 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPose: Estimating 6D object pose from videos
Paper and Code
Nov 20, 2021
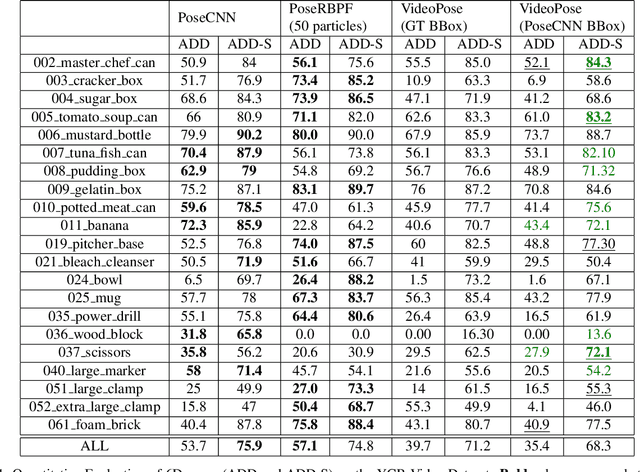
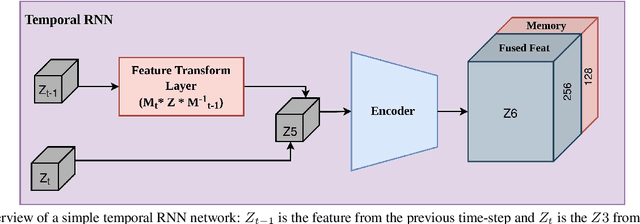
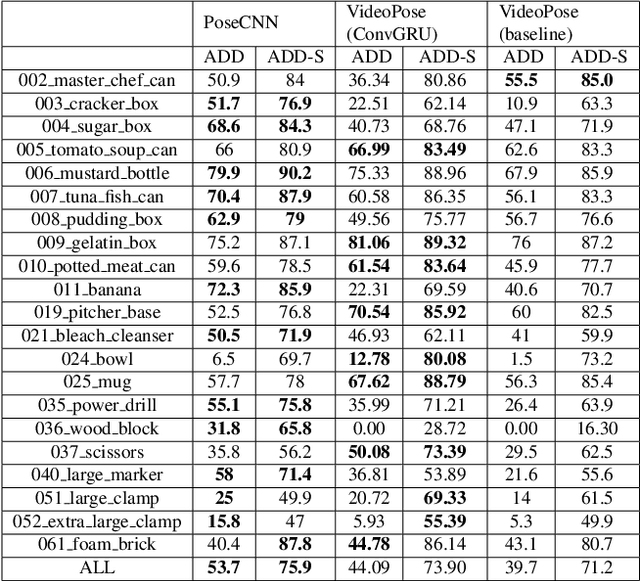
We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.