 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBC-MRI-SEG: A Breast Cancer MRI Tumor Segmentation Benchmark
Apr 21, 2024



Binary breast cancer tumor segmentation with Magnetic Resonance Imaging (MRI) data is typically trained and evaluated on private medical data, which makes comparing deep learning approaches difficult. We propose a benchmark (BC-MRI-SEG) for binary breast cancer tumor segmentation based on publicly available MRI datasets. The benchmark consists of four datasets in total, where two datasets are used for supervised training and evaluation, and two are used for zero-shot evaluation. Additionally we compare state-of-the-art (SOTA) approaches on our benchmark and provide an exhaustive list of available public breast cancer MRI datasets. The source code has been made available at https://irulenot.github.io/BC_MRI_SEG_Benchmark.
End-to-End Multimodal Representation Learning for Video Dialog
Oct 26, 2022

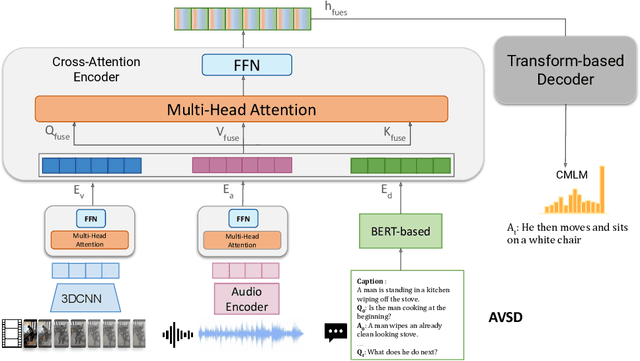

Video-based dialog task is a challenging multimodal learning task that has received increasing attention over the past few years with state-of-the-art obtaining new performance records. This progress is largely powered by the adaptation of the more powerful transformer-based language encoders. Despite this progress, existing approaches do not effectively utilize visual features to help solve tasks. Recent studies show that state-of-the-art models are biased toward textual information rather than visual cues. In order to better leverage the available visual information, this study proposes a new framework that combines 3D-CNN network and transformer-based networks into a single visual encoder to extract more robust semantic representations from videos. The visual encoder is jointly trained end-to-end with other input modalities such as text and audio. Experiments on the AVSD task show significant improvement over baselines in both generative and retrieval tasks.