 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA collaborative ensemble construction method for federated random forest
Jul 27, 2024Random forests are considered a cornerstone in machine learning for their robustness and versatility. Despite these strengths, their conventional centralized training is ill-suited for the modern landscape of data that is often distributed, sensitive, and subject to privacy concerns. Federated learning (FL) provides a compelling solution to this problem, enabling models to be trained across a group of clients while maintaining the privacy of each client's data. However, adapting tree-based methods like random forests to federated settings introduces significant challenges, particularly when it comes to non-identically distributed (non-IID) data across clients, which is a common scenario in real-world applications. This paper presents a federated random forest approach that employs a novel ensemble construction method aimed at improving performance under non-IID data. Instead of growing trees independently in each client, our approach ensures each decision tree in the ensemble is iteratively and collectively grown across clients. To preserve the privacy of the client's data, we confine the information stored in the leaf nodes to the majority class label identified from the samples of the client's local data that reach each node. This limited disclosure preserves the confidentiality of the underlying data distribution of clients, thereby enhancing the privacy of the federated learning process. Furthermore, our collaborative ensemble construction strategy allows the ensemble to better reflect the data's heterogeneity across different clients, enhancing its performance on non-IID data, as our experimental results confirm.
* This is the authors' accepted manuscript of an article published in the journal Expert Systems With Applications. Published version available at: https://www.sciencedirect.com/science/article/pii/S0957417424016099. 22 pages, 3 figures
Hypergraph Random Walks, Laplacians, and Clustering
Jun 29, 2020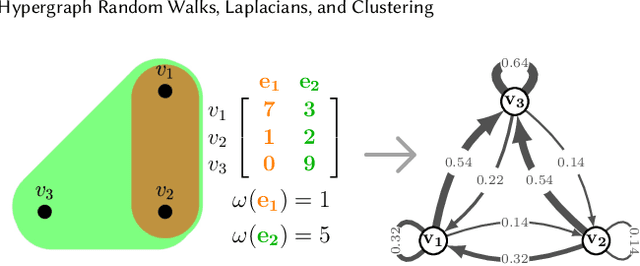
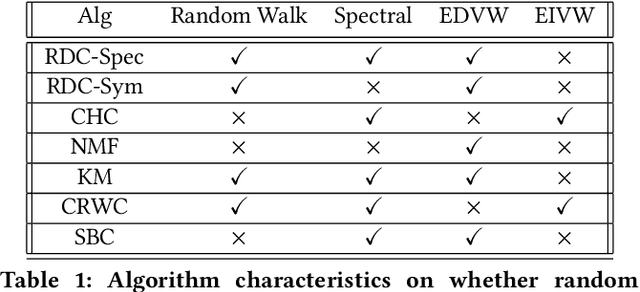
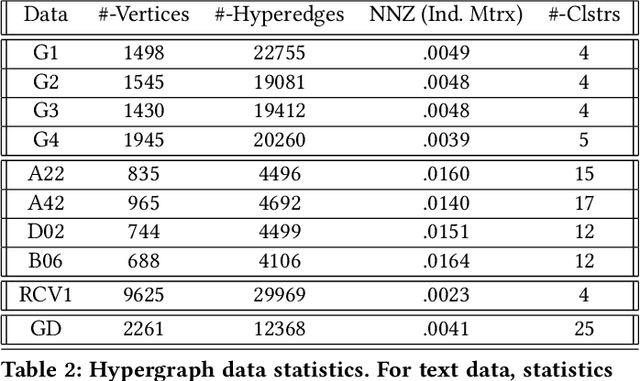

We propose a flexible framework for clustering hypergraph-structured data based on recently proposed random walks utilizing edge-dependent vertex weights. When incorporating edge-dependent vertex weights (EDVW), a weight is associated with each vertex-hyperedge pair, yielding a weighted incidence matrix of the hypergraph. Such weightings have been utilized in term-document representations of text data sets. We explain how random walks with EDVW serve to construct different hypergraph Laplacian matrices, and then develop a suite of clustering methods that use these incidence matrices and Laplacians for hypergraph clustering. Using several data sets from real-life applications, we compare the performance of these clustering algorithms experimentally against a variety of existing hypergraph clustering methods. We show that the proposed methods produce higher-quality clusters and conclude by highlighting avenues for future work.