 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensicConcept: Transferable Forensic Concepts for AIGI Detection
Jun 05, 2026AI-generated image detectors achieve high accuracy on in-distribution data but often fail on unseen generators. A key obstacle to understanding this failure is the black-box nature of current detectors: they do not reveal which evidence drives their decisions. We propose ForensicConcept, a framework that extracts explicit forensic concepts from detectors and enables their transfer across backbones. Our method localizes decision-critical patches via Transformer attribution, clusters them into a compact concept codebook, and uses a concept-aligned projection to produce auditable evidence readouts. Motivated by prior studies showing that DINO representations can guide diffusion generation and exhibit concept-level correspondence with diffusion features, we introduce a generation-trace reference based on CleanDIFT diffusion features and quantify backbone-trace alignment via neighborhood-structure consistency (CKNNA). We further propose concept codebook injection to transfer diffusion-derived concepts into target backbones. Experiments on GenImage, GAN-family, and Chameleon benchmarks show consistent improvements over prior methods. We also find that CKNNA alignment predicts transfer effectiveness, providing a principled explanation for why some backbones yield more transferable forensic evidence than others.
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Jul 03, 2025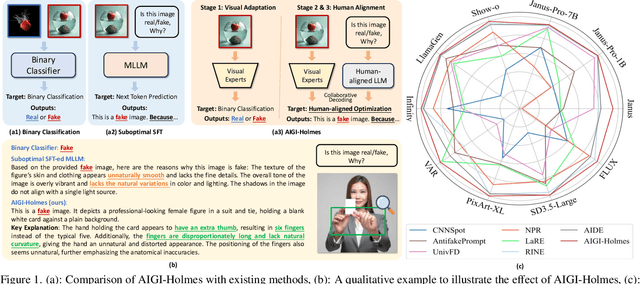
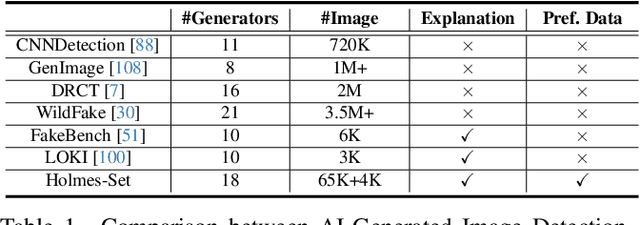
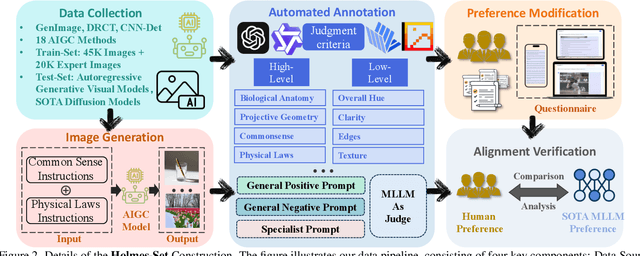
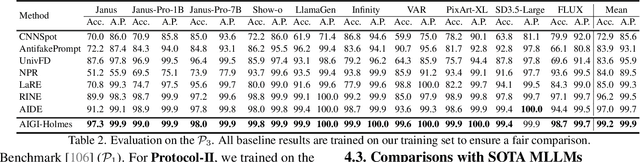
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.
Exploring the Collaborative Advantage of Low-level Information on Generalizable AI-Generated Image Detection
Apr 01, 2025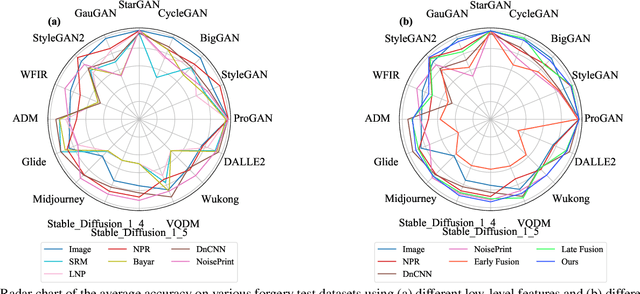
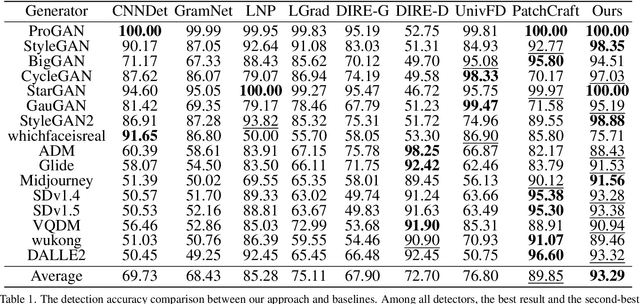
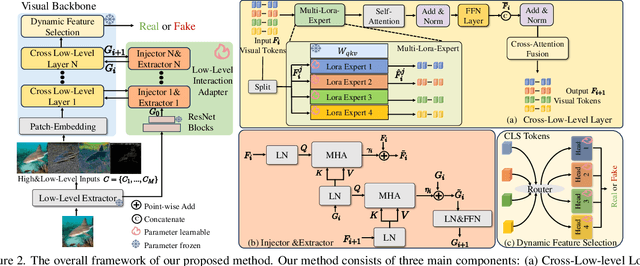
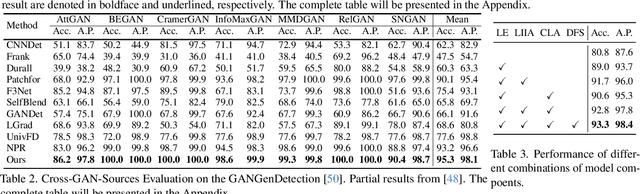
Existing state-of-the-art AI-Generated image detection methods mostly consider extracting low-level information from RGB images to help improve the generalization of AI-Generated image detection, such as noise patterns. However, these methods often consider only a single type of low-level information, which may lead to suboptimal generalization. Through empirical analysis, we have discovered a key insight: different low-level information often exhibits generalization capabilities for different types of forgeries. Furthermore, we found that simple fusion strategies are insufficient to leverage the detection advantages of each low-level and high-level information for various forgery types. Therefore, we propose the Adaptive Low-level Experts Injection (ALEI) framework. Our approach introduces Lora Experts, enabling the backbone network, which is trained with high-level semantic RGB images, to accept and learn knowledge from different low-level information. We utilize a cross-attention method to adaptively fuse these features at intermediate layers. To prevent the backbone network from losing the modeling capabilities of different low-level features during the later stages of modeling, we developed a Low-level Information Adapter that interacts with the features extracted by the backbone network. Finally, we propose Dynamic Feature Selection, which dynamically selects the most suitable features for detecting the current image to maximize generalization detection capability. Extensive experiments demonstrate that our method, finetuned on only four categories of mainstream ProGAN data, performs excellently and achieves state-of-the-art results on multiple datasets containing unseen GAN and Diffusion methods.
Revisiting Physical-World Adversarial Attack on Traffic Sign Recognition: A Commercial Systems Perspective
Sep 15, 2024Traffic Sign Recognition (TSR) is crucial for safe and correct driving automation. Recent works revealed a general vulnerability of TSR models to physical-world adversarial attacks, which can be low-cost, highly deployable, and capable of causing severe attack effects such as hiding a critical traffic sign or spoofing a fake one. However, so far existing works generally only considered evaluating the attack effects on academic TSR models, leaving the impacts of such attacks on real-world commercial TSR systems largely unclear. In this paper, we conduct the first large-scale measurement of physical-world adversarial attacks against commercial TSR systems. Our testing results reveal that it is possible for existing attack works from academia to have highly reliable (100\%) attack success against certain commercial TSR system functionality, but such attack capabilities are not generalizable, leading to much lower-than-expected attack success rates overall. We find that one potential major factor is a spatial memorization design that commonly exists in today's commercial TSR systems. We design new attack success metrics that can mathematically model the impacts of such design on the TSR system-level attack success, and use them to revisit existing attacks. Through these efforts, we uncover 7 novel observations, some of which directly challenge the observations or claims in prior works due to the introduction of the new metrics.
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Mar 26, 2024



The evolution of Diffusion Models has dramatically improved image generation quality, making it increasingly difficult to differentiate between real and generated images. This development, while impressive, also raises significant privacy and security concerns. In response to this, we propose a novel Latent REconstruction error guided feature REfinement method (LaRE^2) for detecting the diffusion-generated images. We come up with the Latent Reconstruction Error (LaRE), the first reconstruction-error based feature in the latent space for generated image detection. LaRE surpasses existing methods in terms of feature extraction efficiency while preserving crucial cues required to differentiate between the real and the fake. To exploit LaRE, we propose an Error-Guided feature REfinement module (EGRE), which can refine the image feature guided by LaRE to enhance the discriminativeness of the feature. Our EGRE utilizes an align-then-refine mechanism, which effectively refines the image feature for generated-image detection from both spatial and channel perspectives. Extensive experiments on the large-scale GenImage benchmark demonstrate the superiority of our LaRE^2, which surpasses the best SoTA method by up to 11.9%/12.1% average ACC/AP across 8 different image generators. LaRE also surpasses existing methods in terms of feature extraction cost, delivering an impressive speed enhancement of 8 times.
Does Physical Adversarial Example Really Matter to Autonomous Driving? Towards System-Level Effect of Adversarial Object Evasion Attack
Aug 23, 2023



In autonomous driving (AD), accurate perception is indispensable to achieving safe and secure driving. Due to its safety-criticality, the security of AD perception has been widely studied. Among different attacks on AD perception, the physical adversarial object evasion attacks are especially severe. However, we find that all existing literature only evaluates their attack effect at the targeted AI component level but not at the system level, i.e., with the entire system semantics and context such as the full AD pipeline. Thereby, this raises a critical research question: can these existing researches effectively achieve system-level attack effects (e.g., traffic rule violations) in the real-world AD context? In this work, we conduct the first measurement study on whether and how effectively the existing designs can lead to system-level effects, especially for the STOP sign-evasion attacks due to their popularity and severity. Our evaluation results show that all the representative prior works cannot achieve any system-level effects. We observe two design limitations in the prior works: 1) physical model-inconsistent object size distribution in pixel sampling and 2) lack of vehicle plant model and AD system model consideration. Then, we propose SysAdv, a novel system-driven attack design in the AD context and our evaluation results show that the system-level effects can be significantly improved, i.e., the violation rate increases by around 70%.
SoK: On the Semantic AI Security in Autonomous Driving
Mar 10, 2022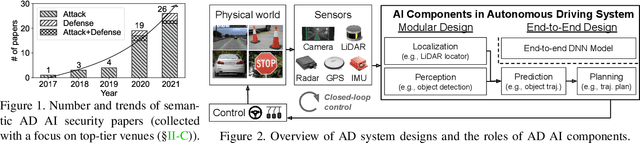
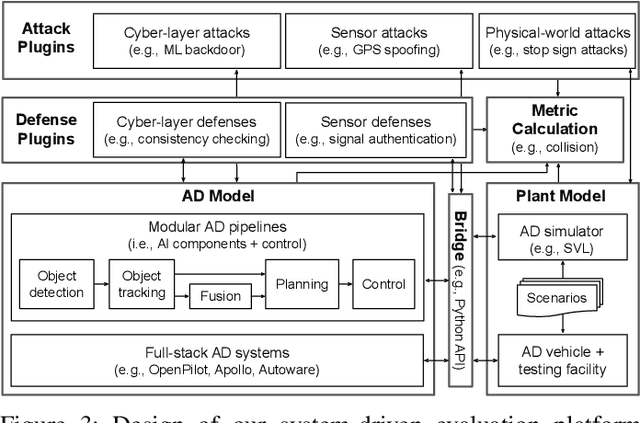


Autonomous Driving (AD) systems rely on AI components to make safety and correct driving decisions. Unfortunately, today's AI algorithms are known to be generally vulnerable to adversarial attacks. However, for such AI component-level vulnerabilities to be semantically impactful at the system level, it needs to address non-trivial semantic gaps both (1) from the system-level attack input spaces to those at AI component level, and (2) from AI component-level attack impacts to those at the system level. In this paper, we define such research space as semantic AI security as opposed to generic AI security. Over the past 5 years, increasingly more research works are performed to tackle such semantic AI security challenges in AD context, which has started to show an exponential growth trend. In this paper, we perform the first systematization of knowledge of such growing semantic AD AI security research space. In total, we collect and analyze 53 such papers, and systematically taxonomize them based on research aspects critical for the security field. We summarize 6 most substantial scientific gaps observed based on quantitative comparisons both vertically among existing AD AI security works and horizontally with security works from closely-related domains. With these, we are able to provide insights and potential future directions not only at the design level, but also at the research goal, methodology, and community levels. To address the most critical scientific methodology-level gap, we take the initiative to develop an open-source, uniform, and extensible system-driven evaluation platform, named PASS, for the semantic AD AI security research community. We also use our implemented platform prototype to showcase the capabilities and benefits of such a platform using representative semantic AD AI attacks.
Dual-Level Collaborative Transformer for Image Captioning
Jan 16, 2021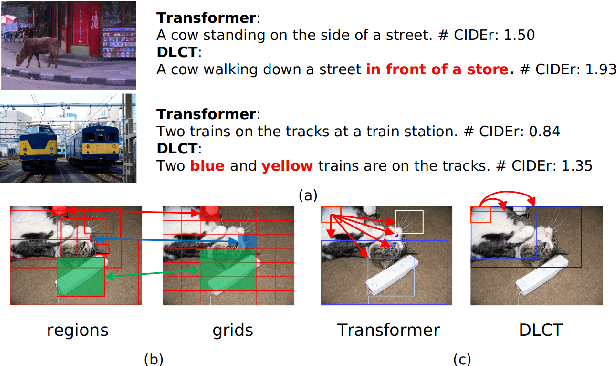
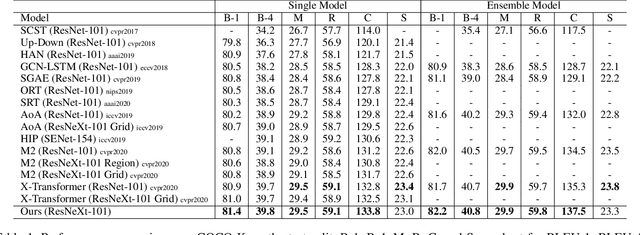
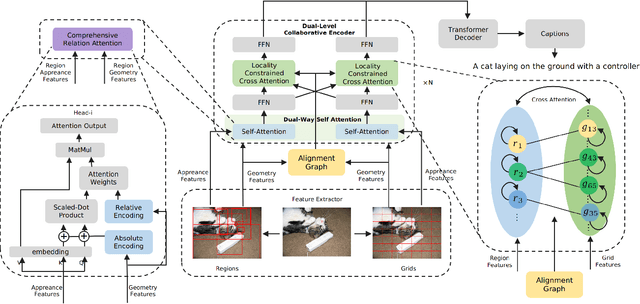
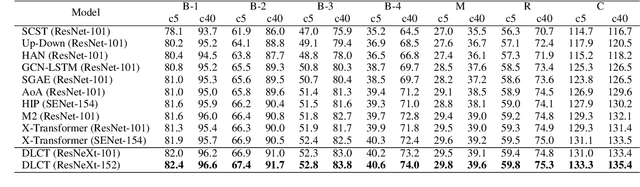
Descriptive region features extracted by object detection networks have played an important role in the recent advancements of image captioning. However, they are still criticized for the lack of contextual information and fine-grained details, which in contrast are the merits of traditional grid features. In this paper, we introduce a novel Dual-Level Collaborative Transformer (DLCT) network to realize the complementary advantages of the two features. Concretely, in DLCT, these two features are first processed by a novelDual-way Self Attenion (DWSA) to mine their intrinsic properties, where a Comprehensive Relation Attention component is also introduced to embed the geometric information. In addition, we propose a Locality-Constrained Cross Attention module to address the semantic noises caused by the direct fusion of these two features, where a geometric alignment graph is constructed to accurately align and reinforce region and grid features. To validate our model, we conduct extensive experiments on the highly competitive MS-COCO dataset, and achieve new state-of-the-art performance on both local and online test sets, i.e., 133.8% CIDEr-D on Karpathy split and 135.4% CIDEr on the official split. Code is available at https://github.com/luo3300612/image-captioning-DLCT.
Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network
Dec 13, 2020

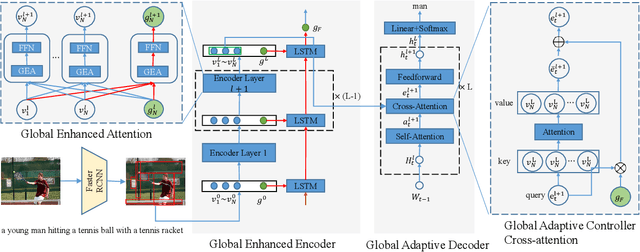

Transformer-based architectures have shown great success in image captioning, where object regions are encoded and then attended into the vectorial representations to guide the caption decoding. However, such vectorial representations only contain region-level information without considering the global information reflecting the entire image, which fails to expand the capability of complex multi-modal reasoning in image captioning. In this paper, we introduce a Global Enhanced Transformer (termed GET) to enable the extraction of a more comprehensive global representation, and then adaptively guide the decoder to generate high-quality captions. In GET, a Global Enhanced Encoder is designed for the embedding of the global feature, and a Global Adaptive Decoder are designed for the guidance of the caption generation. The former models intra- and inter-layer global representation by taking advantage of the proposed Global Enhanced Attention and a layer-wise fusion module. The latter contains a Global Adaptive Controller that can adaptively fuse the global information into the decoder to guide the caption generation. Extensive experiments on MS COCO dataset demonstrate the superiority of our GET over many state-of-the-arts.