 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo based Object 6D Pose Estimation using Transformers
Nov 07, 2022We introduce a Transformer based 6D Object Pose Estimation framework VideoPose, comprising an end-to-end attention based modelling architecture, that attends to previous frames in order to estimate accurate 6D Object Poses in videos. Our approach leverages the temporal information from a video sequence for pose refinement, along with being computationally efficient and robust. Compared to existing methods, our architecture is able to capture and reason from long-range dependencies efficiently, thus iteratively refining over video sequences. Experimental evaluation on the YCB-Video dataset shows that our approach is on par with the state-of-the-art Transformer methods, and performs significantly better relative to CNN based approaches. Further, with a speed of 33 fps, it is also more efficient and therefore applicable to a variety of applications that require real-time object pose estimation. Training code and pretrained models are available at https://github.com/ApoorvaBeedu/VideoPose
End-to-End Multimodal Representation Learning for Video Dialog
Oct 26, 2022

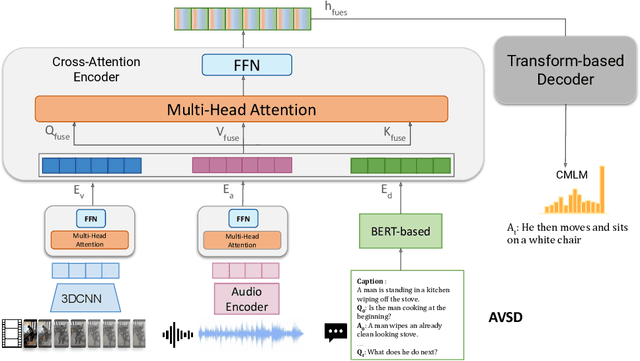

Video-based dialog task is a challenging multimodal learning task that has received increasing attention over the past few years with state-of-the-art obtaining new performance records. This progress is largely powered by the adaptation of the more powerful transformer-based language encoders. Despite this progress, existing approaches do not effectively utilize visual features to help solve tasks. Recent studies show that state-of-the-art models are biased toward textual information rather than visual cues. In order to better leverage the available visual information, this study proposes a new framework that combines 3D-CNN network and transformer-based networks into a single visual encoder to extract more robust semantic representations from videos. The visual encoder is jointly trained end-to-end with other input modalities such as text and audio. Experiments on the AVSD task show significant improvement over baselines in both generative and retrieval tasks.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019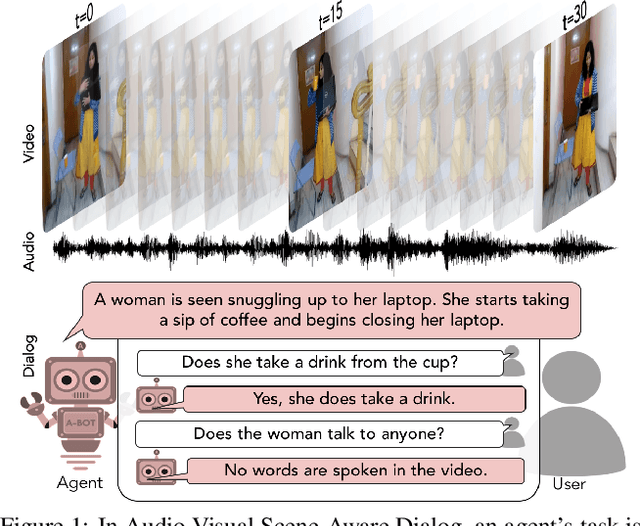
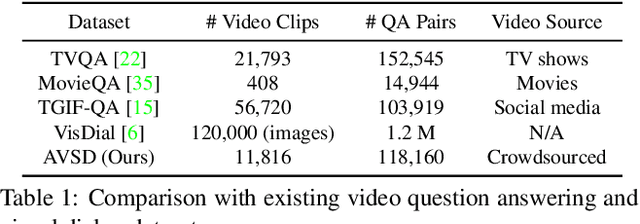


We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
End-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Jun 30, 2018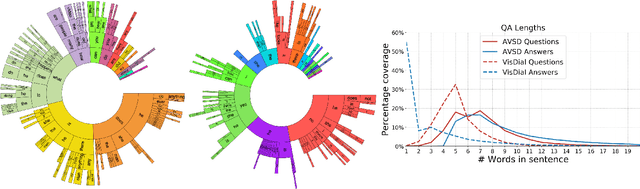
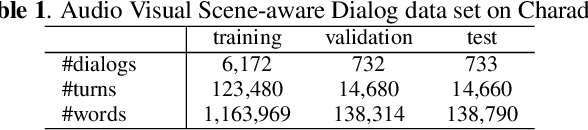
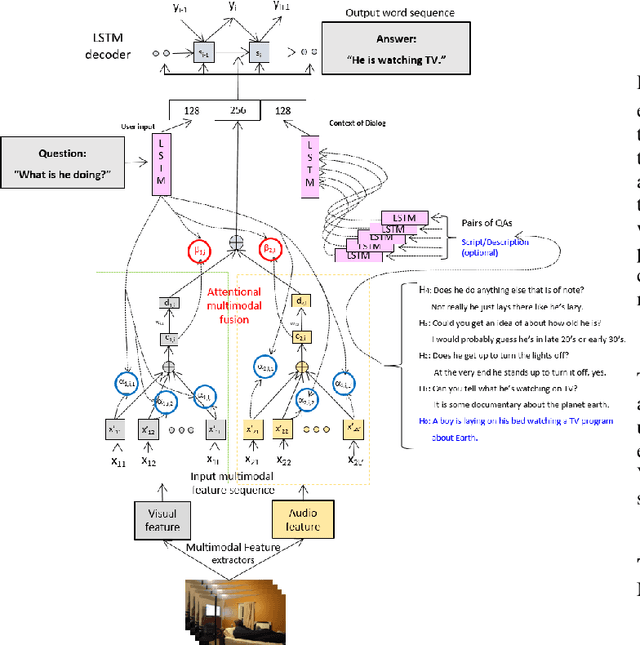
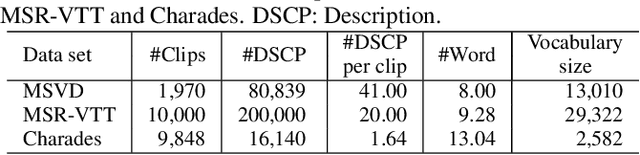
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.
Audio Visual Scene-Aware Dialog Challenge at DSTC7
Jun 01, 2018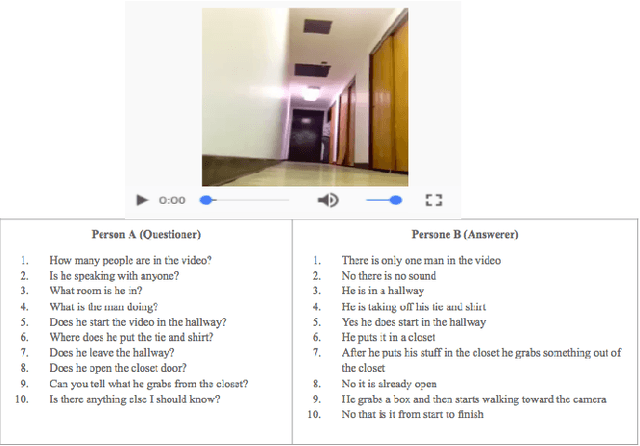
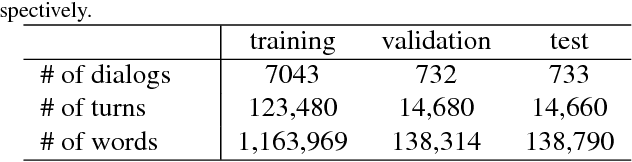
Scene-aware dialog systems will be able to have conversations with users about the objects and events around them. Progress on such systems can be made by integrating state-of-the-art technologies from multiple research areas including end-to-end dialog systems visual dialog, and video description. We introduce the Audio Visual Scene Aware Dialog (AVSD) challenge and dataset. In this challenge, which is one track of the 7th Dialog System Technology Challenges (DSTC7) workshop1, the task is to build a system that generates responses in a dialog about an input video