 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Needles in Document Haystacks: Sensitivity Testing of LLM-as-a-Judge Similarity Scoring
Apr 20, 2026We propose a scalable, multifactorial experimental framework that systematically probes LLM sensitivity to subtle semantic changes in pairwise document comparison. We analogize this as a needle-in-a-haystack problem: a single semantically altered sentence (the needle) is embedded within surrounding context (the hay), and we vary the perturbation type (negation, conjunction swap, named entity replacement), context type (original vs. topically unrelated), needle position, and document length across all combinations, testing five LLMs on tens of thousands of document pairs. Our analysis reveals several striking findings. First, LLMs exhibit a within-document positional bias distinct from previously studied candidate-order effects: most models penalize semantic differences more harshly when they occur earlier in a document. Second, when the altered sentence is surrounded by topically unrelated context, it systematically lowers similarity scores and induces bipolarized scores that indicate either very low or very high similarity. This is consistent with an interpretive frame account in which topically-related context may allow models to contextualize and downweight the alterations. Third, each LLM produces a qualitatively distinct scoring distribution, a stable "fingerprint" that is invariant to perturbation type, yet all models share a universal hierarchy in how leniently they treat different perturbation types. Together, these results demonstrate that LLM semantic similarity scores are sensitive to document structure, context coherence, and model identity in ways that go beyond the semantic change itself, and that the proposed framework offers a practical, LLM-agnostic toolkit for auditing and comparing scoring behavior across current and future models.
Talking to GDELT Through Knowledge Graphs
Mar 10, 2025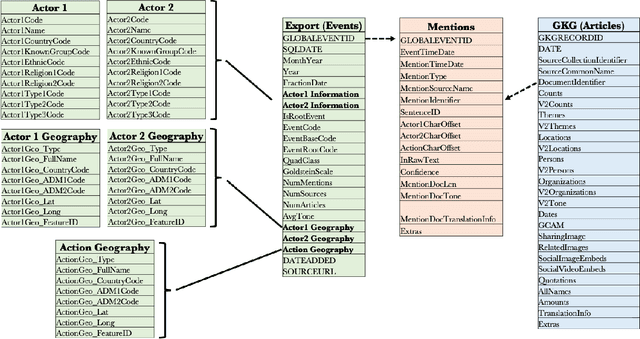
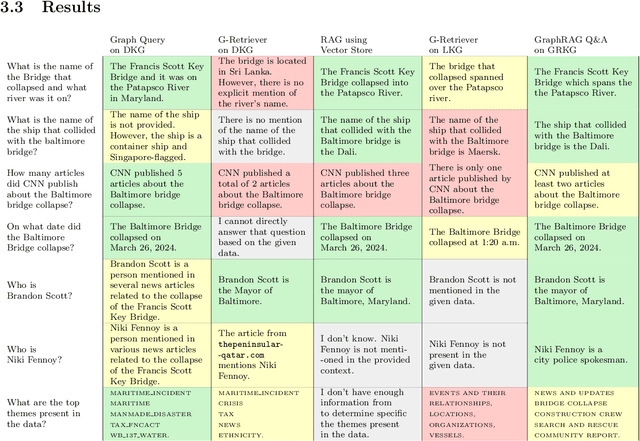
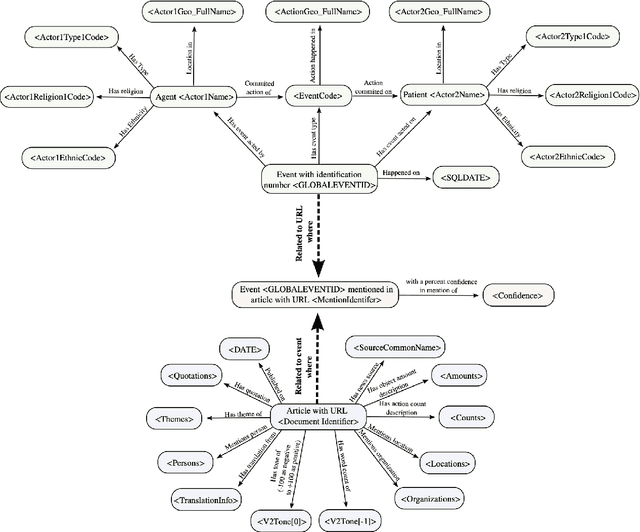
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
HyperMagNet: A Magnetic Laplacian based Hypergraph Neural Network
Feb 15, 2024



In data science, hypergraphs are natural models for data exhibiting multi-way relations, whereas graphs only capture pairwise. Nonetheless, many proposed hypergraph neural networks effectively reduce hypergraphs to undirected graphs via symmetrized matrix representations, potentially losing important information. We propose an alternative approach to hypergraph neural networks in which the hypergraph is represented as a non-reversible Markov chain. We use this Markov chain to construct a complex Hermitian Laplacian matrix - the magnetic Laplacian - which serves as the input to our proposed hypergraph neural network. We study HyperMagNet for the task of node classification, and demonstrate its effectiveness over graph-reduction based hypergraph neural networks.
Randomized Algorithms for Symmetric Nonnegative Matrix Factorization
Feb 13, 2024Symmetric Nonnegative Matrix Factorization (SymNMF) is a technique in data analysis and machine learning that approximates a symmetric matrix with a product of a nonnegative, low-rank matrix and its transpose. To design faster and more scalable algorithms for SymNMF we develop two randomized algorithms for its computation. The first algorithm uses randomized matrix sketching to compute an initial low-rank input matrix and proceeds to use this input to rapidly compute a SymNMF. The second algorithm uses randomized leverage score sampling to approximately solve constrained least squares problems. Many successful methods for SymNMF rely on (approximately) solving sequences of constrained least squares problems. We prove theoretically that leverage score sampling can approximately solve nonnegative least squares problems to a chosen accuracy with high probability. Finally we demonstrate that both methods work well in practice by applying them to graph clustering tasks on large real world data sets. These experiments show that our methods approximately maintain solution quality and achieve significant speed ups for both large dense and large sparse problems.
Scalable tensor methods for nonuniform hypergraphs
Jun 30, 2023While multilinear algebra appears natural for studying the multiway interactions modeled by hypergraphs, tensor methods for general hypergraphs have been stymied by theoretical and practical barriers. A recently proposed adjacency tensor is applicable to nonuniform hypergraphs, but is prohibitively costly to form and analyze in practice. We develop tensor times same vector (TTSV) algorithms for this tensor which improve complexity from $O(n^r)$ to a low-degree polynomial in $r$, where $n$ is the number of vertices and $r$ is the maximum hyperedge size. Our algorithms are implicit, avoiding formation of the order $r$ adjacency tensor. We demonstrate the flexibility and utility of our approach in practice by developing tensor-based hypergraph centrality and clustering algorithms. We also show these tensor measures offer complementary information to analogous graph-reduction approaches on data, and are also able to detect higher-order structure that many existing matrix-based approaches provably cannot.
Seven open problems in applied combinatorics
Mar 20, 2023



We present and discuss seven different open problems in applied combinatorics. The application areas relevant to this compilation include quantum computing, algorithmic differentiation, topological data analysis, iterative methods, hypergraph cut algorithms, and power systems.
Skew-Symmetric Adjacency Matrices for Clustering Directed Graphs
Mar 02, 2022
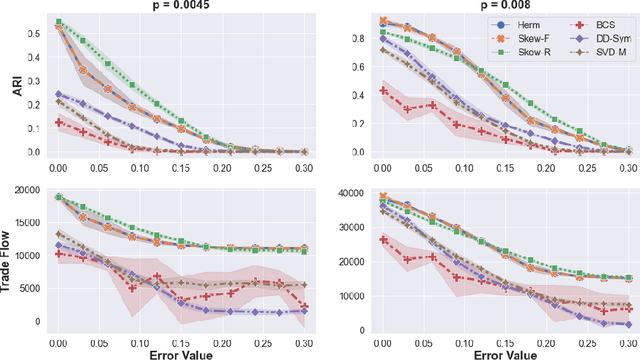

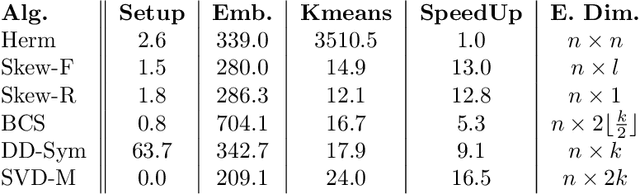
Cut-based directed graph (digraph) clustering often focuses on finding dense within-cluster or sparse between-cluster connections, similar to cut-based undirected graph clustering methods. In contrast, for flow-based clusterings the edges between clusters tend to be oriented in one direction and have been found in migration data, food webs, and trade data. In this paper we introduce a spectral algorithm for finding flow-based clusterings. The proposed algorithm is based on recent work which uses complex-valued Hermitian matrices to represent digraphs. By establishing an algebraic relationship between a complex-valued Hermitian representation and an associated real-valued, skew-symmetric matrix the proposed algorithm produces clusterings while remaining completely in the real field. Our algorithm uses less memory and asymptotically less computation while provably preserving solution quality. We also show the algorithm can be easily implemented using standard computational building blocks, possesses better numerical properties, and loans itself to a natural interpretation via an objective function relaxation argument.
Hypergraph Random Walks, Laplacians, and Clustering
Jun 29, 2020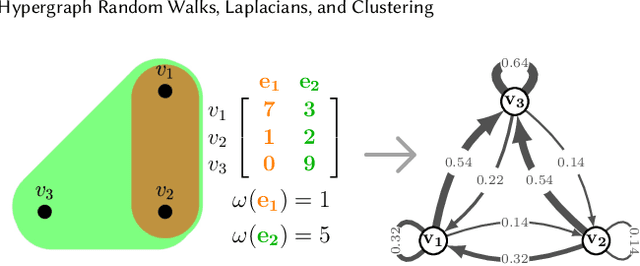
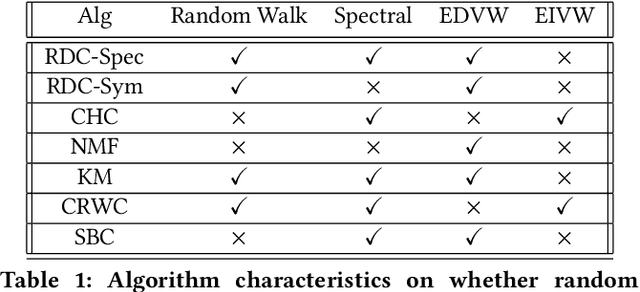
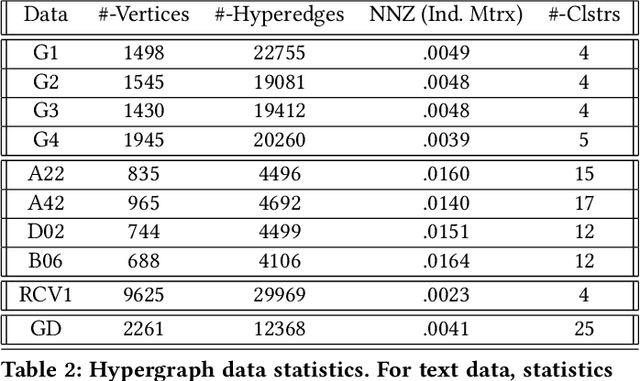

We propose a flexible framework for clustering hypergraph-structured data based on recently proposed random walks utilizing edge-dependent vertex weights. When incorporating edge-dependent vertex weights (EDVW), a weight is associated with each vertex-hyperedge pair, yielding a weighted incidence matrix of the hypergraph. Such weightings have been utilized in term-document representations of text data sets. We explain how random walks with EDVW serve to construct different hypergraph Laplacian matrices, and then develop a suite of clustering methods that use these incidence matrices and Laplacians for hypergraph clustering. Using several data sets from real-life applications, we compare the performance of these clustering algorithms experimentally against a variety of existing hypergraph clustering methods. We show that the proposed methods produce higher-quality clusters and conclude by highlighting avenues for future work.
Relative Hausdorff Distance for Network Analysis
Jun 12, 2019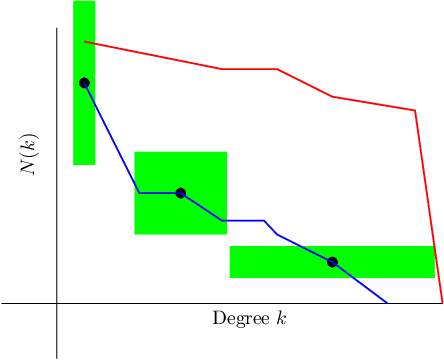
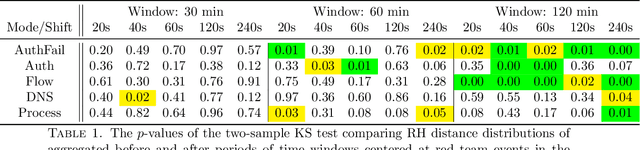
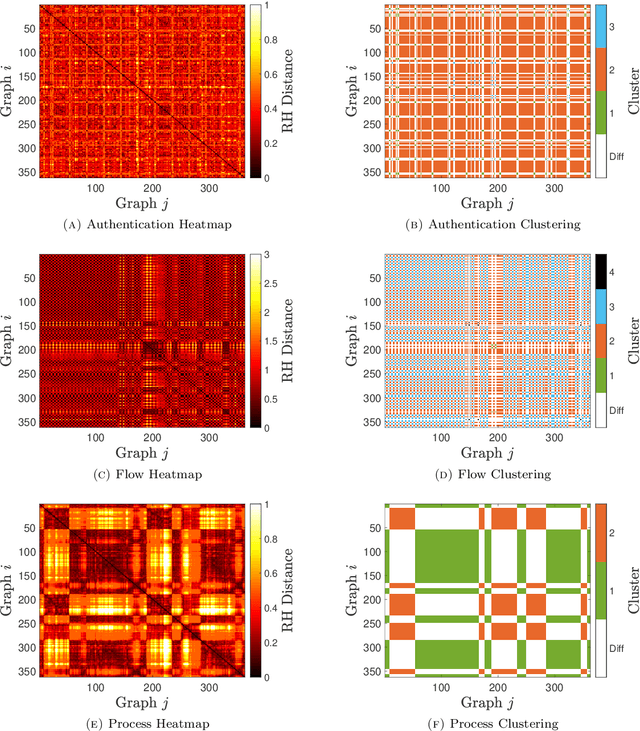
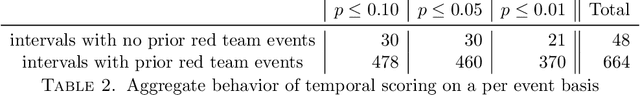
Similarity measures are used extensively in machine learning and data science algorithms. The newly proposed graph Relative Hausdorff (RH) distance is a lightweight yet nuanced similarity measure for quantifying the closeness of two graphs. In this work we study the effectiveness of RH distance as a tool for detecting anomalies in time-evolving graph sequences. We apply RH to cyber data with given red team events, as well to synthetically generated sequences of graphs with planted attacks. In our experiments, the performance of RH distance is at times comparable, and sometimes superior, to graph edit distance in detecting anomalous phenomena. Our results suggest that in appropriate contexts, RH distance has advantages over more computationally intensive similarity measures.