 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis
Sep 17, 2024Relighting radiance fields is severely underconstrained for multi-view data, which is most often captured under a single illumination condition; It is especially hard for full scenes containing multiple objects. We introduce a method to create relightable radiance fields using such single-illumination data by exploiting priors extracted from 2D image diffusion models. We first fine-tune a 2D diffusion model on a multi-illumination dataset conditioned by light direction, allowing us to augment a single-illumination capture into a realistic -- but possibly inconsistent -- multi-illumination dataset from directly defined light directions. We use this augmented data to create a relightable radiance field represented by 3D Gaussian splats. To allow direct control of light direction for low-frequency lighting, we represent appearance with a multi-layer perceptron parameterized on light direction. To enforce multi-view consistency and overcome inaccuracies we optimize a per-image auxiliary feature vector. We show results on synthetic and real multi-view data under single illumination, demonstrating that our method successfully exploits 2D diffusion model priors to allow realistic 3D relighting for complete scenes. Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
* Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
Robust Unsupervised StyleGAN Image Restoration
Feb 13, 2023GAN-based image restoration inverts the generative process to repair images corrupted by known degradations. Existing unsupervised methods must be carefully tuned for each task and degradation level. In this work, we make StyleGAN image restoration robust: a single set of hyperparameters works across a wide range of degradation levels. This makes it possible to handle combinations of several degradations, without the need to retune. Our proposed approach relies on a 3-phase progressive latent space extension and a conservative optimizer, which avoids the need for any additional regularization terms. Extensive experiments demonstrate robustness on inpainting, upsampling, denoising, and deartifacting at varying degradations levels, outperforming other StyleGAN-based inversion techniques. Our approach also favorably compares to diffusion-based restoration by yielding much more realistic inversion results. Code will be released upon publication.
AdaWCT: Adaptive Whitening and Coloring Style Injection
Aug 01, 2022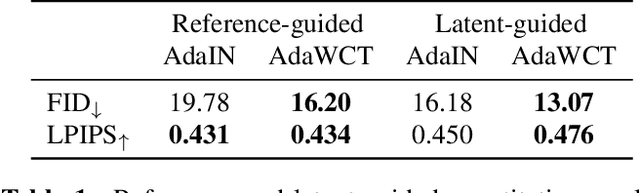

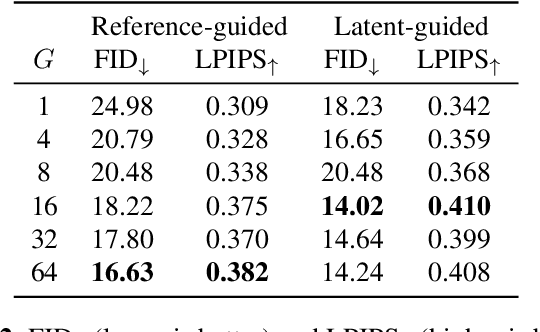

Adaptive instance normalization (AdaIN) has become the standard method for style injection: by re-normalizing features through scale-and-shift operations, it has found widespread use in style transfer, image generation, and image-to-image translation. In this work, we present a generalization of AdaIN which relies on the whitening and coloring transformation (WCT) which we dub AdaWCT, that we apply for style injection in large GANs. We show, through experiments on the StarGANv2 architecture, that this generalization, albeit conceptually simple, results in significant improvements in the quality of the generated images.
Overparameterization Improves StyleGAN Inversion
May 12, 2022
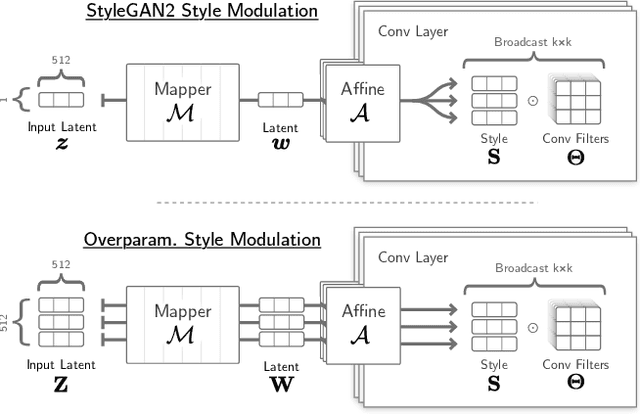

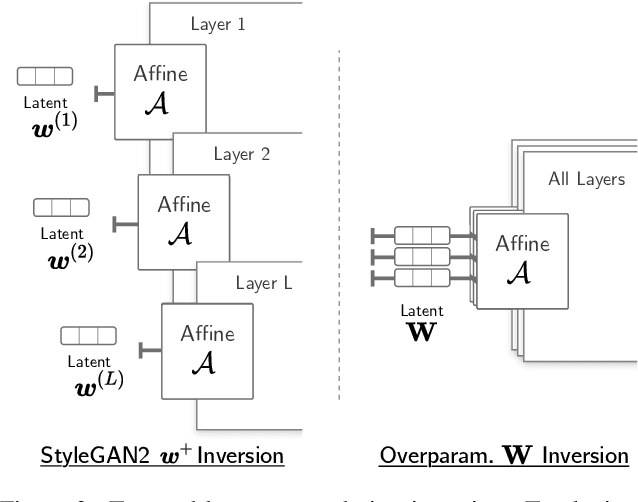
Deep generative models like StyleGAN hold the promise of semantic image editing: modifying images by their content, rather than their pixel values. Unfortunately, working with arbitrary images requires inverting the StyleGAN generator, which has remained challenging so far. Existing inversion approaches obtain promising yet imperfect results, having to trade-off between reconstruction quality and downstream editability. To improve quality, these approaches must resort to various techniques that extend the model latent space after training. Taking a step back, we observe that these methods essentially all propose, in one way or another, to increase the number of free parameters. This suggests that inversion might be difficult because it is underconstrained. In this work, we address this directly and dramatically overparameterize the latent space, before training, with simple changes to the original StyleGAN architecture. Our overparameterization increases the available degrees of freedom, which in turn facilitates inversion. We show that this allows us to obtain near-perfect image reconstruction without the need for encoders nor for altering the latent space after training. Our approach also retains editability, which we demonstrate by realistically interpolating between images.