 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Elimination in Hybrid Factor Graphs for Discrete-Continuous Inference & Estimation
Jan 02, 2026Many hybrid problems in robotics involve both continuous and discrete components, and modeling them together for estimation tasks has been a long standing and difficult problem. Hybrid Factor Graphs give us a mathematical framework to model these types of problems, however existing approaches for solving them are based on approximations. In this work, we propose an efficient Hybrid Factor Graph framework alongwith a variable elimination algorithm to produce a hybrid Bayes network, which can then be used for exact Maximum A Posteriori estimation and marginalization over both sets of variables. Our approach first develops a novel hybrid Gaussian factor which can connect to both discrete and continuous variables, and a hybrid conditional which can represent multiple continuous hypotheses conditioned on the discrete variables. Using these representations, we derive the process of hybrid variable elimination under the Conditional Linear Gaussian scheme, giving us exact posteriors as hybrid Bayes network. To bound the number of discrete hypotheses, we use a tree-structured representation of the factors coupled with a simple pruning and probabilistic assignment scheme, which allows for tractable inference. We demonstrate the applicability of our framework on a SLAM dataset with ambiguous measurements, where discrete choices for the most likely measurement have to be made. Our demonstrated results showcase the accuracy, generality, and simplicity of our hybrid factor graph framework.
A Group Theoretic Metric for Robot State Estimation Leveraging Chebyshev Interpolation
Jan 30, 2024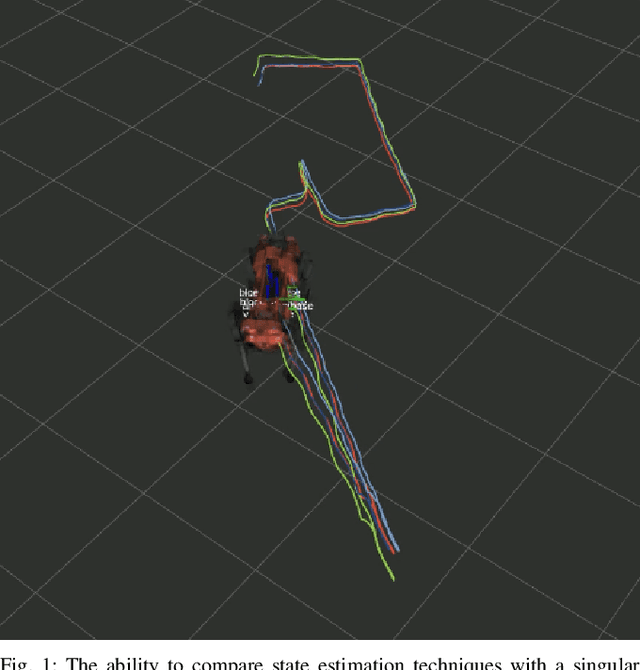
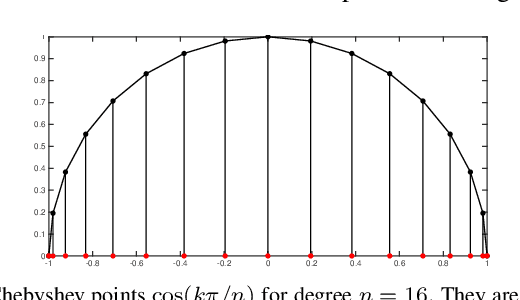
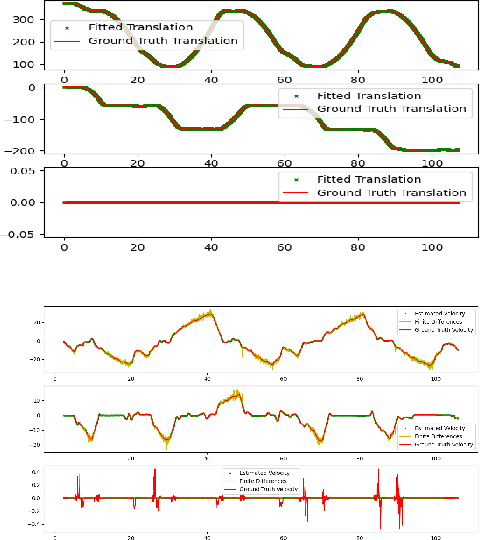
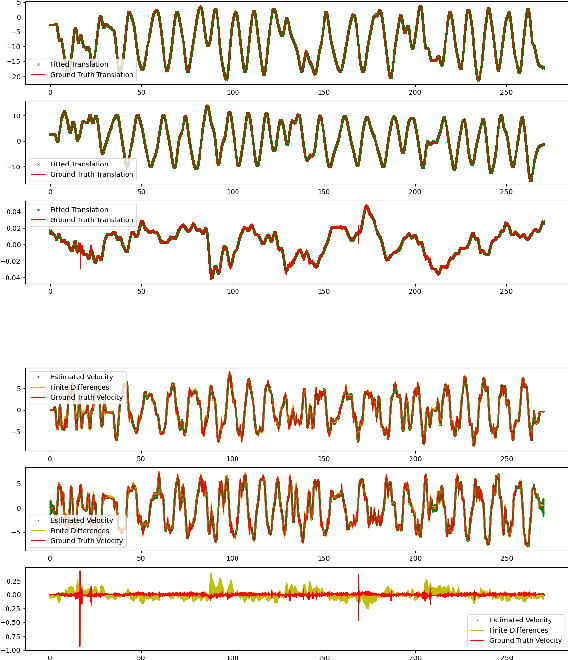
We propose a new metric for robot state estimation based on the recently introduced $\text{SE}_2(3)$ Lie group definition. Our metric is related to prior metrics for SLAM but explicitly takes into account the linear velocity of the state estimate, improving over current pose-based trajectory analysis. This has the benefit of providing a single, quantitative metric to evaluate state estimation algorithms against, while being compatible with existing tools and libraries. Since ground truth data generally consists of pose data from motion capture systems, we also propose an approach to compute the ground truth linear velocity based on polynomial interpolation. Using Chebyshev interpolation and a pseudospectral parameterization, we can accurately estimate the ground truth linear velocity of the trajectory in an optimal fashion with best approximation error. We demonstrate how this approach performs on multiple robotic platforms where accurate state estimation is vital, and compare it to alternative approaches such as finite differences. The pseudospectral parameterization also provides a means of trajectory data compression as an additional benefit. Experimental results show our method provides a valid and accurate means of comparing state estimation systems, which is also easy to interpret and report.
Deep IMU Bias Inference for Robust Visual-Inertial Odometry with Factor Graphs
Nov 08, 2022
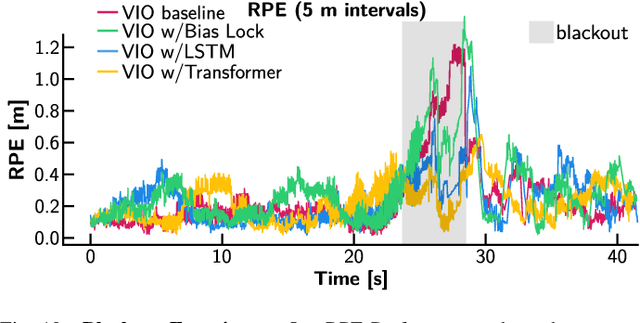
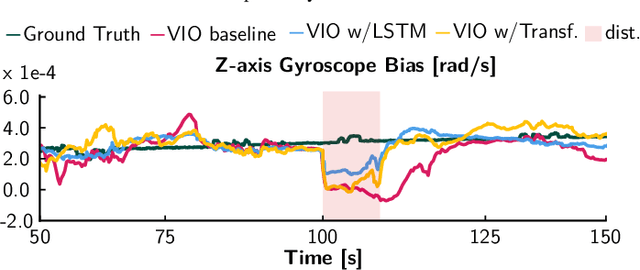
Visual Inertial Odometry (VIO) is one of the most established state estimation methods for mobile platforms. However, when visual tracking fails, VIO algorithms quickly diverge due to rapid error accumulation during inertial data integration. This error is typically modeled as a combination of additive Gaussian noise and a slowly changing bias which evolves as a random walk. In this work, we propose to train a neural network to learn the true bias evolution. We implement and compare two common sequential deep learning architectures: LSTMs and Transformers. Our approach follows from recent learning-based inertial estimators, but, instead of learning a motion model, we target IMU bias explicitly, which allows us to generalize to locomotion patterns unseen in training. We show that our proposed method improves state estimation in visually challenging situations across a wide range of motions by quadrupedal robots, walking humans, and drones. Our experiments show an average 15% reduction in drift rate, with much larger reductions when there is total vision failure. Importantly, we also demonstrate that models trained with one locomotion pattern (human walking) can be applied to another (quadruped robot trotting) without retraining.
Proprioceptive State Estimation of Legged Robots with Kinematic Chain Modeling
Sep 12, 2022



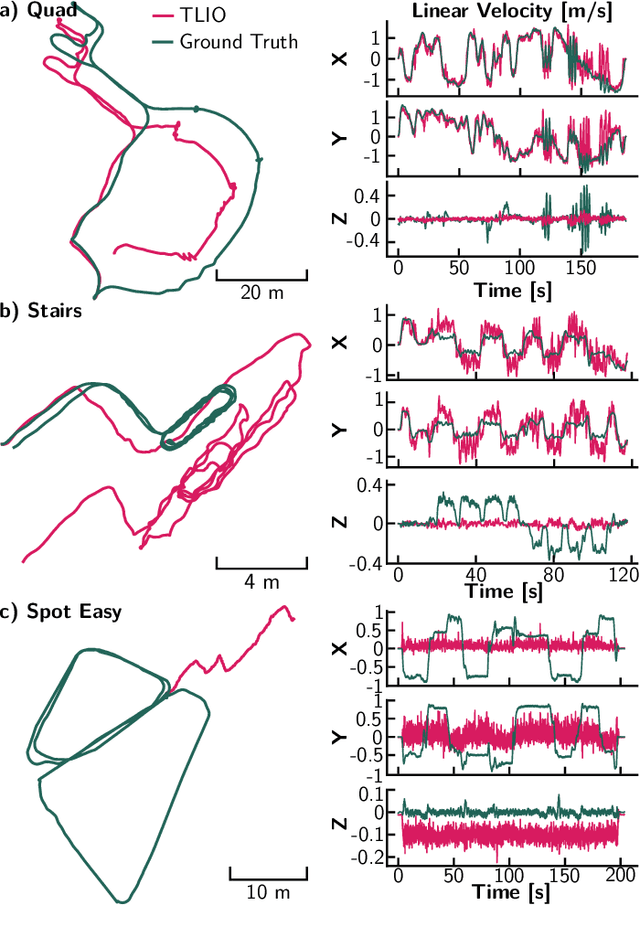
Legged robot locomotion is a challenging task due to a myriad of sub-problems, such as the hybrid dynamics of foot contact and the effects of the desired gait on the terrain. Accurate and efficient state estimation of the floating base and the feet joints can help alleviate much of these issues by providing feedback information to robot controllers. Current state estimation methods are highly reliant on a conjunction of visual and inertial measurements to provide real-time estimates, thus being handicapped in perceptually poor environments. In this work, we show that by leveraging the kinematic chain model of the robot via a factor graph formulation, we can perform state estimation of the base and the leg joints using primarily proprioceptive inertial data. We perform state estimation using a combination of preintegrated IMU measurements, forward kinematic computations, and contact detections in a factor-graph based framework, allowing our state estimate to be constrained by the robot model. Experimental results in simulation and on hardware show that our approach out-performs current proprioceptive state estimation methods by 27% on average, while being generalizable to a variety of legged robot platforms. We demonstrate our results both quantitatively and qualitatively on a wide variety of trajectories.
VideoPose: Estimating 6D object pose from videos
Nov 20, 2021
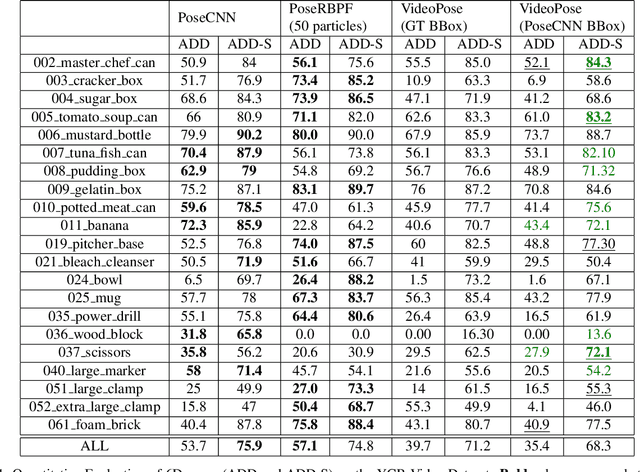
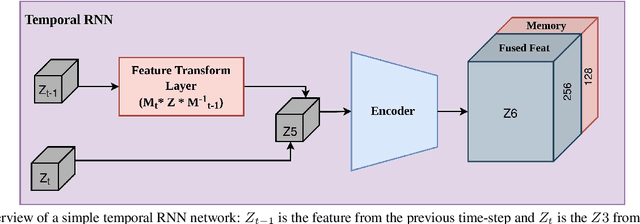
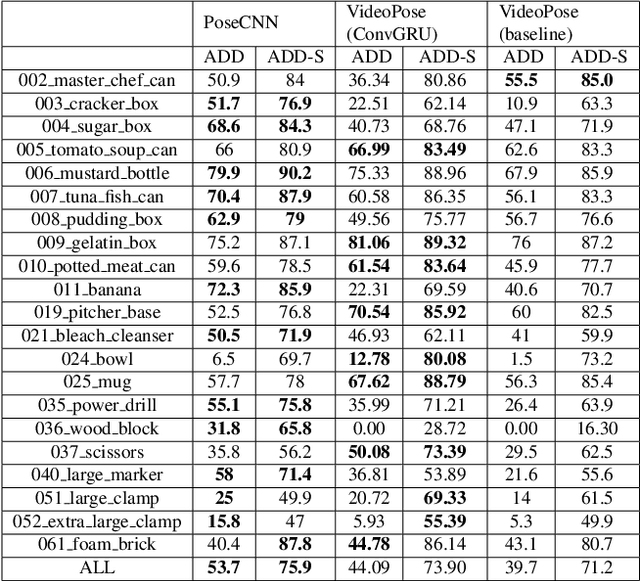
We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.
Continuous-time State & Dynamics Estimation using a Pseudo-Spectral Parameterization
Mar 26, 2021



We present a novel continuous time trajectory representation based on a Chebyshev polynomial basis, which when governed by known dynamics models, allows for full trajectory and robot dynamics estimation, particularly useful for high-performance robotics applications such as unmanned aerial vehicles. We show that we can gracefully incorporate model dynamics to our trajectory representation, within a factor-graph based framework, and leverage ideas from pseudo-spectral optimal control to parameterize the state and the control trajectories as interpolating polynomials. This allows us to perform efficient optimization at specifically chosen points derived from the theory, while recovering full trajectory estimates. Through simulated experiments we demonstrate the applicability of our representation for accurate flight dynamics estimation for multirotor aerial vehicles. The representation framework is general and can thus be applied to a multitude of high-performance applications beyond multirotor platforms.
iMHS: An Incremental Multi-Hypothesis Smoother
Mar 24, 2021

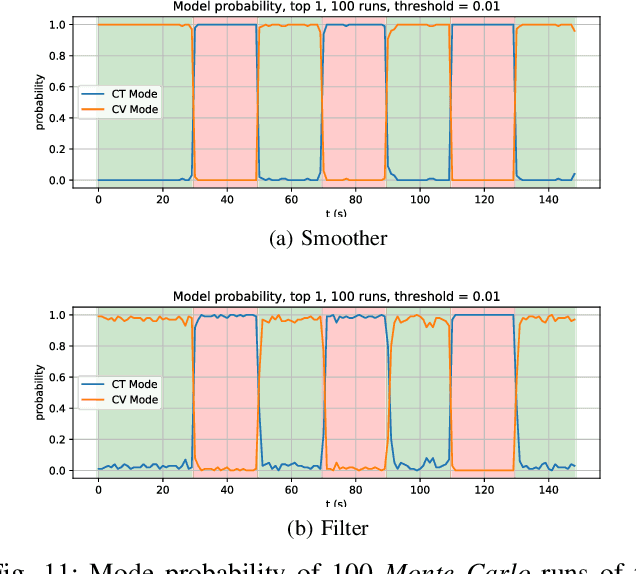

State estimation of multi-modal hybrid systems is an important problem with many applications in the field robotics. However, incorporating discrete modes in the estimation process is hampered by a potentially combinatorial growth in computation. In this paper we present a novel incremental multi-hypothesis smoother based on eliminating a hybrid factor graph into a multi-hypothesis Bayes tree, which represents possible discrete state sequence hypotheses. Following iSAM, we enable incremental inference by conditioning the past on the future but we add to that the capability of maintaining multiple discrete mode histories, exploiting the temporal structure of the problem to obtain a simplified representation that unifies the multiple hypothesis tree with the Bayes tree. In the results section we demonstrate the generality of the algorithm with examples in three problem domains: lane change detection (1D), aircraft maneuver detection (2D), and contact detection in legged robots (3D).
Unbiasing Semantic Segmentation For Robot Perception using Synthetic Data Feature Transfer
Sep 11, 2018



Robot perception systems need to perform reliable image segmentation in real-time on noisy, raw perception data. State-of-the-art segmentation approaches use large CNN models and carefully constructed datasets; however, these models focus on accuracy at the cost of real-time inference. Furthermore, the standard semantic segmentation datasets are not large enough for training CNNs without augmentation and are not representative of noisy, uncurated robot perception data. We propose improving the performance of real-time segmentation frameworks on robot perception data by transferring features learned from synthetic segmentation data. We show that pretraining real-time segmentation architectures with synthetic segmentation data instead of ImageNet improves fine-tuning performance by reducing the bias learned in pretraining and closing the \textit{transfer gap} as a result. Our experiments show that our real-time robot perception models pretrained on synthetic data outperform those pretrained on ImageNet for every scale of fine-tuning data examined. Moreover, the degree to which synthetic pretraining outperforms ImageNet pretraining increases as the availability of robot data decreases, making our approach attractive for robotics domains where dataset collection is hard and/or expensive.
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
Apr 14, 2018



In this paper, we investigate deep image synthesis guided by sketch, color, and texture. Previous image synthesis methods can be controlled by sketch and color strokes but we are the first to examine texture control. We allow a user to place a texture patch on a sketch at arbitrary locations and scales to control the desired output texture. Our generative network learns to synthesize objects consistent with these texture suggestions. To achieve this, we develop a local texture loss in addition to adversarial and content loss to train the generative network. We conduct experiments using sketches generated from real images and textures sampled from a separate texture database and results show that our proposed algorithm is able to generate plausible images that are faithful to user controls. Ablation studies show that our proposed pipeline can generate more realistic images than adapting existing methods directly.