 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Bounding Boxes Generation (ABBG) Attack against Visual Object Trackers
Nov 26, 2024



Adversarial perturbations aim to deceive neural networks into predicting inaccurate results. For visual object trackers, adversarial attacks have been developed to generate perturbations by manipulating the outputs. However, transformer trackers predict a specific bounding box instead of an object candidate list, which limits the applicability of many existing attack scenarios. To address this issue, we present a novel white-box approach to attack visual object trackers with transformer backbones using only one bounding box. From the tracker predicted bounding box, we generate a list of adversarial bounding boxes and compute the adversarial loss for those bounding boxes. Experimental results demonstrate that our simple yet effective attack outperforms existing attacks against several robust transformer trackers, including TransT-M, ROMTrack, and MixFormer, on popular benchmark tracking datasets such as GOT-10k, UAV123, and VOT2022STS.
A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis
Sep 17, 2024Relighting radiance fields is severely underconstrained for multi-view data, which is most often captured under a single illumination condition; It is especially hard for full scenes containing multiple objects. We introduce a method to create relightable radiance fields using such single-illumination data by exploiting priors extracted from 2D image diffusion models. We first fine-tune a 2D diffusion model on a multi-illumination dataset conditioned by light direction, allowing us to augment a single-illumination capture into a realistic -- but possibly inconsistent -- multi-illumination dataset from directly defined light directions. We use this augmented data to create a relightable radiance field represented by 3D Gaussian splats. To allow direct control of light direction for low-frequency lighting, we represent appearance with a multi-layer perceptron parameterized on light direction. To enforce multi-view consistency and overcome inaccuracies we optimize a per-image auxiliary feature vector. We show results on synthetic and real multi-view data under single illumination, demonstrating that our method successfully exploits 2D diffusion model priors to allow realistic 3D relighting for complete scenes. Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
* Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
TrackPGD: A White-box Attack using Binary Masks against Robust Transformer Trackers
Jul 04, 2024Object trackers with transformer backbones have achieved robust performance on visual object tracking datasets. However, the adversarial robustness of these trackers has not been well studied in the literature. Due to the backbone differences, the adversarial white-box attacks proposed for object tracking are not transferable to all types of trackers. For instance, transformer trackers such as MixFormerM still function well after black-box attacks, especially in predicting the object binary masks. We are proposing a novel white-box attack named TrackPGD, which relies on the predicted object binary mask to attack the robust transformer trackers. That new attack focuses on annotation masks by adapting the well-known SegPGD segmentation attack, allowing to successfully conduct the white-box attack on trackers relying on transformer backbones. The experimental results indicate that the TrackPGD is able to effectively attack transformer-based trackers such as MixFormerM, OSTrackSTS, and TransT-SEG on several tracking datasets.
DarSwin: Distortion Aware Radial Swin Transformer
Apr 19, 2023
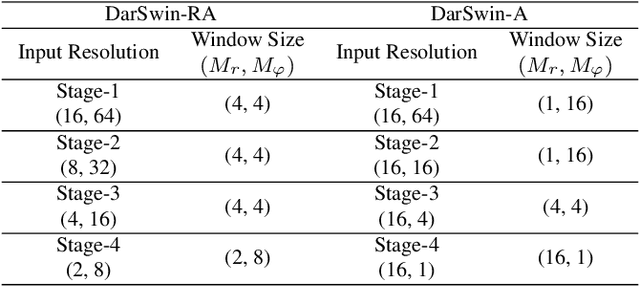

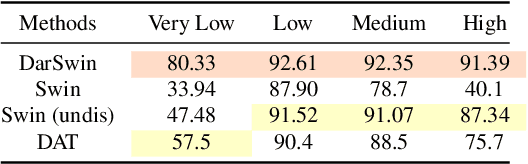
Wide-angle lenses are commonly used in perception tasks requiring a large field of view. Unfortunately, these lenses produce significant distortions making conventional models that ignore the distortion effects unable to adapt to wide-angle images. In this paper, we present a novel transformer-based model that automatically adapts to the distortion produced by wide-angle lenses. We leverage the physical characteristics of such lenses, which are analytically defined by the radial distortion profile (assumed to be known), to develop a distortion aware radial swin transformer (DarSwin). In contrast to conventional transformer-based architectures, DarSwin comprises a radial patch partitioning, a distortion-based sampling technique for creating token embeddings, and a polar position encoding for radial patch merging. We validate our method on classification tasks using synthetically distorted ImageNet data and show through extensive experiments that DarSwin can perform zero-shot adaptation to unseen distortions of different wide-angle lenses. Compared to other baselines, DarSwin achieves the best results (in terms of Top-1 and -5 accuracy), when tested on in-distribution data, with almost 2% (6%) gain in Top-1 accuracy under medium (high) distortion levels, and comparable to the state-of-the-art under low and very low distortion levels (perspective-like images).
AdaWCT: Adaptive Whitening and Coloring Style Injection
Aug 01, 2022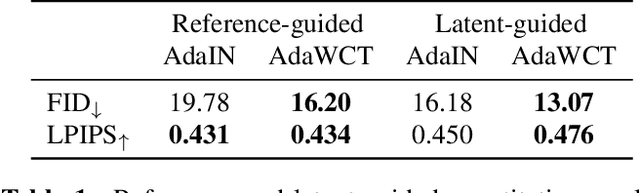

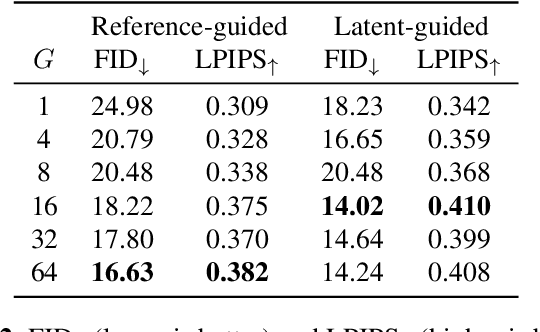

Adaptive instance normalization (AdaIN) has become the standard method for style injection: by re-normalizing features through scale-and-shift operations, it has found widespread use in style transfer, image generation, and image-to-image translation. In this work, we present a generalization of AdaIN which relies on the whitening and coloring transformation (WCT) which we dub AdaWCT, that we apply for style injection in large GANs. We show, through experiments on the StarGANv2 architecture, that this generalization, albeit conceptually simple, results in significant improvements in the quality of the generated images.
Domain Adaptation through Synthesis for Unsupervised Person Re-identification
Apr 26, 2018
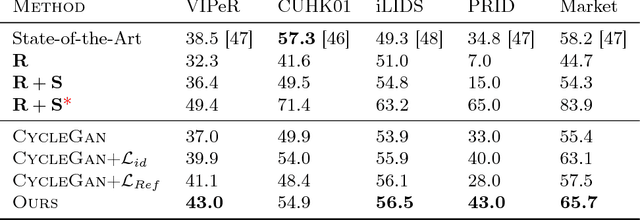

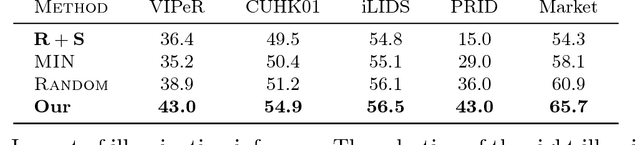
Drastic variations in illumination across surveillance cameras make the person re-identification problem extremely challenging. Current large scale re-identification datasets have a significant number of training subjects, but lack diversity in lighting conditions. As a result, a trained model requires fine-tuning to become effective under an unseen illumination condition. To alleviate this problem, we introduce a new synthetic dataset that contains hundreds of illumination conditions. Specifically, we use 100 virtual humans illuminated with multiple HDR environment maps which accurately model realistic indoor and outdoor lighting. To achieve better accuracy in unseen illumination conditions we propose a novel domain adaptation technique that takes advantage of our synthetic data and performs fine-tuning in a completely unsupervised way. Our approach yields significantly higher accuracy than semi-supervised and unsupervised state-of-the-art methods, and is very competitive with supervised techniques.