 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotDesignGPT: Automated Robot Design Synthesis using Vision Language Models
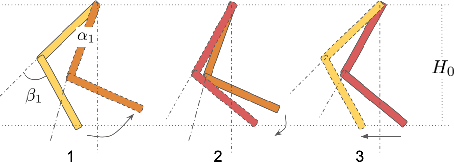
Jan 16, 2026Robot design is a nontrivial process that involves careful consideration of multiple criteria, including user specifications, kinematic structures, and visual appearance. Therefore, the design process often relies heavily on domain expertise and significant human effort. The majority of current methods are rule-based, requiring the specification of a grammar or a set of primitive components and modules that can be composed to create a design. We propose a novel automated robot design framework, RobotDesignGPT, that leverages the general knowledge and reasoning capabilities of large pre-trained vision-language models to automate the robot design synthesis process. Our framework synthesizes an initial robot design from a simple user prompt and a reference image. Our novel visual feedback approach allows us to greatly improve the design quality and reduce unnecessary manual feedback. We demonstrate that our framework can design visually appealing and kinematically valid robots inspired by nature, ranging from legged animals to flying creatures. We justify the proposed framework by conducting an ablation study and a user study.
Leveraging Procedural Knowledge and Task Hierarchies for Efficient Instructional Video Pre-training
Feb 24, 2025Instructional videos provide a convenient modality to learn new tasks (ex. cooking a recipe, or assembling furniture). A viewer will want to find a corresponding video that reflects both the overall task they are interested in as well as contains the relevant steps they need to carry out the task. To perform this, an instructional video model should be capable of inferring both the tasks and the steps that occur in an input video. Doing this efficiently and in a generalizable fashion is key when compute or relevant video topics used to train this model are limited. To address these requirements we explicitly mine task hierarchies and the procedural steps associated with instructional videos. We use this prior knowledge to pre-train our model, $\texttt{Pivot}$, for step and task prediction. During pre-training, we also provide video augmentation and early stopping strategies to optimally identify which model to use for downstream tasks. We test this pre-trained model on task recognition, step recognition, and step prediction tasks on two downstream datasets. When pre-training data and compute are limited, we outperform previous baselines along these tasks. Therefore, leveraging prior task and step structures enables efficient training of $\texttt{Pivot}$ for instructional video recommendation.
Exploring Efficient Foundational Multi-modal Models for Video Summarization
Oct 09, 2024Foundational models are able to generate text outputs given prompt instructions and text, audio, or image inputs. Recently these models have been combined to perform tasks on video, such as video summarization. Such video foundation models perform pre-training by aligning outputs from each modality-specific model into the same embedding space. Then the embeddings from each model are used within a language model, which is fine-tuned on a desired instruction set. Aligning each modality during pre-training is computationally expensive and prevents rapid testing of different base modality models. During fine-tuning, evaluation is carried out within in-domain videos where it is hard to understand the generalizability and data efficiency of these methods. To alleviate these issues we propose a plug-and-play video language model. It directly uses the texts generated from each input modality into the language model, avoiding pre-training alignment overhead. Instead of fine-tuning we leverage few-shot instruction adaptation strategies. We compare the performance versus the computational costs for our plug-and-play style method and baseline tuning methods. Finally, we explore the generalizability of each method during domain shift and present insights on what data is useful when training data is limited. Through this analysis, we present practical insights on how to leverage multi-modal foundational models for effective results given realistic compute and data limitations.
BayRnTune: Adaptive Bayesian Domain Randomization via Strategic Fine-tuning
Oct 16, 2023Domain randomization (DR), which entails training a policy with randomized dynamics, has proven to be a simple yet effective algorithm for reducing the gap between simulation and the real world. However, DR often requires careful tuning of randomization parameters. Methods like Bayesian Domain Randomization (Bayesian DR) and Active Domain Randomization (Adaptive DR) address this issue by automating parameter range selection using real-world experience. While effective, these algorithms often require long computation time, as a new policy is trained from scratch every iteration. In this work, we propose Adaptive Bayesian Domain Randomization via Strategic Fine-tuning (BayRnTune), which inherits the spirit of BayRn but aims to significantly accelerate the learning processes by fine-tuning from previously learned policy. This idea leads to a critical question: which previous policy should we use as a prior during fine-tuning? We investigated four different fine-tuning strategies and compared them against baseline algorithms in five simulated environments, ranging from simple benchmark tasks to more complex legged robot environments. Our analysis demonstrates that our method yields better rewards in the same amount of timesteps compared to vanilla domain randomization or Bayesian DR.
Learning a Single Policy for Diverse Behaviors on a Quadrupedal Robot using Scalable Motion Imitation
Mar 27, 2023



Learning various motor skills for quadrupedal robots is a challenging problem that requires careful design of task-specific mathematical models or reward descriptions. In this work, we propose to learn a single capable policy using deep reinforcement learning by imitating a large number of reference motions, including walking, turning, pacing, jumping, sitting, and lying. On top of the existing motion imitation framework, we first carefully design the observation space, the action space, and the reward function to improve the scalability of the learning as well as the robustness of the final policy. In addition, we adopt a novel adaptive motion sampling (AMS) method, which maintains a balance between successful and unsuccessful behaviors. This technique allows the learning algorithm to focus on challenging motor skills and avoid catastrophic forgetting. We demonstrate that the learned policy can exhibit diverse behaviors in simulation by successfully tracking both the training dataset and out-of-distribution trajectories. We also validate the importance of the proposed learning formulation and the adaptive motion sampling scheme by conducting experiments.
Residual Physics Learning and System Identification for Sim-to-real Transfer of Policies on Buoyancy Assisted Legged Robots
Mar 16, 2023The light and soft characteristics of Buoyancy Assisted Lightweight Legged Unit (BALLU) robots have a great potential to provide intrinsically safe interactions in environments involving humans, unlike many heavy and rigid robots. However, their unique and sensitive dynamics impose challenges to obtaining robust control policies in the real world. In this work, we demonstrate robust sim-to-real transfer of control policies on the BALLU robots via system identification and our novel residual physics learning method, Environment Mimic (EnvMimic). First, we model the nonlinear dynamics of the actuators by collecting hardware data and optimizing the simulation parameters. Rather than relying on standard supervised learning formulations, we utilize deep reinforcement learning to train an external force policy to match real-world trajectories, which enables us to model residual physics with greater fidelity. We analyze the improved simulation fidelity by comparing the simulation trajectories against the real-world ones. We finally demonstrate that the improved simulator allows us to learn better walking and turning policies that can be successfully deployed on the hardware of BALLU.
Solving Challenging Control Problems Using Two-Staged Deep Reinforcement Learning
Sep 27, 2021

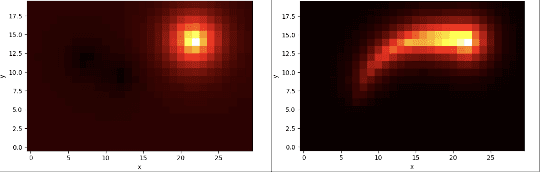
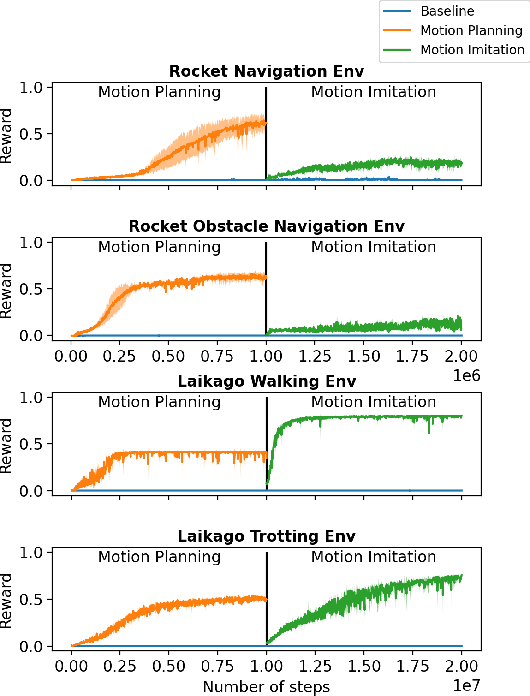
We present a two-staged deep reinforcement learning algorithm for solving challenging control problems. Deep reinforcement learning (deep RL) has been an effective tool for solving many high-dimensional continuous control problems, but it cannot effectively solve challenging problems with certain properties, such as sparse reward functions or sensitive dynamics. In this work, we propose an approach that decomposes the given problem into two stages: motion planning and motion imitation. The motion planning stage seeks to compute a feasible motion plan with approximated dynamics by directly sampling the state space rather than exploring random control signals. Once the motion plan is obtained, the motion imitation stage learns a control policy that can imitate the given motion plan with realistic sensors and actuations. We demonstrate that our approach can solve challenging control problems - rocket navigation and quadrupedal locomotion - which cannot be solved by the standard MDP formulation. The supplemental video can be found at: https://youtu.be/FYLo1Ov_8-g
Finite State Machine Policies Modulating Trajectory Generator
Sep 26, 2021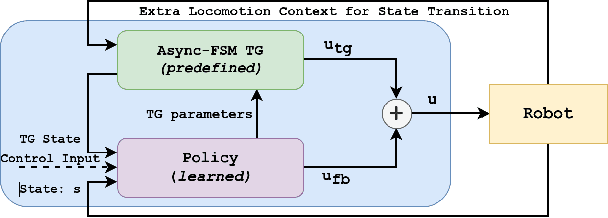
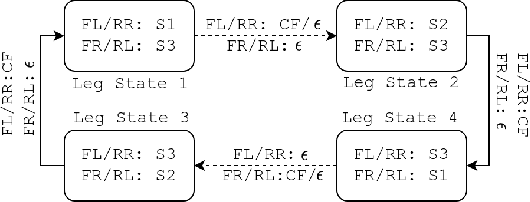

Deep reinforcement learning (deep RL) has emerged as an effective tool for developing controllers for legged robots. However, a simple neural network representation is known for its poor extrapolation ability, making the learned behavior vulnerable to unseen perturbations or challenging terrains. Therefore, researchers have investigated a novel architecture, Policies Modulating Trajectory Generators (PMTG), which combines trajectory generators (TG) and feedback control signals to achieve more robust behaviors. In this work, we propose to extend the PMTG framework with a finite state machine PMTG by replacing simple TGs with asynchronous finite state machines (Async FSMs). This invention offers an explicit notion of contact events to the policy to negotiate unexpected perturbations. We demonstrated that the proposed architecture could achieve more robust behaviors in various scenarios, such as challenging terrains or external perturbations, on both simulated and real robots. The supplemental video can be found at: http://youtu.be/XUiTSZaM8f0.