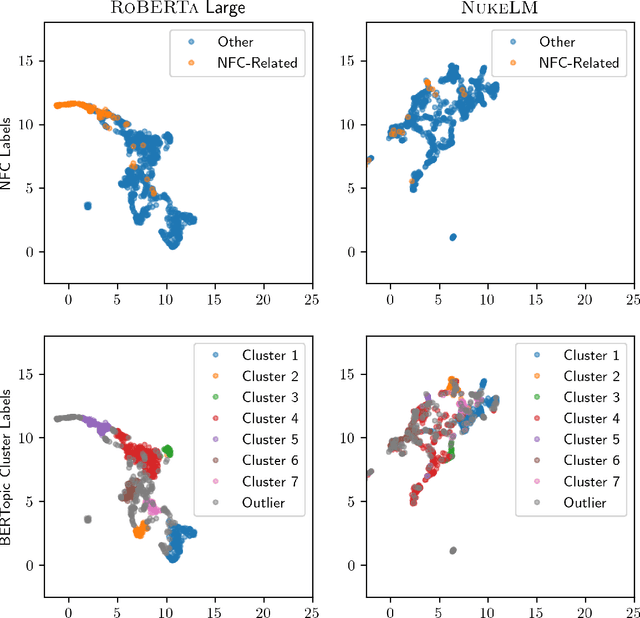
Natural language processing (NLP) tasks (text classification, named entity recognition, etc.) have seen revolutionary improvements over the last few years. This is due to language models such as BERT that achieve deep knowledge transfer by using a large pre-trained model, then fine-tuning the model on specific tasks. The BERT architecture has shown even better performance on domain-specific tasks when the model is pre-trained using domain-relevant texts. Inspired by these recent advancements, we have developed NukeLM, a nuclear-domain language model pre-trained on 1.5 million abstracts from the U.S. Department of Energy Office of Scientific and Technical Information (OSTI) database. This NukeLM model is then fine-tuned for the classification of research articles into either binary classes (related to the nuclear fuel cycle [NFC] or not) or multiple categories related to the subject of the article. We show that continued pre-training of a BERT-style architecture prior to fine-tuning yields greater performance on both article classification tasks. This information is critical for properly triaging manuscripts, a necessary task for better understanding citation networks that publish in the nuclear space, and for uncovering new areas of research in the nuclear (or nuclear-relevant) domains.
Learning phylogenetic trees as hyperbolic point configurations
Apr 23, 2021
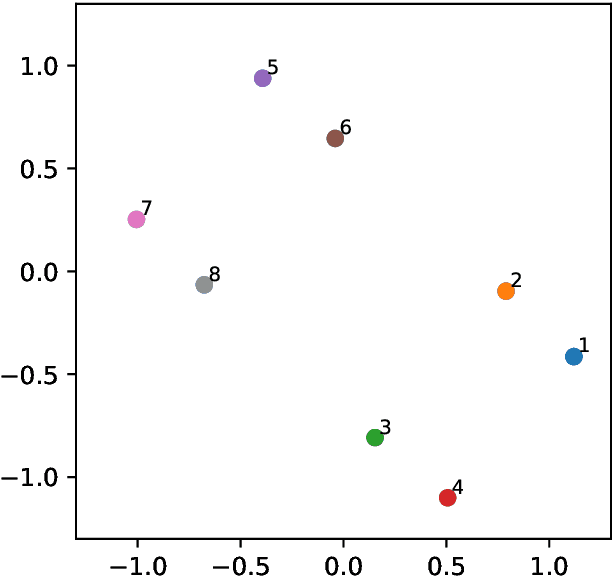
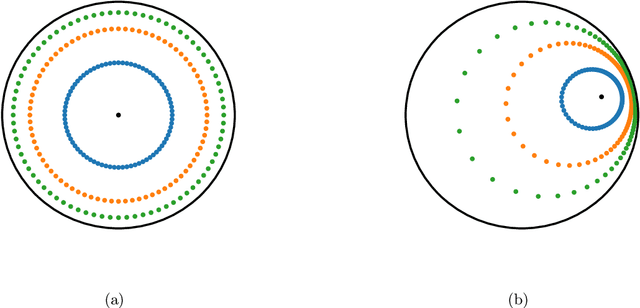
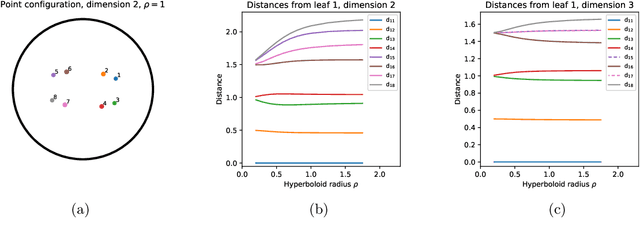
An alternative to independent pairwise distance estimation is proposed that uses hyperbolic geometry to jointly estimate pairwise distances subject to a weakening of the four point condition that characterises tree metrics. Specifically, taxa are represented as points in hyperbolic space such that the distance between a pair of points accounts for the site differences between the corresponding taxa. The proposed algorithm iteratively rearranges the points to increase an objective function that is shown empirically to increase the log-likelihood employed in tree search. Unlike the log-likelihood on tree space, the proposed objective function is differentiable, allowing for the use of gradient-based techniques in its optimisation. It is shown that the error term in the weakened four point condition is bounded by a linear function of the radius parameter of the hyperboloid model, which controls the curvature of the space. The error may thus be made as small as desired, within the bounds of computational precision.
3D for Free: Crossmodal Transfer Learning using HD Maps
Aug 24, 2020
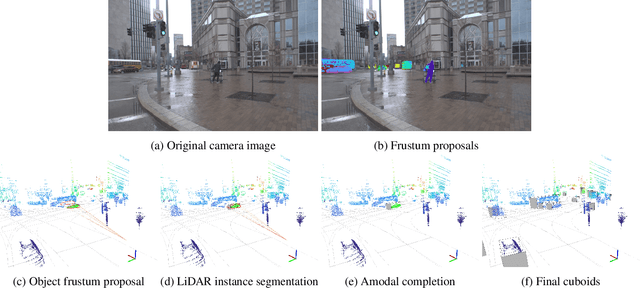


3D object detection is a core perceptual challenge for robotics and autonomous driving. However, the class-taxonomies in modern autonomous driving datasets are significantly smaller than many influential 2D detection datasets. In this work, we address the long-tail problem by leveraging both the large class-taxonomies of modern 2D datasets and the robustness of state-of-the-art 2D detection methods. We proceed to mine a large, unlabeled dataset of images and LiDAR, and estimate 3D object bounding cuboids, seeded from an off-the-shelf 2D instance segmentation model. Critically, we constrain this ill-posed 2D-to-3D mapping by using high-definition maps and object size priors. The result of the mining process is 3D cuboids with varying confidence. This mining process is itself a 3D object detector, although not especially accurate when evaluated as such. However, we then train a 3D object detection model on these cuboids, consistent with other recent observations in the deep learning literature, we find that the resulting model is fairly robust to the noisy supervision that our mining process provides. We mine a collection of 1151 unlabeled, multimodal driving logs from an autonomous vehicle and use the discovered objects to train a LiDAR-based object detector. We show that detector performance increases as we mine more unlabeled data. With our full, unlabeled dataset, our method performs competitively with fully supervised methods, even exceeding the performance for certain object categories, without any human 3D annotations.
Predictive Inequity in Object Detection
Feb 21, 2019

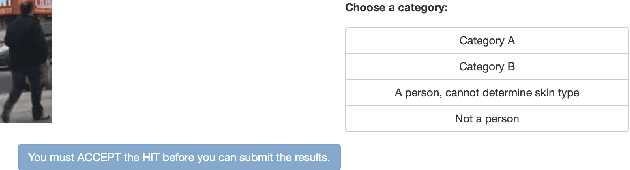

In this work, we investigate whether state-of-the-art object detection systems have equitable predictive performance on pedestrians with different skin tones. This work is motivated by many recent examples of ML and vision systems displaying higher error rates for certain demographic groups than others. We annotate an existing large scale dataset which contains pedestrians, BDD100K, with Fitzpatrick skin tones in ranges [1-3] or [4-6]. We then provide an in-depth comparative analysis of performance between these two skin tone groupings, finding that neither time of day nor occlusion explain this behavior, suggesting this disparity is not merely the result of pedestrians in the 4-6 range appearing in more difficult scenes for detection. We investigate to what extent time of day, occlusion, and reweighting the supervised loss during training affect this predictive bias.