 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Paper and Code
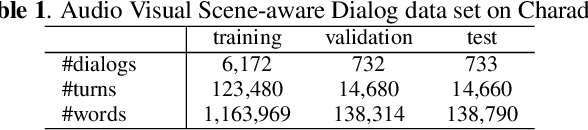
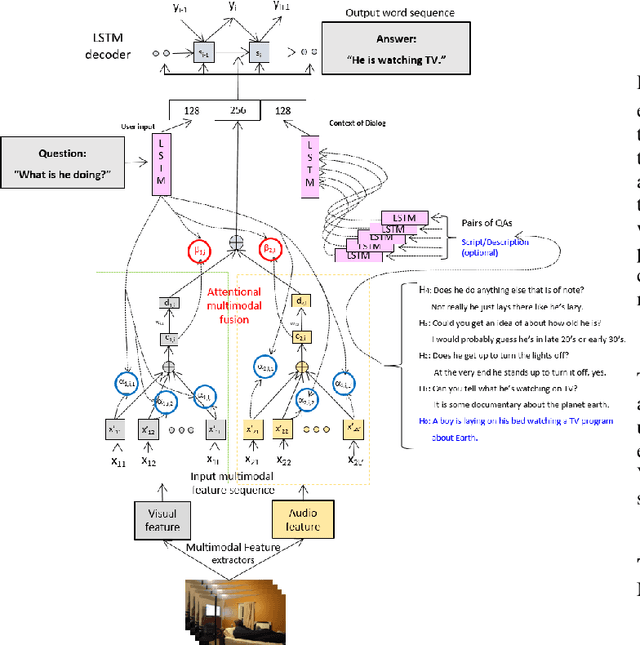
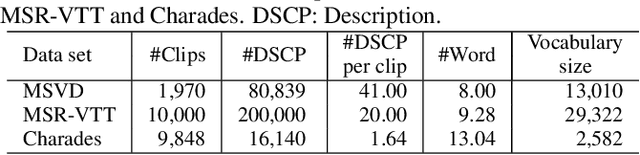
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.