 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexEXO: A Wearability-First Dexterous Exoskeleton for Operator-Agnostic Demonstration and Learning
Mar 18, 2026Scaling dexterous robot learning is constrained by the difficulty of collecting high-quality demonstrations across diverse operators. Existing wearable interfaces often trade comfort and cross-user adaptability for kinematic fidelity, while embodiment mismatch between demonstration and deployment requires visual post-processing before policy training. We present DexEXO, a wearability-first hand exoskeleton that aligns visual appearance, contact geometry, and kinematics at the hardware level. DexEXO features a pose-tolerant thumb mechanism and a slider-based finger interface analytically modeled to support hand lengths from 140~mm to 217~mm, reducing operator-specific fitting and enabling scalable cross-operator data collection. A passive hand visually matches the deployed robot, allowing direct policy training from raw wrist-mounted RGB observations. User studies demonstrate improved comfort and usability compared to prior wearable systems. Using visually aligned observations alone, we train diffusion policies that achieve competitive performance while substantially simplifying the end-to-end pipeline. These results show that prioritizing wearability and hardware-level embodiment alignment reduces both human and algorithmic bottlenecks without sacrificing task performance. Project Page: https://dexexo-research.github.io/
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
Dec 10, 2025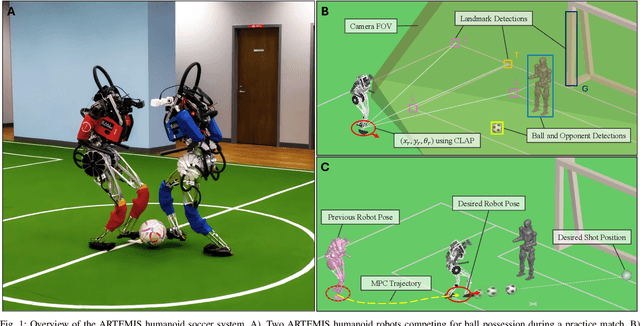

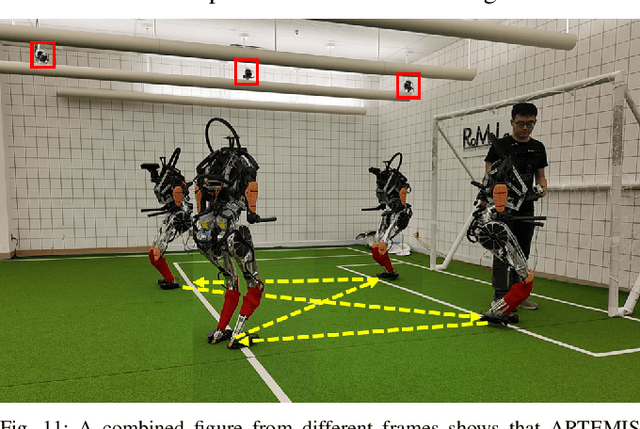
The development of athletic humanoid robots has gained significant attention as advances in actuation, sensing, and control enable increasingly dynamic, real-world capabilities. RoboCup, an international competition of fully autonomous humanoid robots, provides a uniquely challenging benchmark for such systems, culminating in the long-term goal of competing against human soccer players by 2050. This paper presents the hardware and software innovations underlying our team's victory in the RoboCup 2024 Adult-Sized Humanoid Soccer Competition. On the hardware side, we introduce an adult-sized humanoid platform built with lightweight structural components, high-torque quasi-direct-drive actuators, and a specialized foot design that enables powerful in-gait kicks while preserving locomotion robustness. On the software side, we develop an integrated perception and localization framework that combines stereo vision, object detection, and landmark-based fusion to provide reliable estimates of the ball, goals, teammates, and opponents. A mid-level navigation stack then generates collision-aware, dynamically feasible trajectories, while a centralized behavior manager coordinates high-level decision making, role selection, and kick execution based on the evolving game state. The seamless integration of these subsystems results in fast, precise, and tactically effective gameplay, enabling robust performance under the dynamic and adversarial conditions of real matches. This paper presents the design principles, system architecture, and experimental results that contributed to ARTEMIS's success as the 2024 Adult-Sized Humanoid Soccer champion.
CLAP: Clustering to Localize Across n Possibilities, A Simple, Robust Geometric Approach in the Presence of Symmetries
Sep 10, 2025In this paper, we present our localization method called CLAP, Clustering to Localize Across $n$ Possibilities, which helped us win the RoboCup 2024 adult-sized autonomous humanoid soccer competition. Competition rules limited our sensor suite to stereo vision and an inertial sensor, similar to humans. In addition, our robot had to deal with varying lighting conditions, dynamic feature occlusions, noise from high-impact stepping, and mistaken features from bystanders and neighboring fields. Therefore, we needed an accurate, and most importantly robust localization algorithm that would be the foundation for our path-planning and game-strategy algorithms. CLAP achieves these requirements by clustering estimated states of our robot from pairs of field features to localize its global position and orientation. Correct state estimates naturally cluster together, while incorrect estimates spread apart, making CLAP resilient to noise and incorrect inputs. CLAP is paired with a particle filter and an extended Kalman filter to improve consistency and smoothness. Tests of CLAP with other landmark-based localization methods showed similar accuracy. However, tests with increased false positive feature detection showed that CLAP outperformed other methods in terms of robustness with very little divergence and velocity jumps. Our localization performed well in competition, allowing our robot to shoot faraway goals and narrowly defend our goal.
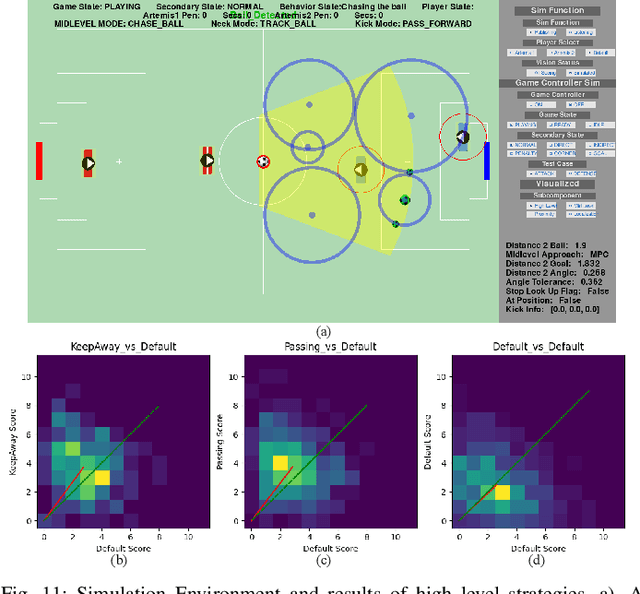
Model Predictive Control with Visibility Graphs for Humanoid Path Planning and Tracking Against Adversarial Opponents
Apr 03, 2025In this paper we detail the methods used for obstacle avoidance, path planning, and trajectory tracking that helped us win the adult-sized, autonomous humanoid soccer league in RoboCup 2024. Our team was undefeated for all seated matches and scored 45 goals over 6 games, winning the championship game 6 to 1. During the competition, a major challenge for collision avoidance was the measurement noise coming from bipedal locomotion and a limited field of view (FOV). Furthermore, obstacles would sporadically jump in and out of our planned trajectory. At times our estimator would place our robot inside a hard constraint. Any planner in this competition must also be be computationally efficient enough to re-plan and react in real time. This motivated our approach to trajectory generation and tracking. In many scenarios long-term and short-term planning is needed. To efficiently find a long-term general path that avoids all obstacles we developed DAVG (Dynamic Augmented Visibility Graphs). DAVG focuses on essential path planning by setting certain regions to be active based on obstacles and the desired goal pose. By augmenting the states in the graph, turning angles are considered, which is crucial for a large soccer playing robot as turning may be more costly. A trajectory is formed by linearly interpolating between discrete points generated by DAVG. A modified version of model predictive control (MPC) is used to then track this trajectory called cf-MPC (Collision-Free MPC). This ensures short-term planning. Without having to switch formulations cf-MPC takes into account the robot dynamics and collision free constraints. Without a hard switch the control input can smoothly transition in cases where the noise places our robot inside a constraint boundary. The nonlinear formulation runs at approximately 120 Hz, while the quadratic version achieves around 400 Hz.
Fast and Robust Localization for Humanoid Soccer Robot via Iterative Landmark Matching
Mar 14, 2025
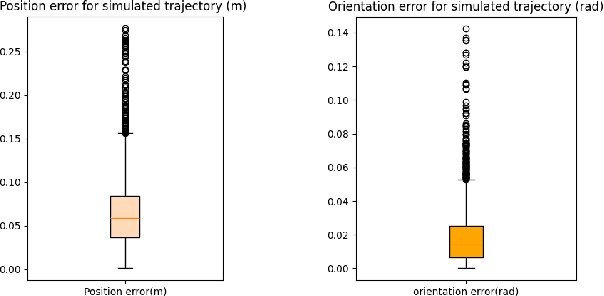
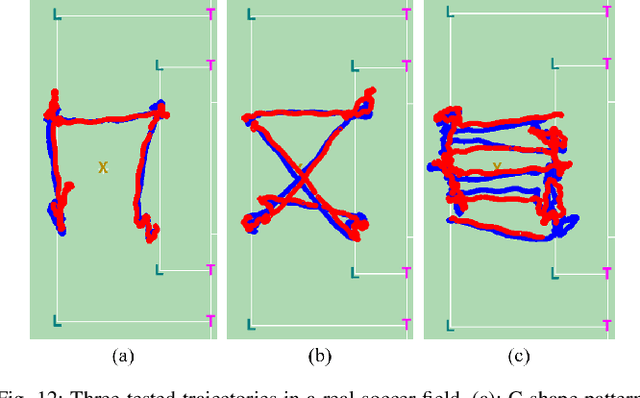
Accurate robot localization is essential for effective operation. Monte Carlo Localization (MCL) is commonly used with known maps but is computationally expensive due to landmark matching for each particle. Humanoid robots face additional challenges, including sensor noise from locomotion vibrations and a limited field of view (FOV) due to camera placement. This paper proposes a fast and robust localization method via iterative landmark matching (ILM) for humanoid robots. The iterative matching process improves the accuracy of the landmark association so that it does not need MCL to match landmarks to particles. Pose estimation with the outlier removal process enhances its robustness to measurement noise and faulty detections. Furthermore, an additional filter can be utilized to fuse inertial data from the inertial measurement unit (IMU) and pose data from localization. We compared ILM with Iterative Closest Point (ICP), which shows that ILM method is more robust towards the error in the initial guess and easier to get a correct matching. We also compared ILM with the Augmented Monte Carlo Localization (aMCL), which shows that ILM method is much faster than aMCL and even more accurate. The proposed method's effectiveness is thoroughly evaluated through experiments and validated on the humanoid robot ARTEMIS during RoboCup 2024 adult-sized soccer competition.
BayRnTune: Adaptive Bayesian Domain Randomization via Strategic Fine-tuning
Oct 16, 2023Domain randomization (DR), which entails training a policy with randomized dynamics, has proven to be a simple yet effective algorithm for reducing the gap between simulation and the real world. However, DR often requires careful tuning of randomization parameters. Methods like Bayesian Domain Randomization (Bayesian DR) and Active Domain Randomization (Adaptive DR) address this issue by automating parameter range selection using real-world experience. While effective, these algorithms often require long computation time, as a new policy is trained from scratch every iteration. In this work, we propose Adaptive Bayesian Domain Randomization via Strategic Fine-tuning (BayRnTune), which inherits the spirit of BayRn but aims to significantly accelerate the learning processes by fine-tuning from previously learned policy. This idea leads to a critical question: which previous policy should we use as a prior during fine-tuning? We investigated four different fine-tuning strategies and compared them against baseline algorithms in five simulated environments, ranging from simple benchmark tasks to more complex legged robot environments. Our analysis demonstrates that our method yields better rewards in the same amount of timesteps compared to vanilla domain randomization or Bayesian DR.
Design of a Jumping Control Framework with Heuristic Landing for Bipedal Robots
Apr 02, 2023



Generating dynamic jumping motions on legged robots remains a challenging control problem as the full flight phase and large landing impact are expected. Compared to quadrupedal robots or other multi-legged robots, bipedal robots place higher requirements for the control strategy given a much smaller footprint. To solve this problem, a novel heuristic landing planner is proposed in this paper. With the momentum feedback during the flight phase, landing locations can be updated to minimize the influence of uncertainties from tracking errors or external disturbances when landing. To the best of our knowledge, this is the first approach to take advantage of the flight phase to reduce the impact of the jump landing which is implemented in the actual robot. By integrating it with a modified kino-dynamics motion planner with centroidal momentum and a low-level controller which explores the whole-body dynamics to hierarchically handle multiple tasks, a complete and versatile jumping control framework is designed in this paper. Extensive results of simulation and hardware jumping experiments on a miniature bipedal robot with proprioceptive actuation are provided to demonstrate that the proposed framework is able to achieve human-like efficient and robust jumping tasks, including directional jump, twisting jump, step jump, and somersaults.
Residual Physics Learning and System Identification for Sim-to-real Transfer of Policies on Buoyancy Assisted Legged Robots
Mar 16, 2023The light and soft characteristics of Buoyancy Assisted Lightweight Legged Unit (BALLU) robots have a great potential to provide intrinsically safe interactions in environments involving humans, unlike many heavy and rigid robots. However, their unique and sensitive dynamics impose challenges to obtaining robust control policies in the real world. In this work, we demonstrate robust sim-to-real transfer of control policies on the BALLU robots via system identification and our novel residual physics learning method, Environment Mimic (EnvMimic). First, we model the nonlinear dynamics of the actuators by collecting hardware data and optimizing the simulation parameters. Rather than relying on standard supervised learning formulations, we utilize deep reinforcement learning to train an external force policy to match real-world trajectories, which enables us to model residual physics with greater fidelity. We analyze the improved simulation fidelity by comparing the simulation trajectories against the real-world ones. We finally demonstrate that the improved simulator allows us to learn better walking and turning policies that can be successfully deployed on the hardware of BALLU.
Benchmark Results for Bookshelf Organization Problem as Mixed Integer Nonlinear Program with Mode Switch and Collision Avoidance
Aug 28, 2022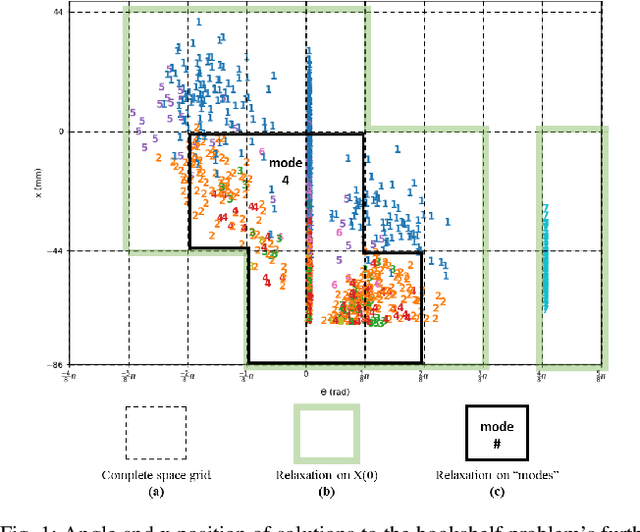


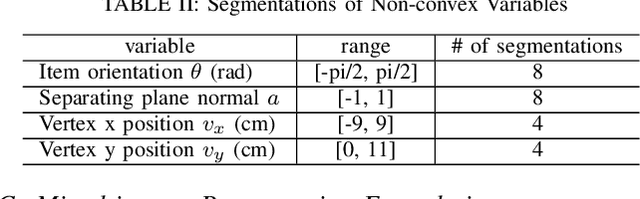
Mixed integer convex and nonlinear programs, MICP and MINLP, are expressive but require long solving times. Recent work that combines data-driven methods on solver heuristics has shown potential to overcome this issue allowing for applications on larger scale practical problems. To solve mixed-integer bilinear programs online with data-driven methods, several formulations exist including mathematical programming with complementary constraints (MPCC), mixed-integer programming (MIP). In this work, we benchmark the performances of those data-driven schemes on a bookshelf organization problem that has discrete mode switch and collision avoidance constraints. The success rate, optimal cost and solving time are compared along with non-data-driven methods. Our proposed methods are demonstrated as a high level planner for a robotic arm for the bookshelf problem.
ReDUCE: Reformulation of Mixed Integer Programs using Data from Unsupervised Clusters for Learning Efficient Strategies
Oct 01, 2021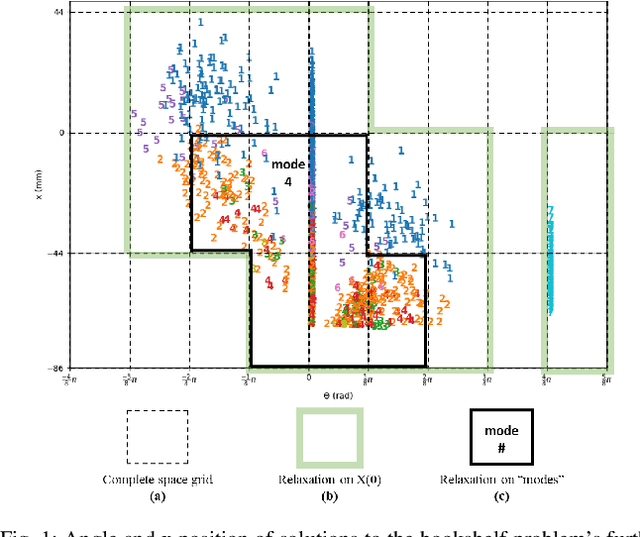


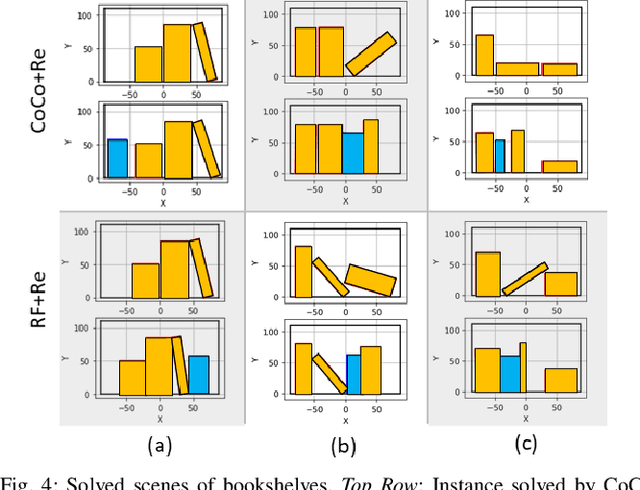
Mixed integer convex and nonlinear programs, MICP and MINLP, are expressive but require long solving times. Recent work that combines learning methods on solver heuristics has shown potential to overcome this issue allowing for applications on larger scale practical problems. Gathering sufficient training data to employ these methods still present a challenge since getting data from traditional solvers are slow and newer learning approaches still require large amounts of data. In order to scale up and make these hybrid learning approaches more manageable we propose ReDUCE, a method that exploits structure within small to medium size datasets. We also introduce the bookshelf organization problem as an MINLP as a way to measure performance of solvers with ReDUCE. Results show that existing algorithms with ReDUCE can solve this problem within a few seconds, a significant improvement over the original formulation. ReDUCE is demonstrated as a high level planner for a robotic arm for the bookshelf problem.