 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Explanations for Deep Neural Networks via Pseudo Neural Tangent Kernel Surrogate Models
Paper and Code
May 23, 2023
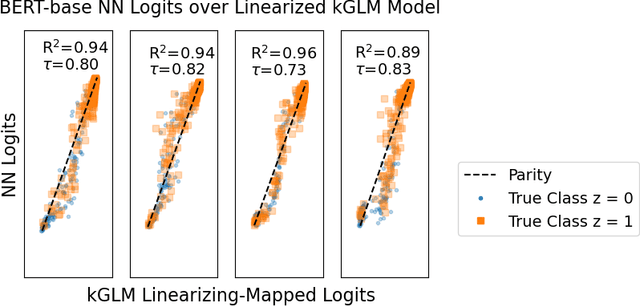
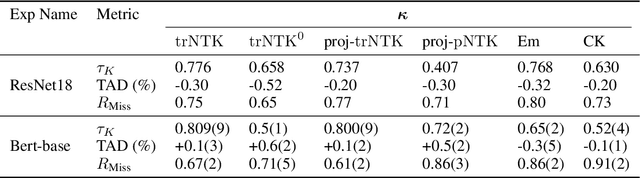
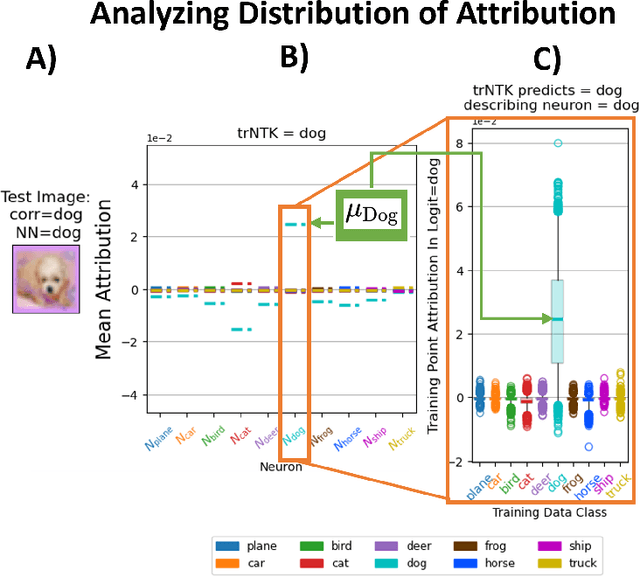
One of the ways recent progress has been made on explainable AI has been via explain-by-example strategies, specifically, through data attribution tasks. The feature spaces used to attribute decisions to training data, however, have not been compared against one another as to whether they form a truly representative surrogate model of the neural network (NN). Here, we demonstrate the efficacy of surrogate linear feature spaces to neural networks through two means: (1) we establish that a normalized psuedo neural tangent kernel (pNTK) is more correlated to the neural network decision functions than embedding based and influence based alternatives in both computer vision and large language model architectures; (2) we show that the attributions created from the normalized pNTK more accurately select perturbed training data in a data poisoning attribution task than these alternatives. Based on these observations, we conclude that kernel linear models are effective surrogate models across multiple classification architectures and that pNTK-based kernels are the most appropriate surrogate feature space of all kernels studied.