 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D for Free: Crossmodal Transfer Learning using HD Maps
Paper and Code
Aug 24, 2020
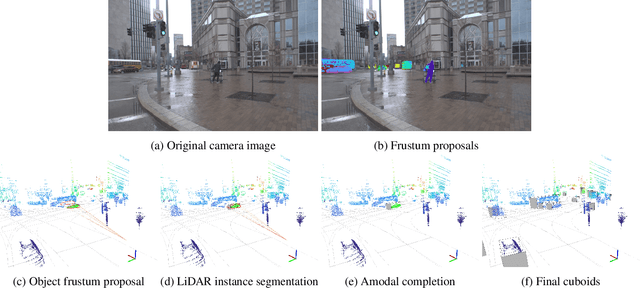


3D object detection is a core perceptual challenge for robotics and autonomous driving. However, the class-taxonomies in modern autonomous driving datasets are significantly smaller than many influential 2D detection datasets. In this work, we address the long-tail problem by leveraging both the large class-taxonomies of modern 2D datasets and the robustness of state-of-the-art 2D detection methods. We proceed to mine a large, unlabeled dataset of images and LiDAR, and estimate 3D object bounding cuboids, seeded from an off-the-shelf 2D instance segmentation model. Critically, we constrain this ill-posed 2D-to-3D mapping by using high-definition maps and object size priors. The result of the mining process is 3D cuboids with varying confidence. This mining process is itself a 3D object detector, although not especially accurate when evaluated as such. However, we then train a 3D object detection model on these cuboids, consistent with other recent observations in the deep learning literature, we find that the resulting model is fairly robust to the noisy supervision that our mining process provides. We mine a collection of 1151 unlabeled, multimodal driving logs from an autonomous vehicle and use the discovered objects to train a LiDAR-based object detector. We show that detector performance increases as we mine more unlabeled data. With our full, unlabeled dataset, our method performs competitively with fully supervised methods, even exceeding the performance for certain object categories, without any human 3D annotations.