 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Generative Models for Structured Data
Mar 26, 2025



Synthetic tabular data generation has emerged as a promising method to address limited data availability and privacy concerns. With the sharp increase in the performance of large language models in recent years, researchers have been interested in applying these models to the generation of tabular data. However, little is known about the quality of the generated tabular data from large language models. The predominant method for assessing the quality of synthetic tabular data is the train-synthetic-test-real approach, where the artificial examples are compared to the original by how well machine learning models, trained separately on the real and synthetic sets, perform in some downstream tasks. This method does not directly measure how closely the distribution of generated data approximates that of the original. This paper introduces rigorous methods for directly assessing synthetic tabular data against real data by looking at inter-column dependencies within the data. We find that large language models (GPT-2), both when queried via few-shot prompting and when fine-tuned, and GAN (CTGAN) models do not produce data with dependencies that mirror the original real data. Results from this study can inform future practice in synthetic data generation to improve data quality.
Understanding Generative AI Content with Embedding Models
Aug 19, 2024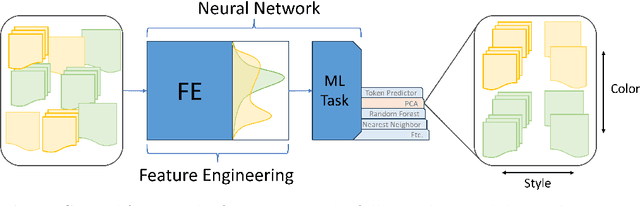

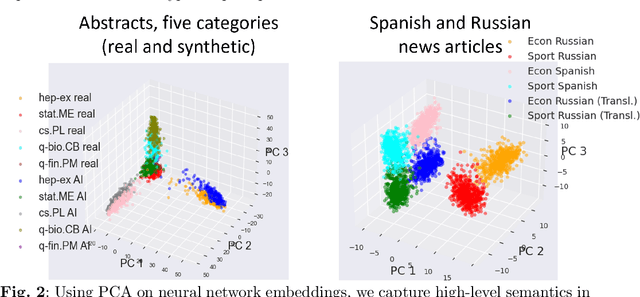
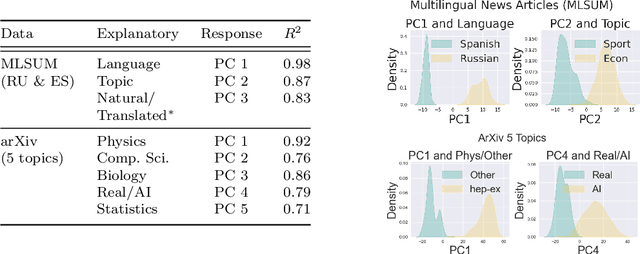
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.
Measuring model variability using robust non-parametric testing
Jun 12, 2024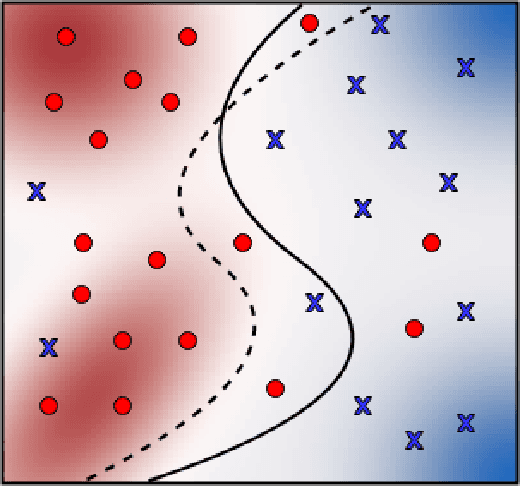



Training a deep neural network often involves stochastic optimization, meaning each run will produce a different model. The seed used to initialize random elements of the optimization procedure heavily influences the quality of a trained model, which may be obscure from many commonly reported summary statistics, like accuracy. However, random seed is often not included in hyper-parameter optimization, perhaps because the relationship between seed and model quality is hard to describe. This work attempts to describe the relationship between deep net models trained with different random seeds and the behavior of the expected model. We adopt robust hypothesis testing to propose a novel summary statistic for network similarity, referred to as the $\alpha$-trimming level. We use the $\alpha$-trimming level to show that the empirical cumulative distribution function of an ensemble model created from a collection of trained models with different random seeds approximates the average of these functions as the number of models in the collection grows large. This insight provides guidance for how many random seeds should be sampled to ensure that an ensemble of these trained models is a reliable representative. We also show that the $\alpha$-trimming level is more expressive than different performance metrics like validation accuracy, churn, or expected calibration error when taken alone and may help with random seed selection in a more principled fashion. We demonstrate the value of the proposed statistic in real experiments and illustrate the advantage of fine-tuning over random seed with an experiment in transfer learning.
Robust Nonparametric Hypothesis Testing to Understand Variability in Training Neural Networks
Oct 01, 2023



Training a deep neural network (DNN) often involves stochastic optimization, which means each run will produce a different model. Several works suggest this variability is negligible when models have the same performance, which in the case of classification is test accuracy. However, models with similar test accuracy may not be computing the same function. We propose a new measure of closeness between classification models based on the output of the network before thresholding. Our measure is based on a robust hypothesis-testing framework and can be adapted to other quantities derived from trained models.