 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMantis Shrimp: Exploring Photometric Band Utilization in Computer Vision Networks for Photometric Redshift Estimation
Jan 15, 2025We present Mantis Shrimp, a multi-survey deep learning model for photometric redshift estimation that fuses ultra-violet (GALEX), optical (PanSTARRS), and infrared (UnWISE) imagery. Machine learning is now an established approach for photometric redshift estimation, with generally acknowledged higher performance in areas with a high density of spectroscopically identified galaxies over template-based methods. Multiple works have shown that image-based convolutional neural networks can outperform tabular-based color/magnitude models. In comparison to tabular models, image models have additional design complexities: it is largely unknown how to fuse inputs from different instruments which have different resolutions or noise properties. The Mantis Shrimp model estimates the conditional density estimate of redshift using cutout images. The density estimates are well calibrated and the point estimates perform well in the distribution of available spectroscopically confirmed galaxies with (bias = 1e-2), scatter (NMAD = 2.44e-2) and catastrophic outlier rate ($\eta$=17.53$\%$). We find that early fusion approaches (e.g., resampling and stacking images from different instruments) match the performance of late fusion approaches (e.g., concatenating latent space representations), so that the design choice ultimately is left to the user. Finally, we study how the models learn to use information across bands, finding evidence that our models successfully incorporates information from all surveys. The applicability of our model to the analysis of large populations of galaxies is limited by the speed of downloading cutouts from external servers; however, our model could be useful in smaller studies such as generating priors over redshift for stellar population synthesis.
Understanding Generative AI Content with Embedding Models
Aug 19, 2024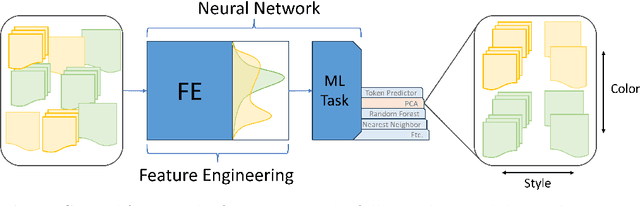

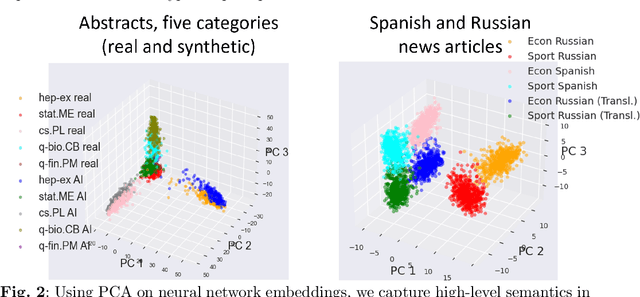
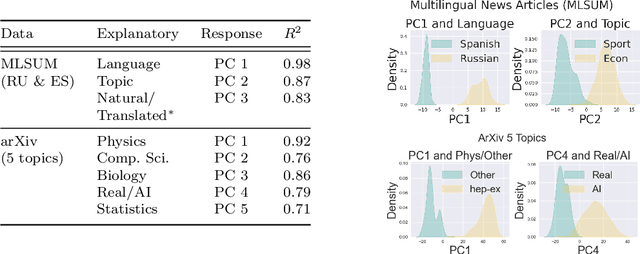
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.
Preliminary Report on Mantis Shrimp: a Multi-Survey Computer Vision Photometric Redshift Model
Feb 05, 2024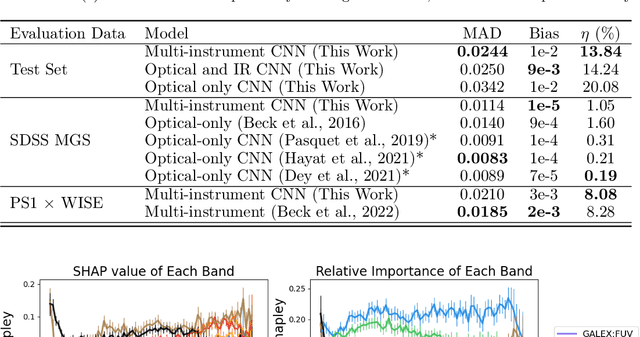
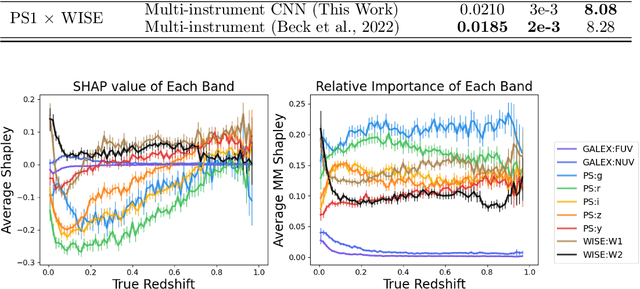
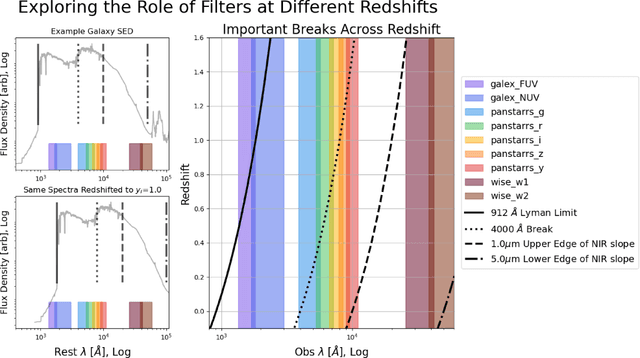
The availability of large, public, multi-modal astronomical datasets presents an opportunity to execute novel research that straddles the line between science of AI and science of astronomy. Photometric redshift estimation is a well-established subfield of astronomy. Prior works show that computer vision models typically outperform catalog-based models, but these models face additional complexities when incorporating images from more than one instrument or sensor. In this report, we detail our progress creating Mantis Shrimp, a multi-survey computer vision model for photometric redshift estimation that fuses ultra-violet (GALEX), optical (PanSTARRS), and infrared (UnWISE) imagery. We use deep learning interpretability diagnostics to measure how the model leverages information from the different inputs. We reason about the behavior of the CNNs from the interpretability metrics, specifically framing the result in terms of physically-grounded knowledge of galaxy properties.
Efficient kernel surrogates for neural network-based regression
Oct 28, 2023



Despite their immense promise in performing a variety of learning tasks, a theoretical understanding of the effectiveness and limitations of Deep Neural Networks (DNNs) has so far eluded practitioners. This is partly due to the inability to determine the closed forms of the learned functions, making it harder to assess their precise dependence on the training data and to study their generalization properties on unseen datasets. Recent work has shown that randomly initialized DNNs in the infinite width limit converge to kernel machines relying on a Neural Tangent Kernel (NTK) with known closed form. These results suggest, and experimental evidence corroborates, that empirical kernel machines can also act as surrogates for finite width DNNs. The high computational cost of assembling the full NTK, however, makes this approach infeasible in practice, motivating the need for low-cost approximations. In the current work, we study the performance of the Conjugate Kernel (CK), an efficient approximation to the NTK that has been observed to yield fairly similar results. For the regression problem of smooth functions and classification using logistic regression, we show that the CK performance is only marginally worse than that of the NTK and, in certain cases, is shown to be superior. In particular, we establish bounds for the relative test losses, verify them with numerical tests, and identify the regularity of the kernel as the key determinant of performance. In addition to providing a theoretical grounding for using CKs instead of NTKs, our framework provides insights into understanding the robustness of the various approximants and suggests a recipe for improving DNN accuracy inexpensively. We present a demonstration of this on the foundation model GPT-2 by comparing its performance on a classification task using a conventional approach and our prescription.
Foundation Model's Embedded Representations May Detect Distribution Shift
Oct 20, 2023



Distribution shifts between train and test datasets obscure our ability to understand the generalization capacity of neural network models. This topic is especially relevant given the success of pre-trained foundation models as starting points for transfer learning (TL) models across tasks and contexts. We present a case study for TL on a pre-trained GPT-2 model onto the Sentiment140 dataset for sentiment classification. We show that Sentiment140's test dataset $M$ is not sampled from the same distribution as the training dataset $P$, and hence training on $P$ and measuring performance on $M$ does not actually account for the model's generalization on sentiment classification.
Exploring Learned Representations of Neural Networks with Principal Component Analysis
Sep 27, 2023


Understanding feature representation for deep neural networks (DNNs) remains an open question within the general field of explainable AI. We use principal component analysis (PCA) to study the performance of a k-nearest neighbors classifier (k-NN), nearest class-centers classifier (NCC), and support vector machines on the learned layer-wise representations of a ResNet-18 trained on CIFAR-10. We show that in certain layers, as little as 20% of the intermediate feature-space variance is necessary for high-accuracy classification and that across all layers, the first ~100 PCs completely determine the performance of the k-NN and NCC classifiers. We relate our findings to neural collapse and provide partial evidence for the related phenomenon of intermediate neural collapse. Our preliminary work provides three distinct yet interpretable surrogate models for feature representation with an affine linear model the best performing. We also show that leveraging several surrogate models affords us a clever method to estimate where neural collapse may initially occur within the DNN.
Robust Explanations for Deep Neural Networks via Pseudo Neural Tangent Kernel Surrogate Models
May 23, 2023
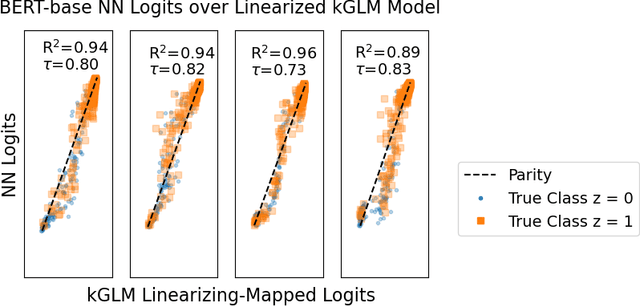
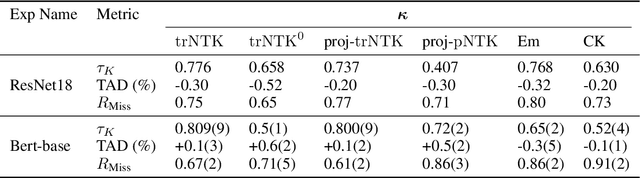
One of the ways recent progress has been made on explainable AI has been via explain-by-example strategies, specifically, through data attribution tasks. The feature spaces used to attribute decisions to training data, however, have not been compared against one another as to whether they form a truly representative surrogate model of the neural network (NN). Here, we demonstrate the efficacy of surrogate linear feature spaces to neural networks through two means: (1) we establish that a normalized psuedo neural tangent kernel (pNTK) is more correlated to the neural network decision functions than embedding based and influence based alternatives in both computer vision and large language model architectures; (2) we show that the attributions created from the normalized pNTK more accurately select perturbed training data in a data poisoning attribution task than these alternatives. Based on these observations, we conclude that kernel linear models are effective surrogate models across multiple classification architectures and that pNTK-based kernels are the most appropriate surrogate feature space of all kernels studied.
Spectral evolution and invariance in linear-width neural networks
Nov 11, 2022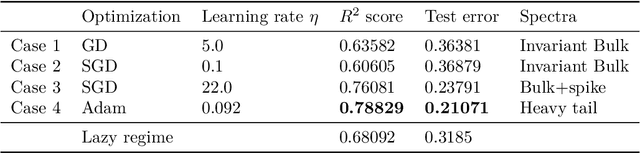



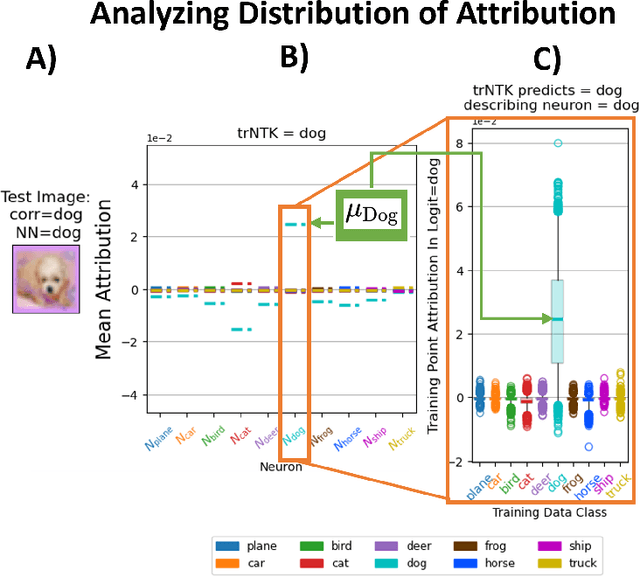
We investigate the spectral properties of linear-width feed-forward neural networks, where the sample size is asymptotically proportional to network width. Empirically, we show that the weight spectra in this high dimensional regime are invariant when trained by gradient descent for small constant learning rates and the changes in both operator and Frobenius norm are $\Theta(1)$ in the limit. This implies the bulk spectra for both the conjugate and neural tangent kernels are also invariant. We demonstrate similar characteristics for models trained with mini-batch (stochastic) gradient descent with small learning rates and provide a theoretical justification for this special scenario. When the learning rate is large, we show empirically that an outlier emerges with its corresponding eigenvector aligned to the training data structure. We also show that after adaptive gradient training, where we have a lower test error and feature learning emerges, both the weight and kernel matrices exhibit heavy tail behavior. Different spectral properties such as invariant bulk, spike, and heavy-tailed distribution correlate to how far the kernels deviate from initialization. To understand this phenomenon better, we focus on a toy model, a two-layer network on synthetic data, which exhibits different spectral properties for different training strategies. Analogous phenomena also appear when we train conventional neural networks with real-world data. Our results show that monitoring the evolution of the spectra during training is an important step toward understanding the training dynamics and feature learning.
TorchNTK: A Library for Calculation of Neural Tangent Kernels of PyTorch Models
May 24, 2022
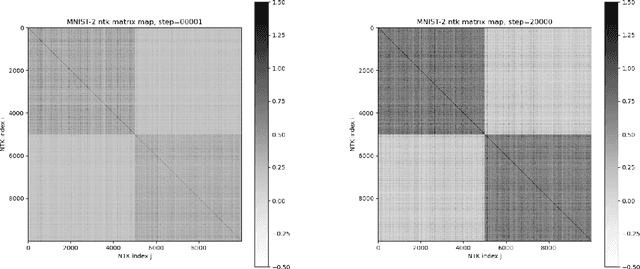
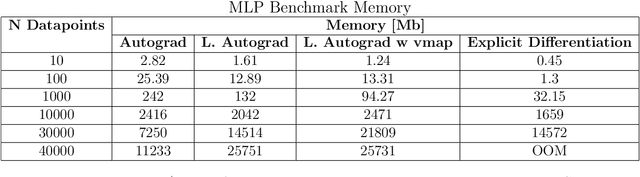
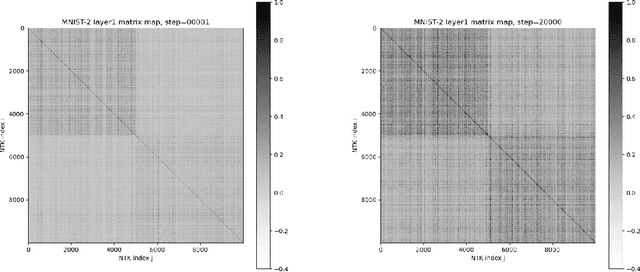
We introduce torchNTK, a python library to calculate the empirical neural tangent kernel (NTK) of neural network models in the PyTorch framework. We provide an efficient method to calculate the NTK of multilayer perceptrons. We compare the explicit differentiation implementation against autodifferentiation implementations, which have the benefit of extending the utility of the library to any architecture supported by PyTorch, such as convolutional networks. A feature of the library is that we expose the user to layerwise NTK components, and show that in some regimes a layerwise calculation is more memory efficient. We conduct preliminary experiments to demonstrate use cases for the software and probe the NTK.