 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperMagNet: A Magnetic Laplacian based Hypergraph Neural Network
Feb 15, 2024



In data science, hypergraphs are natural models for data exhibiting multi-way relations, whereas graphs only capture pairwise. Nonetheless, many proposed hypergraph neural networks effectively reduce hypergraphs to undirected graphs via symmetrized matrix representations, potentially losing important information. We propose an alternative approach to hypergraph neural networks in which the hypergraph is represented as a non-reversible Markov chain. We use this Markov chain to construct a complex Hermitian Laplacian matrix - the magnetic Laplacian - which serves as the input to our proposed hypergraph neural network. We study HyperMagNet for the task of node classification, and demonstrate its effectiveness over graph-reduction based hypergraph neural networks.
Scalable tensor methods for nonuniform hypergraphs
Jun 30, 2023While multilinear algebra appears natural for studying the multiway interactions modeled by hypergraphs, tensor methods for general hypergraphs have been stymied by theoretical and practical barriers. A recently proposed adjacency tensor is applicable to nonuniform hypergraphs, but is prohibitively costly to form and analyze in practice. We develop tensor times same vector (TTSV) algorithms for this tensor which improve complexity from $O(n^r)$ to a low-degree polynomial in $r$, where $n$ is the number of vertices and $r$ is the maximum hyperedge size. Our algorithms are implicit, avoiding formation of the order $r$ adjacency tensor. We demonstrate the flexibility and utility of our approach in practice by developing tensor-based hypergraph centrality and clustering algorithms. We also show these tensor measures offer complementary information to analogous graph-reduction approaches on data, and are also able to detect higher-order structure that many existing matrix-based approaches provably cannot.
Fair Clustering for Diverse and Experienced Groups
Jun 11, 2020


The ability for machine learning to exacerbate bias has led to many algorithms centered on fairness. For example, fair clustering algorithms typically focus on balanced representation of protected attributes within clusters. Here, we develop a fair clustering variant where the input data is a hypergraph with multiple edge types, representing information about past experiences of groups of individuals. Our method is based on diversity of experience, instead of protected attributes, with a goal of forming groups that have both experience and diversity with respect to participation in edge types. We model this goal with a regularized edge-based clustering objective, design an efficient 2-approximation algorithm for optimizing the NP-hard objective, and provide bounds on hyperparameters to avoid trivial solutions. We demonstrate a potential application of this framework in online review platforms, where the goal is to curate sets of user reviews for a product type. In this context, "experience" corresponds to users familiar with the type of product, and "diversity" to users that have reviewed related products.
Hypergraph clustering with categorical edge labels
Oct 22, 2019


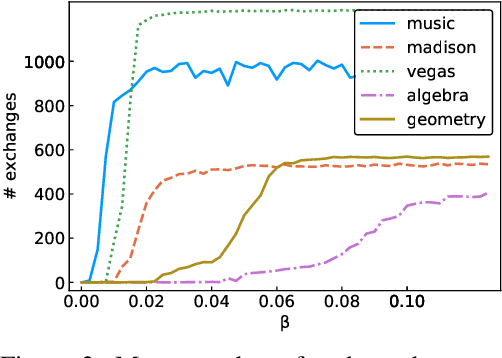
Graphs and networks are a standard model for describing data or systems based on pairwise interactions. Oftentimes, the underlying relationships involve more than two entities at a time, and hypergraphs are a more faithful model. However, we have fewer rigorous methods that can provide insight from such representations. Here, we develop a computational framework for the problem of clustering hypergraphs with categorical edge labels --- or different interaction types --- where clusters corresponds to groups of nodes that frequently participate in the same type of interaction. Our methodology is based on a combinatorial objective function that is related to correlation clustering but enables the design of much more efficient algorithms. When there are only two label types, our objective can be optimized in polynomial time, using an algorithm based on minimum cuts. Minimizing our objective becomes NP-hard with more than two label types, but we develop fast approximation algorithms based on linear programming relaxations that have theoretical cluster quality guarantees. We demonstrate the efficacy of our algorithms and the scope of the model through problems in edge-label community detection, clustering with temporal data, and exploratory data analysis.
Planted Hitting Set Recovery in Hypergraphs
May 14, 2019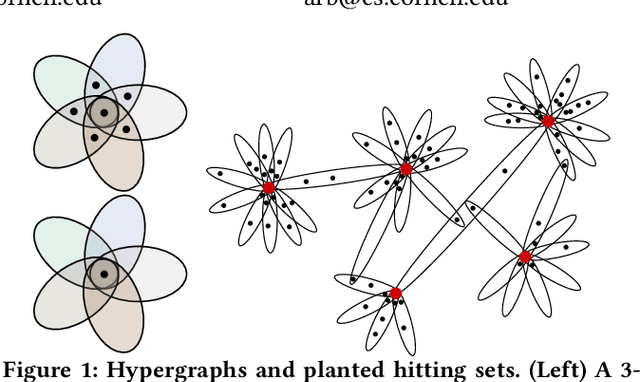
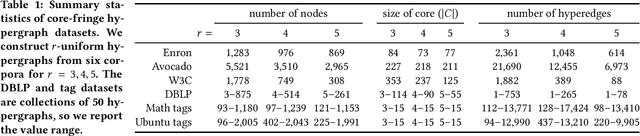


In various application areas, networked data is collected by measuring interactions involving some specific set of core nodes. This results in a network dataset containing the core nodes along with a potentially much larger set of fringe nodes that all have at least one interaction with a core node. In many settings, this type of data arises for structures that are richer than graphs, because they involve the interactions of larger sets; for example, the core nodes might be a set of individuals under surveillance, where we observe the attendees of meetings involving at least one of the core individuals. We model such scenarios using hypergraphs, and we study the problem of core recovery: if we observe the hypergraph but not the labels of core and fringe nodes, can we recover the "planted" set of core nodes in the hypergraph? We provide a theoretical framework for analyzing the recovery of such a set of core nodes and use our theory to develop a practical and scalable algorithm for core recovery. The crux of our analysis and algorithm is that the core nodes are a hitting set of the hypergraph, meaning that every hyperedge has at least one node in the set of core nodes. We demonstrate the efficacy of our algorithm on a number of real-world datasets, outperforming competitive baselines derived from network centrality and core-periphery measures.