 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Mental Averages
Mar 31, 2026Can a diffusion model produce its own "mental average" of a concept-one that is as sharp and realistic as a typical sample? We introduce Diffusion Mental Averages (DMA), a model-centric answer to this question. While prior methods aim to average image collections, they produce blurry results when applied to diffusion samples from the same prompt. These data-centric techniques operate outside the model, ignoring the generative process. In contrast, DMA averages within the diffusion model's semantic space, as discovered by recent studies. Since this space evolves across timesteps and lacks a direct decoder, we cast averaging as trajectory alignment: optimize multiple noise latents so their denoising trajectories progressively converge toward shared coarse-to-fine semantics, yielding a single sharp prototype. We extend our approach to multimodal concepts (e.g., dogs with many breeds) by clustering samples in semantically-rich spaces such as CLIP and applying Textual Inversion or LoRA to bridge CLIP clusters into diffusion space. This is, to our knowledge, the first approach that delivers consistent, realistic averages, even for abstract concepts, serving as a concrete visual summary and a lens into model biases and concept representation.
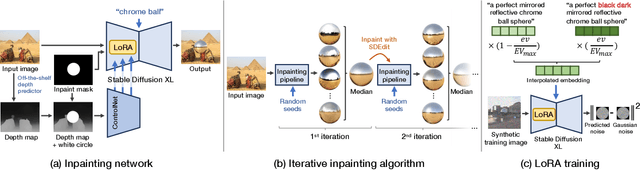
DiffusionLight-Turbo: Accelerated Light Probes for Free via Single-Pass Chrome Ball Inpainting
Jul 02, 2025We introduce a simple yet effective technique for estimating lighting from a single low-dynamic-range (LDR) image by reframing the task as a chrome ball inpainting problem. This approach leverages a pre-trained diffusion model, Stable Diffusion XL, to overcome the generalization failures of existing methods that rely on limited HDR panorama datasets. While conceptually simple, the task remains challenging because diffusion models often insert incorrect or inconsistent content and cannot readily generate chrome balls in HDR format. Our analysis reveals that the inpainting process is highly sensitive to the initial noise in the diffusion process, occasionally resulting in unrealistic outputs. To address this, we first introduce DiffusionLight, which uses iterative inpainting to compute a median chrome ball from multiple outputs to serve as a stable, low-frequency lighting prior that guides the generation of a high-quality final result. To generate high-dynamic-range (HDR) light probes, an Exposure LoRA is fine-tuned to create LDR images at multiple exposure values, which are then merged. While effective, DiffusionLight is time-intensive, requiring approximately 30 minutes per estimation. To reduce this overhead, we introduce DiffusionLight-Turbo, which reduces the runtime to about 30 seconds with minimal quality loss. This 60x speedup is achieved by training a Turbo LoRA to directly predict the averaged chrome balls from the iterative process. Inference is further streamlined into a single denoising pass using a LoRA swapping technique. Experimental results that show our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios. Our code is available at https://diffusionlight.github.io/turbo
Where Is The Ball: 3D Ball Trajectory Estimation From 2D Monocular Tracking
Jun 06, 2025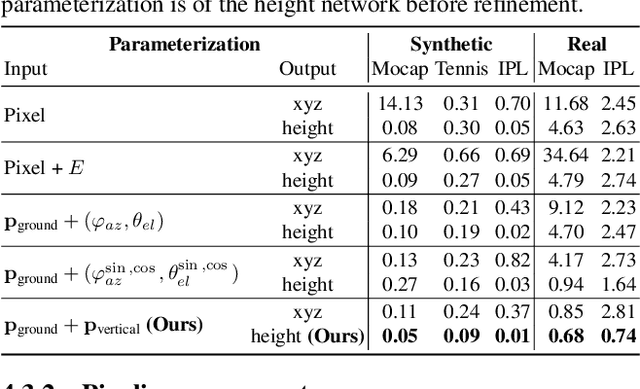
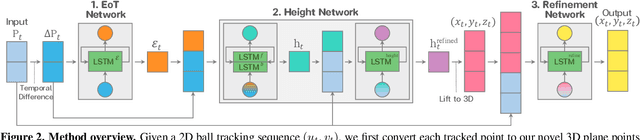
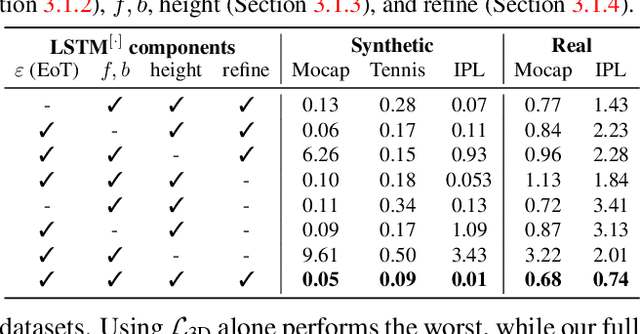
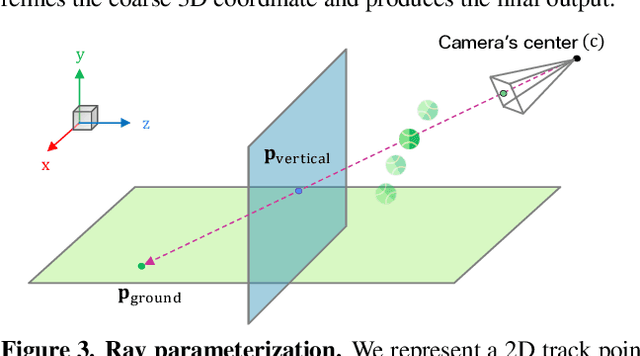
We present a method for 3D ball trajectory estimation from a 2D tracking sequence. To overcome the ambiguity in 3D from 2D estimation, we design an LSTM-based pipeline that utilizes a novel canonical 3D representation that is independent of the camera's location to handle arbitrary views and a series of intermediate representations that encourage crucial invariance and reprojection consistency. We evaluated our method on four synthetic and three real datasets and conducted extensive ablation studies on our design choices. Despite training solely on simulated data, our method achieves state-of-the-art performance and can generalize to real-world scenarios with multiple trajectories, opening up a range of applications in sport analysis and virtual replay. Please visit our page: https://where-is-the-ball.github.io.
Distilling Two-Timed Flow Models by Separately Matching Initial and Terminal Velocities
May 02, 2025



A flow matching model learns a time-dependent vector field $v_t(x)$ that generates a probability path $\{ p_t \}_{0 \leq t \leq 1}$ that interpolates between a well-known noise distribution ($p_0$) and the data distribution ($p_1$). It can be distilled into a \emph{two-timed flow model} (TTFM) $\phi_{s,x}(t)$ that can transform a sample belonging to the distribution at an initial time $s$ to another belonging to the distribution at a terminal time $t$ in one function evaluation. We present a new loss function for TTFM distillation called the \emph{initial/terminal velocity matching} (ITVM) loss that extends the Lagrangian Flow Map Distillation (LFMD) loss proposed by Boffi et al. by adding redundant terms to match the initial velocities at time $s$, removing the derivative from the terminal velocity term at time $t$, and using a version of the model under training, stabilized by exponential moving averaging (EMA), to compute the target terminal average velocity. Preliminary experiments show that our loss leads to better few-step generation performance on multiple types of datasets and model architectures over baselines.
Revisiting Diffusion Autoencoder Training for Image Reconstruction Quality
Apr 30, 2025Diffusion autoencoders (DAEs) are typically formulated as a noise prediction model and trained with a linear-$\beta$ noise schedule that spends much of its sampling steps at high noise levels. Because high noise levels are associated with recovering large-scale image structures and low noise levels with recovering details, this configuration can result in low-quality and blurry images. However, it should be possible to improve details while spending fewer steps recovering structures because the latent code should already contain structural information. Based on this insight, we propose a new DAE training method that improves the quality of reconstructed images. We divide training into two phases. In the first phase, the DAE is trained as a vanilla autoencoder by always setting the noise level to the highest, forcing the encoder and decoder to populate the latent code with structural information. In the second phase, we incorporate a noise schedule that spends more time in the low-noise region, allowing the DAE to learn how to perfect the details. Our method results in images that have accurate high-level structures and low-level details while still preserving useful properties of the latent codes.
LUSD: Localized Update Score Distillation for Text-Guided Image Editing
Mar 14, 2025While diffusion models show promising results in image editing given a target prompt, achieving both prompt fidelity and background preservation remains difficult. Recent works have introduced score distillation techniques that leverage the rich generative prior of text-to-image diffusion models to solve this task without additional fine-tuning. However, these methods often struggle with tasks such as object insertion. Our investigation of these failures reveals significant variations in gradient magnitude and spatial distribution, making hyperparameter tuning highly input-specific or unsuccessful. To address this, we propose two simple yet effective modifications: attention-based spatial regularization and gradient filtering-normalization, both aimed at reducing these variations during gradient updates. Experimental results show our method outperforms state-of-the-art score distillation techniques in prompt fidelity, improving successful edits while preserving the background. Users also preferred our method over state-of-the-art techniques across three metrics, and by 58-64% overall.
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Jan 01, 2024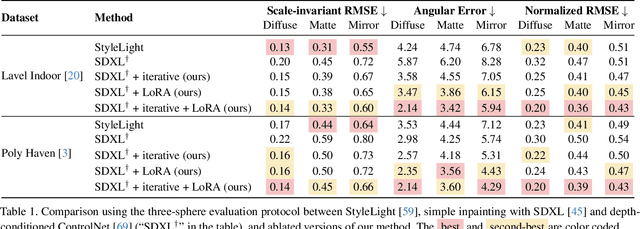

We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Dec 19, 2023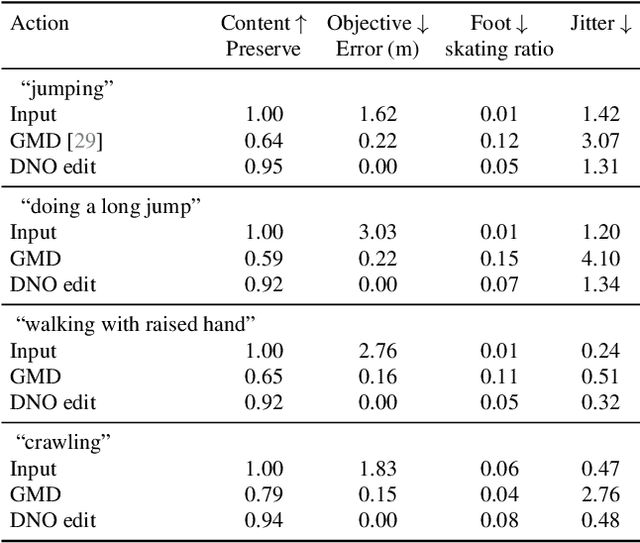
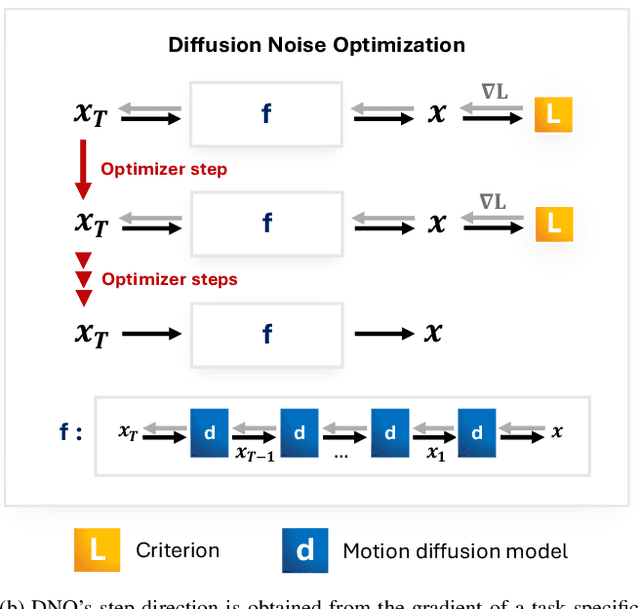
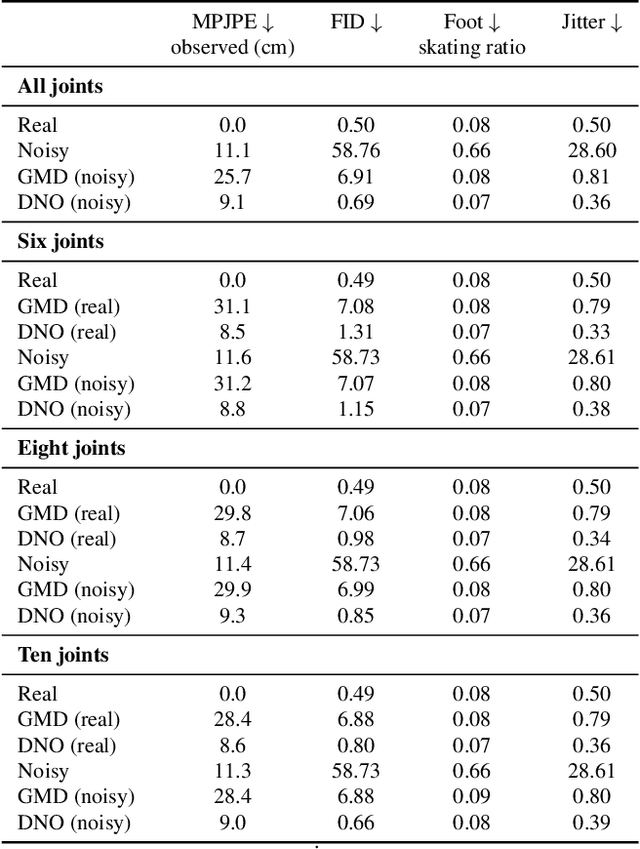

We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
Diffusion Sampling with Momentum for Mitigating Divergence Artifacts
Jul 20, 2023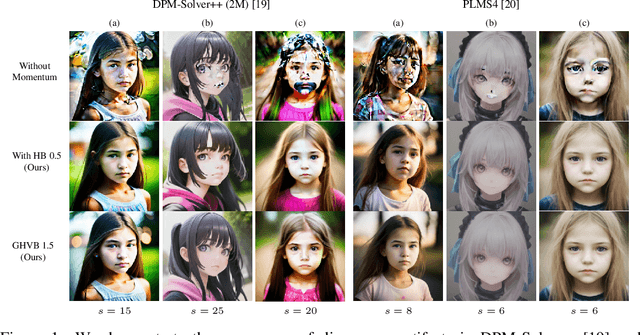
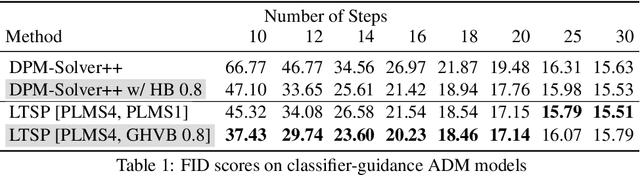
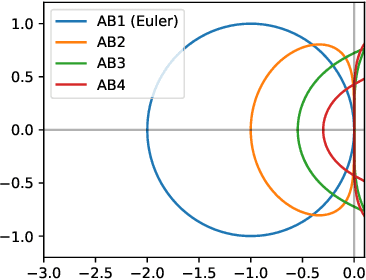
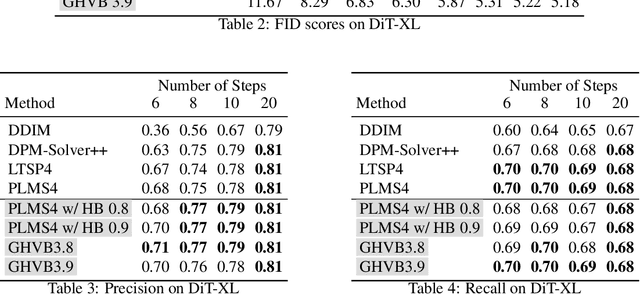
Despite the remarkable success of diffusion models in image generation, slow sampling remains a persistent issue. To accelerate the sampling process, prior studies have reformulated diffusion sampling as an ODE/SDE and introduced higher-order numerical methods. However, these methods often produce divergence artifacts, especially with a low number of sampling steps, which limits the achievable acceleration. In this paper, we investigate the potential causes of these artifacts and suggest that the small stability regions of these methods could be the principal cause. To address this issue, we propose two novel techniques. The first technique involves the incorporation of Heavy Ball (HB) momentum, a well-known technique for improving optimization, into existing diffusion numerical methods to expand their stability regions. We also prove that the resulting methods have first-order convergence. The second technique, called Generalized Heavy Ball (GHVB), constructs a new high-order method that offers a variable trade-off between accuracy and artifact suppression. Experimental results show that our techniques are highly effective in reducing artifacts and improving image quality, surpassing state-of-the-art diffusion solvers on both pixel-based and latent-based diffusion models for low-step sampling. Our research provides novel insights into the design of numerical methods for future diffusion work.
GMD: Controllable Human Motion Synthesis via Guided Diffusion Models
May 21, 2023



Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment. To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories. Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints. The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.