 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionLight-Turbo: Accelerated Light Probes for Free via Single-Pass Chrome Ball Inpainting
Jul 02, 2025We introduce a simple yet effective technique for estimating lighting from a single low-dynamic-range (LDR) image by reframing the task as a chrome ball inpainting problem. This approach leverages a pre-trained diffusion model, Stable Diffusion XL, to overcome the generalization failures of existing methods that rely on limited HDR panorama datasets. While conceptually simple, the task remains challenging because diffusion models often insert incorrect or inconsistent content and cannot readily generate chrome balls in HDR format. Our analysis reveals that the inpainting process is highly sensitive to the initial noise in the diffusion process, occasionally resulting in unrealistic outputs. To address this, we first introduce DiffusionLight, which uses iterative inpainting to compute a median chrome ball from multiple outputs to serve as a stable, low-frequency lighting prior that guides the generation of a high-quality final result. To generate high-dynamic-range (HDR) light probes, an Exposure LoRA is fine-tuned to create LDR images at multiple exposure values, which are then merged. While effective, DiffusionLight is time-intensive, requiring approximately 30 minutes per estimation. To reduce this overhead, we introduce DiffusionLight-Turbo, which reduces the runtime to about 30 seconds with minimal quality loss. This 60x speedup is achieved by training a Turbo LoRA to directly predict the averaged chrome balls from the iterative process. Inference is further streamlined into a single denoising pass using a LoRA swapping technique. Experimental results that show our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios. Our code is available at https://diffusionlight.github.io/turbo
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Jan 01, 2024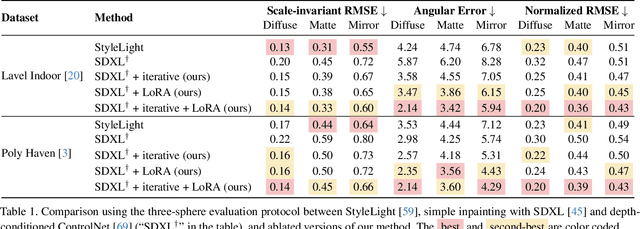

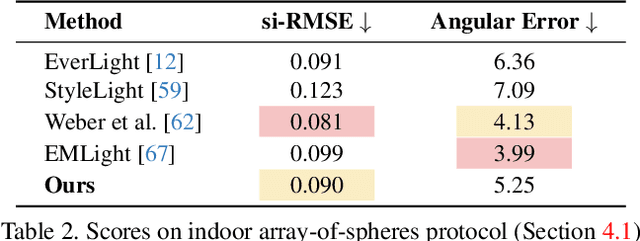
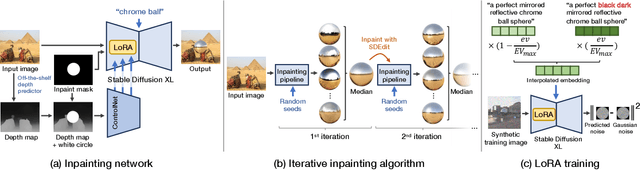
We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.
StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
Apr 05, 2023Our paper seeks to transfer the hairstyle of a reference image to an input photo for virtual hair try-on. We target a variety of challenges scenarios, such as transforming a long hairstyle with bangs to a pixie cut, which requires removing the existing hair and inferring how the forehead would look, or transferring partially visible hair from a hat-wearing person in a different pose. Past solutions leverage StyleGAN for hallucinating any missing parts and producing a seamless face-hair composite through so-called GAN inversion or projection. However, there remains a challenge in controlling the hallucinations to accurately transfer hairstyle and preserve the face shape and identity of the input. To overcome this, we propose a multi-view optimization framework that uses "two different views" of reference composites to semantically guide occluded or ambiguous regions. Our optimization shares information between two poses, which allows us to produce high fidelity and realistic results from incomplete references. Our framework produces high-quality results and outperforms prior work in a user study that consists of significantly more challenging hair transfer scenarios than previously studied. Project page: https://stylegan-salon.github.io/.
NeX: Real-time View Synthesis with Neural Basis Expansion
Mar 09, 2021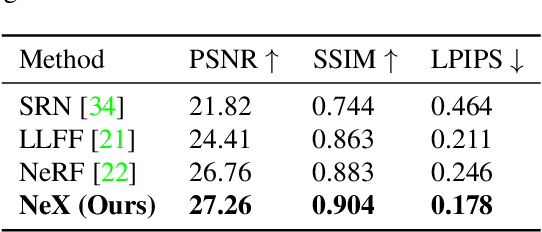
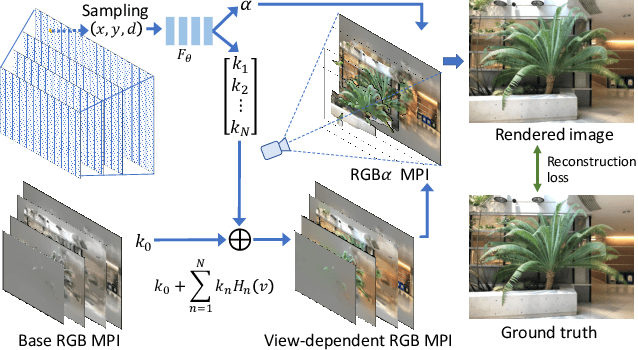


We present NeX, a new approach to novel view synthesis based on enhancements of multiplane image (MPI) that can reproduce next-level view-dependent effects -- in real time. Unlike traditional MPI that uses a set of simple RGB$\alpha$ planes, our technique models view-dependent effects by instead parameterizing each pixel as a linear combination of basis functions learned from a neural network. Moreover, we propose a hybrid implicit-explicit modeling strategy that improves upon fine detail and produces state-of-the-art results. Our method is evaluated on benchmark forward-facing datasets as well as our newly-introduced dataset designed to test the limit of view-dependent modeling with significantly more challenging effects such as rainbow reflections on a CD. Our method achieves the best overall scores across all major metrics on these datasets with more than 1000$\times$ faster rendering time than the state of the art. For real-time demos, visit https://nex-mpi.github.io/