 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Generative AI Content with Embedding Models
Paper and Code
Aug 19, 2024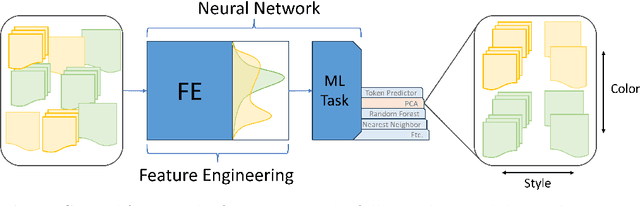

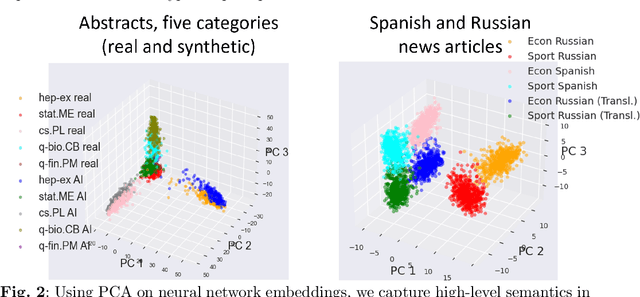
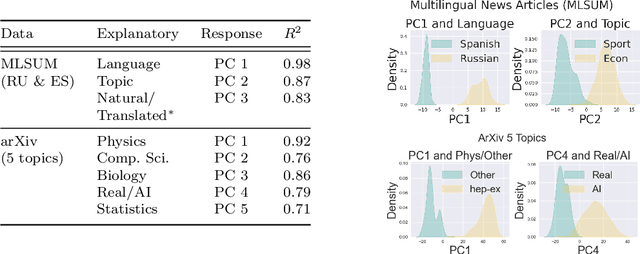
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.