 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierSum: A Global and Local Attention Mechanism for Video Summarization
Apr 25, 2025
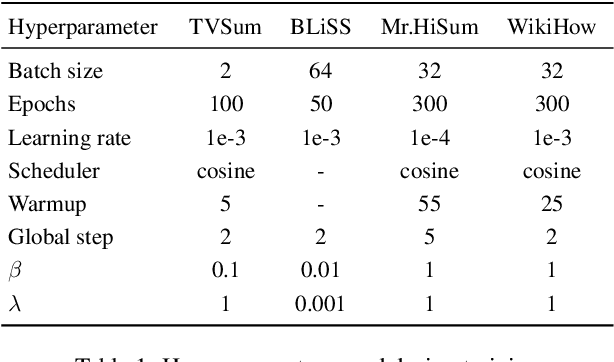
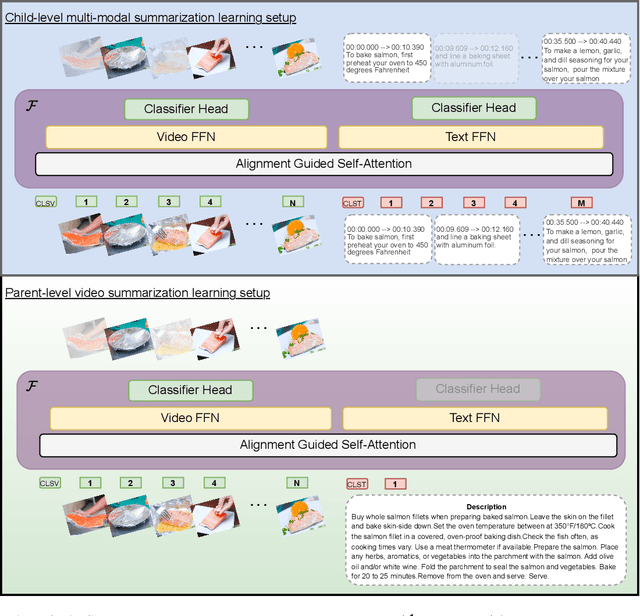
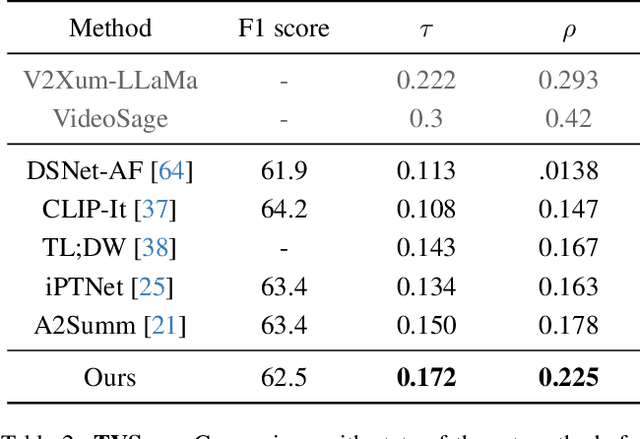
Video summarization creates an abridged version (i.e., a summary) that provides a quick overview of the video while retaining pertinent information. In this work, we focus on summarizing instructional videos and propose a method for breaking down a video into meaningful segments, each corresponding to essential steps in the video. We propose \textbf{HierSum}, a hierarchical approach that integrates fine-grained local cues from subtitles with global contextual information provided by video-level instructions. Our approach utilizes the ``most replayed" statistic as a supervisory signal to identify critical segments, thereby improving the effectiveness of the summary. We evaluate on benchmark datasets such as TVSum, BLiSS, Mr.HiSum, and the WikiHow test set, and show that HierSum consistently outperforms existing methods in key metrics such as F1-score and rank correlation. We also curate a new multi-modal dataset using WikiHow and EHow videos and associated articles containing step-by-step instructions. Through extensive ablation studies, we demonstrate that training on this dataset significantly enhances summarization on the target datasets.
Exploring Efficient Foundational Multi-modal Models for Video Summarization
Oct 09, 2024Foundational models are able to generate text outputs given prompt instructions and text, audio, or image inputs. Recently these models have been combined to perform tasks on video, such as video summarization. Such video foundation models perform pre-training by aligning outputs from each modality-specific model into the same embedding space. Then the embeddings from each model are used within a language model, which is fine-tuned on a desired instruction set. Aligning each modality during pre-training is computationally expensive and prevents rapid testing of different base modality models. During fine-tuning, evaluation is carried out within in-domain videos where it is hard to understand the generalizability and data efficiency of these methods. To alleviate these issues we propose a plug-and-play video language model. It directly uses the texts generated from each input modality into the language model, avoiding pre-training alignment overhead. Instead of fine-tuning we leverage few-shot instruction adaptation strategies. We compare the performance versus the computational costs for our plug-and-play style method and baseline tuning methods. Finally, we explore the generalizability of each method during domain shift and present insights on what data is useful when training data is limited. Through this analysis, we present practical insights on how to leverage multi-modal foundational models for effective results given realistic compute and data limitations.
Mamba Fusion: Learning Actions Through Questioning
Sep 17, 2024



Video Language Models (VLMs) are crucial for generalizing across diverse tasks and using language cues to enhance learning. While transformer-based architectures have been the de facto in vision-language training, they face challenges like quadratic computational complexity, high GPU memory usage, and difficulty with long-term dependencies. To address these limitations, we introduce MambaVL, a novel model that leverages recent advancements in selective state space modality fusion to efficiently capture long-range dependencies and learn joint representations for vision and language data. MambaVL utilizes a shared state transition matrix across both modalities, allowing the model to capture information about actions from multiple perspectives within the scene. Furthermore, we propose a question-answering task that helps guide the model toward relevant cues. These questions provide critical information about actions, objects, and environmental context, leading to enhanced performance. As a result, MambaVL achieves state-of-the-art performance in action recognition on the Epic-Kitchens-100 dataset and outperforms baseline methods in action anticipation.
Limitations in Employing Natural Language Supervision for Sensor-Based Human Activity Recognition -- And Ways to Overcome Them
Aug 21, 2024Cross-modal contrastive pre-training between natural language and other modalities, e.g., vision and audio, has demonstrated astonishing performance and effectiveness across a diverse variety of tasks and domains. In this paper, we investigate whether such natural language supervision can be used for wearable sensor based Human Activity Recognition (HAR), and discover that-surprisingly-it performs substantially worse than standard end-to-end training and self-supervision. We identify the primary causes for this as: sensor heterogeneity and the lack of rich, diverse text descriptions of activities. To mitigate their impact, we also develop strategies and assess their effectiveness through an extensive experimental evaluation. These strategies lead to significant increases in activity recognition, bringing performance closer to supervised and self-supervised training, while also enabling the recognition of unseen activities and cross modal retrieval of videos. Overall, our work paves the way for better sensor-language learning, ultimately leading to the development of foundational models for HAR using wearables.
On the Efficacy of Text-Based Input Modalities for Action Anticipation
Jan 23, 2024Although the task of anticipating future actions is highly uncertain, information from additional modalities help to narrow down plausible action choices. Each modality provides different environmental context for the model to learn from. While previous multi-modal methods leverage information from modalities such as video and audio, we primarily explore how text inputs for actions and objects can also enable more accurate action anticipation. Therefore, we propose a Multi-modal Anticipative Transformer (MAT), an attention-based video transformer architecture that jointly learns from multi-modal features and text captions. We train our model in two-stages, where the model first learns to predict actions in the video clip by aligning with captions, and during the second stage, we fine-tune the model to predict future actions. Compared to existing methods, MAT has the advantage of learning additional environmental context from two kinds of text inputs: action descriptions during the pre-training stage, and the text inputs for detected objects and actions during modality feature fusion. Through extensive experiments, we evaluate the effectiveness of the pre-training stage, and show that our model outperforms previous methods on all datasets. In addition, we examine the impact of object and action information obtained via text and perform extensive ablations. We evaluate the performance on on three datasets: EpicKitchens-100, EpicKitchens-55 and EGTEA GAZE+; and show that text descriptions do indeed aid in more effective action anticipation.
Multimodal Contrastive Learning with Hard Negative Sampling for Human Activity Recognition
Sep 03, 2023



Human Activity Recognition (HAR) systems have been extensively studied by the vision and ubiquitous computing communities due to their practical applications in daily life, such as smart homes, surveillance, and health monitoring. Typically, this process is supervised in nature and the development of such systems requires access to large quantities of annotated data. However, the higher costs and challenges associated with obtaining good quality annotations have rendered the application of self-supervised methods an attractive option and contrastive learning comprises one such method. However, a major component of successful contrastive learning is the selection of good positive and negative samples. Although positive samples are directly obtainable, sampling good negative samples remain a challenge. As human activities can be recorded by several modalities like camera and IMU sensors, we propose a hard negative sampling method for multimodal HAR with a hard negative sampling loss for skeleton and IMU data pairs. We exploit hard negatives that have different labels from the anchor but are projected nearby in the latent space using an adjustable concentration parameter. Through extensive experiments on two benchmark datasets: UTD-MHAD and MMAct, we demonstrate the robustness of our approach forlearning strong feature representation for HAR tasks, and on the limited data setting. We further show that our model outperforms all other state-of-the-art methods for UTD-MHAD dataset, and self-supervised methods for MMAct: Cross session, even when uni-modal data are used during downstream activity recognition.
Multi-Stage Based Feature Fusion of Multi-Modal Data for Human Activity Recognition
Nov 08, 2022To properly assist humans in their needs, human activity recognition (HAR) systems need the ability to fuse information from multiple modalities. Our hypothesis is that multimodal sensors, visual and non-visual tend to provide complementary information, addressing the limitations of other modalities. In this work, we propose a multi-modal framework that learns to effectively combine features from RGB Video and IMU sensors, and show its robustness for MMAct and UTD-MHAD datasets. Our model is trained in two-stage, where in the first stage, each input encoder learns to effectively extract features, and in the second stage, learns to combine these individual features. We show significant improvements of 22% and 11% compared to video only and IMU only setup on UTD-MHAD dataset, and 20% and 12% on MMAct datasets. Through extensive experimentation, we show the robustness of our model on zero shot setting, and limited annotated data setting. We further compare with state-of-the-art methods that use more input modalities and show that our method outperforms significantly on the more difficult MMact dataset, and performs comparably in UTD-MHAD dataset.
Video based Object 6D Pose Estimation using Transformers
Nov 07, 2022We introduce a Transformer based 6D Object Pose Estimation framework VideoPose, comprising an end-to-end attention based modelling architecture, that attends to previous frames in order to estimate accurate 6D Object Poses in videos. Our approach leverages the temporal information from a video sequence for pose refinement, along with being computationally efficient and robust. Compared to existing methods, our architecture is able to capture and reason from long-range dependencies efficiently, thus iteratively refining over video sequences. Experimental evaluation on the YCB-Video dataset shows that our approach is on par with the state-of-the-art Transformer methods, and performs significantly better relative to CNN based approaches. Further, with a speed of 33 fps, it is also more efficient and therefore applicable to a variety of applications that require real-time object pose estimation. Training code and pretrained models are available at https://github.com/ApoorvaBeedu/VideoPose
End-to-End Multimodal Representation Learning for Video Dialog
Oct 26, 2022

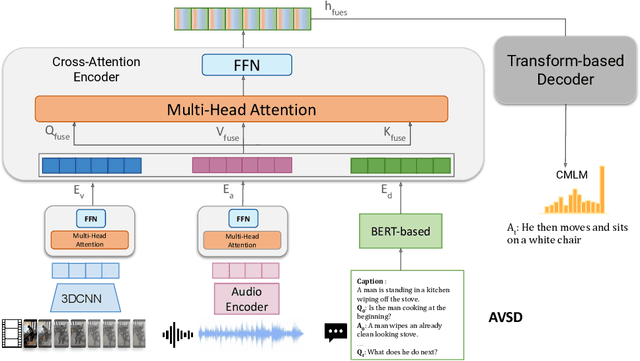

Video-based dialog task is a challenging multimodal learning task that has received increasing attention over the past few years with state-of-the-art obtaining new performance records. This progress is largely powered by the adaptation of the more powerful transformer-based language encoders. Despite this progress, existing approaches do not effectively utilize visual features to help solve tasks. Recent studies show that state-of-the-art models are biased toward textual information rather than visual cues. In order to better leverage the available visual information, this study proposes a new framework that combines 3D-CNN network and transformer-based networks into a single visual encoder to extract more robust semantic representations from videos. The visual encoder is jointly trained end-to-end with other input modalities such as text and audio. Experiments on the AVSD task show significant improvement over baselines in both generative and retrieval tasks.
VideoPose: Estimating 6D object pose from videos
Nov 20, 2021
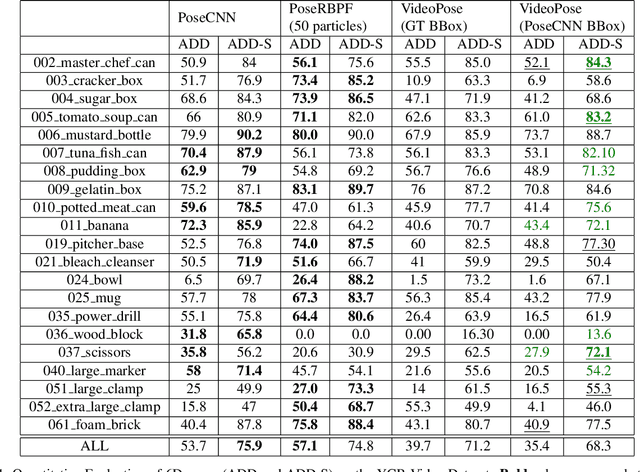
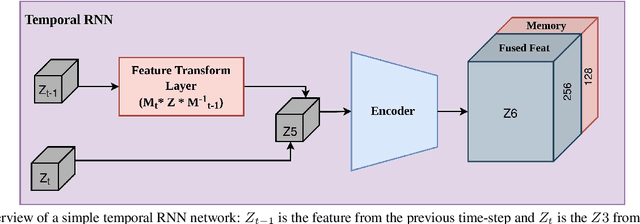
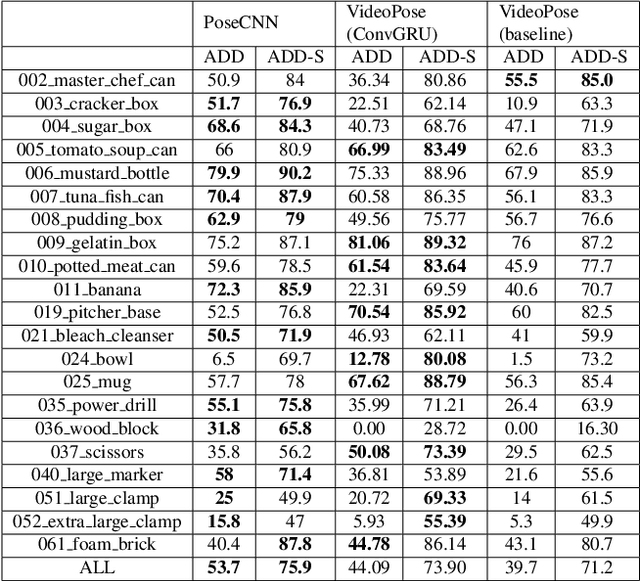
We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.