 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
AutoPP: Towards Automated Product Poster Generation and Optimization
Dec 26, 2025Product posters blend striking visuals with informative text to highlight the product and capture customer attention. However, crafting appealing posters and manually optimizing them based on online performance is laborious and resource-consuming. To address this, we introduce AutoPP, an automated pipeline for product poster generation and optimization that eliminates the need for human intervention. Specifically, the generator, relying solely on basic product information, first uses a unified design module to integrate the three key elements of a poster (background, text, and layout) into a cohesive output. Then, an element rendering module encodes these elements into condition tokens, efficiently and controllably generating the product poster. Based on the generated poster, the optimizer enhances its Click-Through Rate (CTR) by leveraging online feedback. It systematically replaces elements to gather fine-grained CTR comparisons and utilizes Isolated Direct Preference Optimization (IDPO) to attribute CTR gains to isolated elements. Our work is supported by AutoPP1M, the largest dataset specifically designed for product poster generation and optimization, which contains one million high-quality posters and feedback collected from over one million users. Experiments demonstrate that AutoPP achieves state-of-the-art results in both offline and online settings. Our code and dataset are publicly available at: https://github.com/JD-GenX/AutoPP
Towards Reliable Advertising Image Generation Using Human Feedback
Aug 01, 2024



In the e-commerce realm, compelling advertising images are pivotal for attracting customer attention. While generative models automate image generation, they often produce substandard images that may mislead customers and require significant labor costs to inspect. This paper delves into increasing the rate of available generated images. We first introduce a multi-modal Reliable Feedback Network (RFNet) to automatically inspect the generated images. Combining the RFNet into a recurrent process, Recurrent Generation, results in a higher number of available advertising images. To further enhance production efficiency, we fine-tune diffusion models with an innovative Consistent Condition regularization utilizing the feedback from RFNet (RFFT). This results in a remarkable increase in the available rate of generated images, reducing the number of attempts in Recurrent Generation, and providing a highly efficient production process without sacrificing visual appeal. We also construct a Reliable Feedback 1 Million (RF1M) dataset which comprises over one million generated advertising images annotated by human, which helps to train RFNet to accurately assess the availability of generated images and faithfully reflect the human feedback. Generally speaking, our approach offers a reliable solution for advertising image generation.
Generate E-commerce Product Background by Integrating Category Commonality and Personalized Style
Dec 20, 2023The state-of-the-art methods for e-commerce product background generation suffer from the inefficiency of designing product-wise prompts when scaling up the production, as well as the ineffectiveness of describing fine-grained styles when customizing personalized backgrounds for some specific brands. To address these obstacles, we integrate the category commonality and personalized style into diffusion models. Concretely, we propose a Category-Wise Generator to enable large-scale background generation for the first time. A unique identifier in the prompt is assigned to each category, whose attention is located on the background by a mask-guided cross attention layer to learn the category-wise style. Furthermore, for products with specific and fine-grained requirements in layout, elements, etc, a Personality-Wise Generator is devised to learn such personalized style directly from a reference image to resolve textual ambiguities, and is trained in a self-supervised manner for more efficient training data usage. To advance research in this field, the first large-scale e-commerce product background generation dataset BG60k is constructed, which covers more than 60k product images from over 2k categories. Experiments demonstrate that our method could generate high-quality backgrounds for different categories, and maintain the personalized background style of reference images. The link to BG60k and codes will be available soon.
Planning and Rendering: Towards End-to-End Product Poster Generation
Dec 14, 2023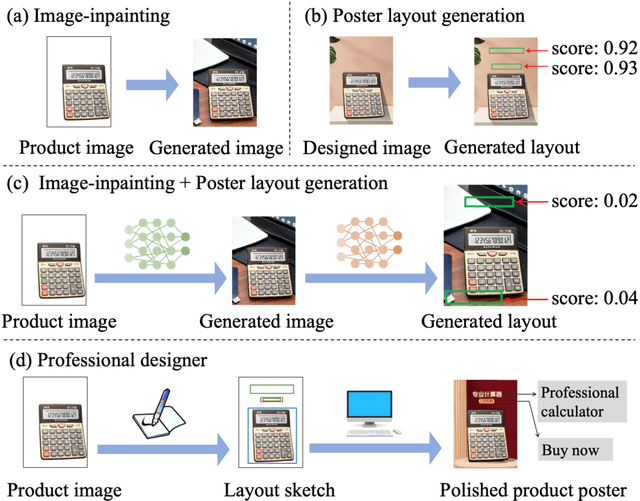
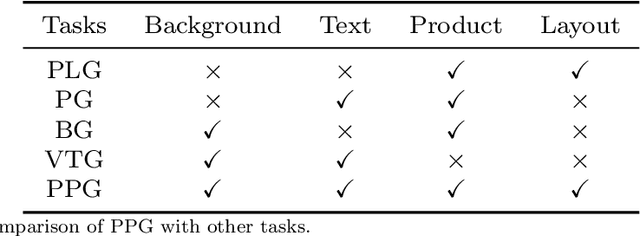
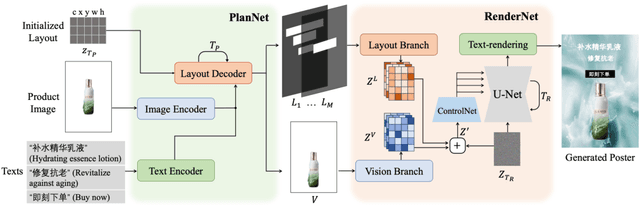
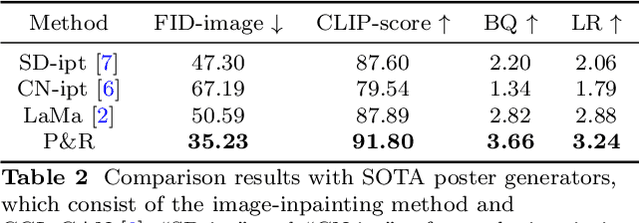
End-to-end product poster generation significantly optimizes design efficiency and reduces production costs. Prevailing methods predominantly rely on image-inpainting methods to generate clean background images for given products. Subsequently, poster layout generation methods are employed to produce corresponding layout results. However, the background images may not be suitable for accommodating textual content due to their complexity, and the fixed location of products limits the diversity of layout results. To alleviate these issues, we propose a novel product poster generation framework named P\&R. The P\&R draws inspiration from the workflow of designers in creating posters, which consists of two stages: Planning and Rendering. At the planning stage, we propose a PlanNet to generate the layout of the product and other visual components considering both the appearance features of the product and semantic features of the text, which improves the diversity and rationality of the layouts. At the rendering stage, we propose a RenderNet to generate the background for the product while considering the generated layout, where a spatial fusion module is introduced to fuse the layout of different visual components. To foster the advancement of this field, we propose the first end-to-end product poster generation dataset PPG30k, comprising 30k exquisite product poster images along with comprehensive image and text annotations. Our method outperforms the state-of-the-art product poster generation methods on PPG30k. The PPG30k will be released soon.
Relation-Aware Diffusion Model for Controllable Poster Layout Generation
Jun 15, 2023Poster layout is a crucial aspect of poster design. Prior methods primarily focus on the correlation between visual content and graphic elements. However, a pleasant layout should also consider the relationship between visual and textual contents and the relationship between elements. In this study, we introduce a relation-aware diffusion model for poster layout generation that incorporates these two relationships in the generation process. Firstly, we devise a visual-textual relation-aware module that aligns the visual and textual representations across modalities, thereby enhancing the layout's efficacy in conveying textual information. Subsequently, we propose a geometry relation-aware module that learns the geometry relationship between elements by comprehensively considering contextual information. Additionally, the proposed method can generate diverse layouts based on user constraints. To advance research in this field, we have constructed a poster layout dataset named CGL-Dataset V2. Our proposed method outperforms state-of-the-art methods on CGL-Dataset V2. The data and code will be available at https://github.com/liuan0803/RADM.
Design of a Jumping Control Framework with Heuristic Landing for Bipedal Robots
Apr 02, 2023



Generating dynamic jumping motions on legged robots remains a challenging control problem as the full flight phase and large landing impact are expected. Compared to quadrupedal robots or other multi-legged robots, bipedal robots place higher requirements for the control strategy given a much smaller footprint. To solve this problem, a novel heuristic landing planner is proposed in this paper. With the momentum feedback during the flight phase, landing locations can be updated to minimize the influence of uncertainties from tracking errors or external disturbances when landing. To the best of our knowledge, this is the first approach to take advantage of the flight phase to reduce the impact of the jump landing which is implemented in the actual robot. By integrating it with a modified kino-dynamics motion planner with centroidal momentum and a low-level controller which explores the whole-body dynamics to hierarchically handle multiple tasks, a complete and versatile jumping control framework is designed in this paper. Extensive results of simulation and hardware jumping experiments on a miniature bipedal robot with proprioceptive actuation are provided to demonstrate that the proposed framework is able to achieve human-like efficient and robust jumping tasks, including directional jump, twisting jump, step jump, and somersaults.
SoK: On the Semantic AI Security in Autonomous Driving
Mar 10, 2022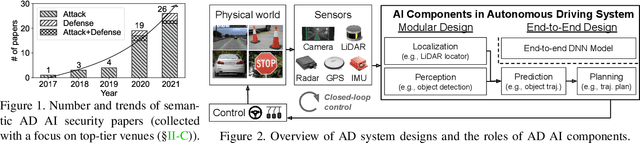
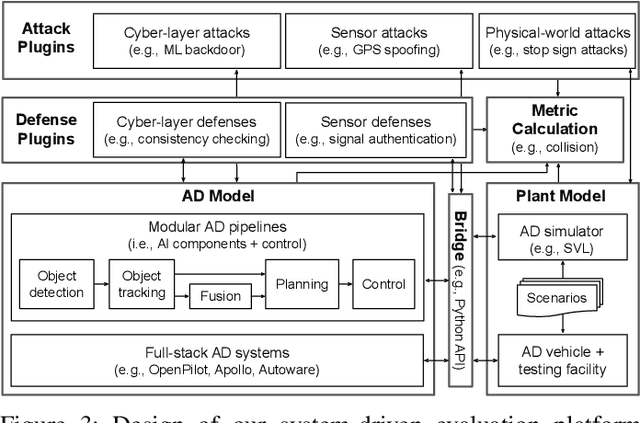


Autonomous Driving (AD) systems rely on AI components to make safety and correct driving decisions. Unfortunately, today's AI algorithms are known to be generally vulnerable to adversarial attacks. However, for such AI component-level vulnerabilities to be semantically impactful at the system level, it needs to address non-trivial semantic gaps both (1) from the system-level attack input spaces to those at AI component level, and (2) from AI component-level attack impacts to those at the system level. In this paper, we define such research space as semantic AI security as opposed to generic AI security. Over the past 5 years, increasingly more research works are performed to tackle such semantic AI security challenges in AD context, which has started to show an exponential growth trend. In this paper, we perform the first systematization of knowledge of such growing semantic AD AI security research space. In total, we collect and analyze 53 such papers, and systematically taxonomize them based on research aspects critical for the security field. We summarize 6 most substantial scientific gaps observed based on quantitative comparisons both vertically among existing AD AI security works and horizontally with security works from closely-related domains. With these, we are able to provide insights and potential future directions not only at the design level, but also at the research goal, methodology, and community levels. To address the most critical scientific methodology-level gap, we take the initiative to develop an open-source, uniform, and extensible system-driven evaluation platform, named PASS, for the semantic AD AI security research community. We also use our implemented platform prototype to showcase the capabilities and benefits of such a platform using representative semantic AD AI attacks.
End-to-end Uncertainty-based Mitigation of Adversarial Attacks to Automated Lane Centering
Feb 27, 2021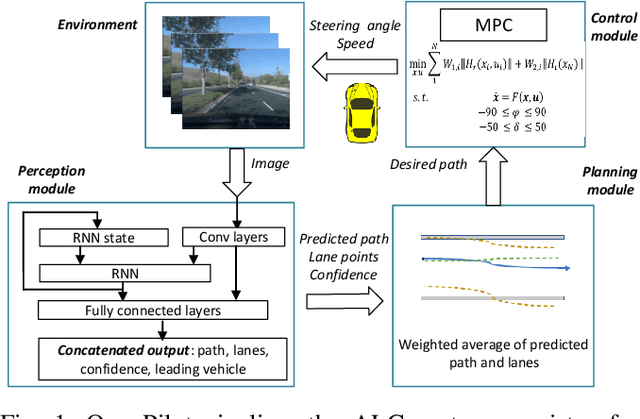

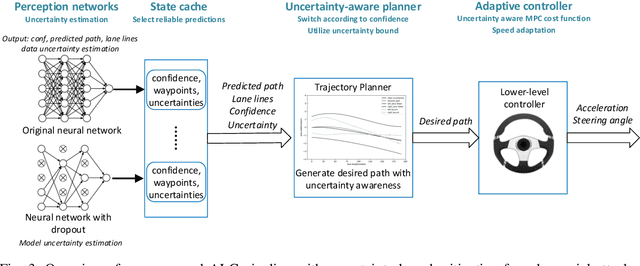
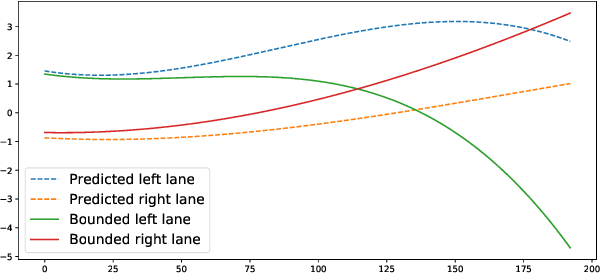
In the development of advanced driver-assistance systems (ADAS) and autonomous vehicles, machine learning techniques that are based on deep neural networks (DNNs) have been widely used for vehicle perception. These techniques offer significant improvement on average perception accuracy over traditional methods, however, have been shown to be susceptible to adversarial attacks, where small perturbations in the input may cause significant errors in the perception results and lead to system failure. Most prior works addressing such adversarial attacks focus only on the sensing and perception modules. In this work, we propose an end-to-end approach that addresses the impact of adversarial attacks throughout perception, planning, and control modules. In particular, we choose a target ADAS application, the automated lane centering system in OpenPilot, quantify the perception uncertainty under adversarial attacks, and design a robust planning and control module accordingly based on the uncertainty analysis. We evaluate our proposed approach using both the public dataset and production-grade autonomous driving simulator. The experiment results demonstrate that our approach can effectively mitigate the impact of adversarial attacks and can achieve 55% to 90% improvement over the original OpenPilot.