 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking to GDELT Through Knowledge Graphs
Mar 10, 2025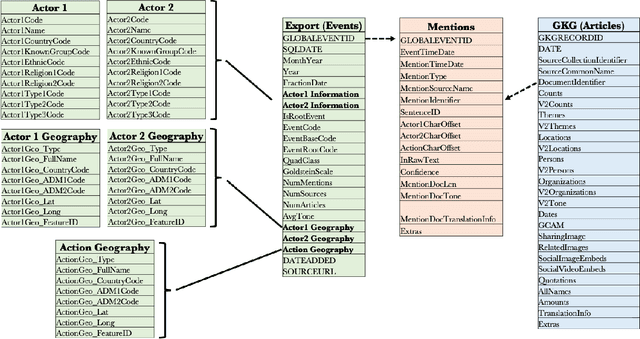
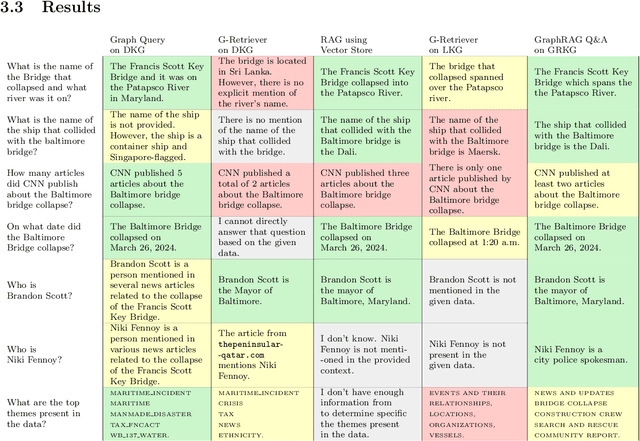
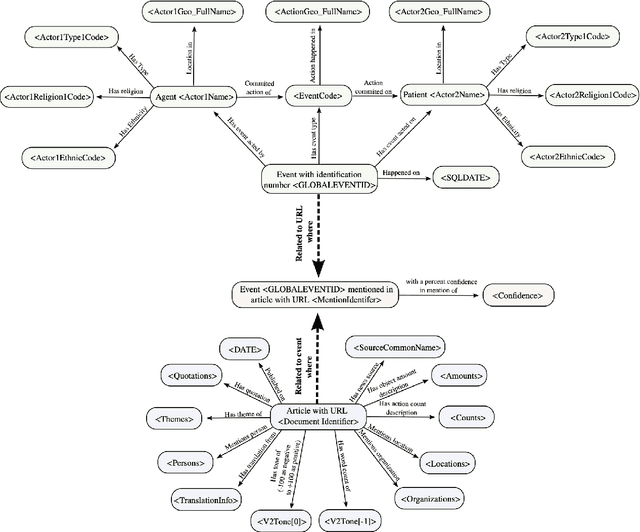
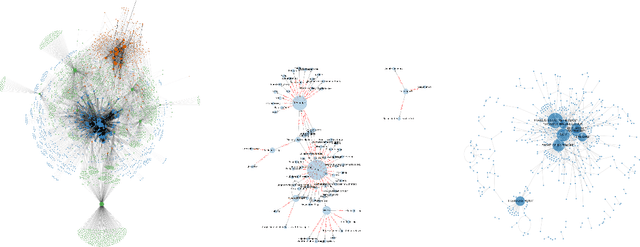
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
Understanding Generative AI Content with Embedding Models
Aug 19, 2024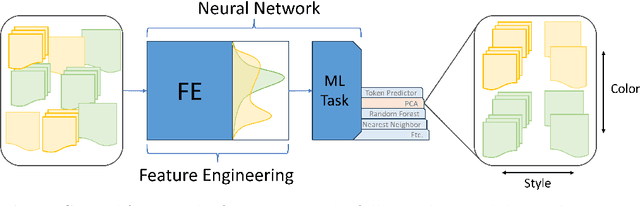

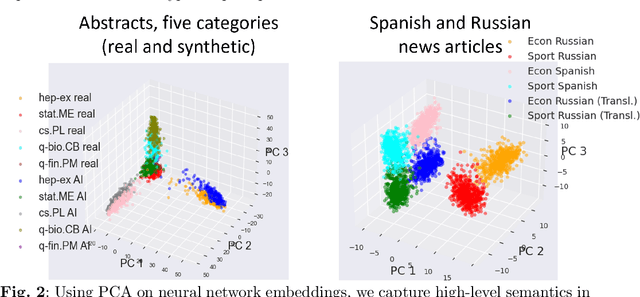
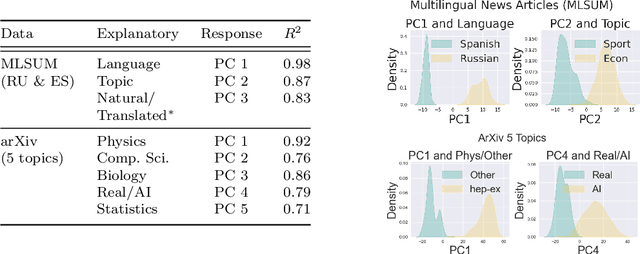
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.
Efficient kernel surrogates for neural network-based regression
Oct 28, 2023



Despite their immense promise in performing a variety of learning tasks, a theoretical understanding of the effectiveness and limitations of Deep Neural Networks (DNNs) has so far eluded practitioners. This is partly due to the inability to determine the closed forms of the learned functions, making it harder to assess their precise dependence on the training data and to study their generalization properties on unseen datasets. Recent work has shown that randomly initialized DNNs in the infinite width limit converge to kernel machines relying on a Neural Tangent Kernel (NTK) with known closed form. These results suggest, and experimental evidence corroborates, that empirical kernel machines can also act as surrogates for finite width DNNs. The high computational cost of assembling the full NTK, however, makes this approach infeasible in practice, motivating the need for low-cost approximations. In the current work, we study the performance of the Conjugate Kernel (CK), an efficient approximation to the NTK that has been observed to yield fairly similar results. For the regression problem of smooth functions and classification using logistic regression, we show that the CK performance is only marginally worse than that of the NTK and, in certain cases, is shown to be superior. In particular, we establish bounds for the relative test losses, verify them with numerical tests, and identify the regularity of the kernel as the key determinant of performance. In addition to providing a theoretical grounding for using CKs instead of NTKs, our framework provides insights into understanding the robustness of the various approximants and suggests a recipe for improving DNN accuracy inexpensively. We present a demonstration of this on the foundation model GPT-2 by comparing its performance on a classification task using a conventional approach and our prescription.
Foundation Model's Embedded Representations May Detect Distribution Shift
Oct 20, 2023



Distribution shifts between train and test datasets obscure our ability to understand the generalization capacity of neural network models. This topic is especially relevant given the success of pre-trained foundation models as starting points for transfer learning (TL) models across tasks and contexts. We present a case study for TL on a pre-trained GPT-2 model onto the Sentiment140 dataset for sentiment classification. We show that Sentiment140's test dataset $M$ is not sampled from the same distribution as the training dataset $P$, and hence training on $P$ and measuring performance on $M$ does not actually account for the model's generalization on sentiment classification.