 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMem: Context Management with A Decoupled Long-Context Model
May 29, 2026Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment. In this paper, we introduce CoMem, a novel framework that decouples memory management from the primary agent workflow, enabling these processes to execute in parallel. We propose a $k$-step-off asynchronous pipeline that overlaps the memory model's summarization with the agent's inference, effectively masking the latency of context processing. To ensure robustness under this asynchronous setting, we introduce a reward-driven training strategy that aligns the memory model to capture sufficient statistics for the agent's decision-making. Theoretical analysis confirms that CoMem offers a superior efficiency-effectiveness trade-off compared to coupled architectures. Our extensive experimental results on SWE-Bench-Verified show that CoMem provides 1.4x latency improvements upon vanilla long-context solutions while preserving most of the performance. Furthermore, we demonstrate that these latency gains scale favorably with increased system throughput, offering a modular path forward for the independent optimization of agent reasoning and memory compression.
T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
May 04, 2026Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
Autoregressive Image Generation with Masked Bit Modeling
Feb 09, 2026This paper challenges the dominance of continuous pipelines in visual generation. We systematically investigate the performance gap between discrete and continuous methods. Contrary to the belief that discrete tokenizers are intrinsically inferior, we demonstrate that the disparity arises primarily from the total number of bits allocated in the latent space (i.e., the compression ratio). We show that scaling up the codebook size effectively bridges this gap, allowing discrete tokenizers to match or surpass their continuous counterparts. However, existing discrete generation methods struggle to capitalize on this insight, suffering from performance degradation or prohibitive training costs with scaled codebook. To address this, we propose masked Bit AutoRegressive modeling (BAR), a scalable framework that supports arbitrary codebook sizes. By equipping an autoregressive transformer with a masked bit modeling head, BAR predicts discrete tokens through progressively generating their constituent bits. BAR achieves a new state-of-the-art gFID of 0.99 on ImageNet-256, outperforming leading methods across both continuous and discrete paradigms, while significantly reducing sampling costs and converging faster than prior continuous approaches. Project page is available at https://bar-gen.github.io/
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time
Jun 06, 2025Large Language Model (LLM) empowered agents have recently emerged as advanced paradigms that exhibit impressive capabilities in a wide range of domains and tasks. Despite their potential, current LLM agents often adopt a one-size-fits-all approach, lacking the flexibility to respond to users' varying needs and preferences. This limitation motivates us to develop PersonaAgent, the first personalized LLM agent framework designed to address versatile personalization tasks. Specifically, PersonaAgent integrates two complementary components - a personalized memory module that includes episodic and semantic memory mechanisms; a personalized action module that enables the agent to perform tool actions tailored to the user. At the core, the persona (defined as unique system prompt for each user) functions as an intermediary: it leverages insights from personalized memory to control agent actions, while the outcomes of these actions in turn refine the memory. Based on the framework, we propose a test-time user-preference alignment strategy that simulate the latest n interactions to optimize the persona prompt, ensuring real-time user preference alignment through textual loss feedback between simulated and ground-truth responses. Experimental evaluations demonstrate that PersonaAgent significantly outperforms other baseline methods by not only personalizing the action space effectively but also scaling during test-time real-world applications. These results underscore the feasibility and potential of our approach in delivering tailored, dynamic user experiences.
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
Dec 13, 2024



We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.
Text2Layer: Layered Image Generation using Latent Diffusion Model
Jul 19, 2023Layer compositing is one of the most popular image editing workflows among both amateurs and professionals. Motivated by the success of diffusion models, we explore layer compositing from a layered image generation perspective. Instead of generating an image, we propose to generate background, foreground, layer mask, and the composed image simultaneously. To achieve layered image generation, we train an autoencoder that is able to reconstruct layered images and train diffusion models on the latent representation. One benefit of the proposed problem is to enable better compositing workflows in addition to the high-quality image output. Another benefit is producing higher-quality layer masks compared to masks produced by a separate step of image segmentation. Experimental results show that the proposed method is able to generate high-quality layered images and initiates a benchmark for future work.
Patton: Language Model Pretraining on Text-Rich Networks
May 20, 2023A real-world text corpus sometimes comprises not only text documents but also semantic links between them (e.g., academic papers in a bibliographic network are linked by citations and co-authorships). Text documents and semantic connections form a text-rich network, which empowers a wide range of downstream tasks such as classification and retrieval. However, pretraining methods for such structures are still lacking, making it difficult to build one generic model that can be adapted to various tasks on text-rich networks. Current pretraining objectives, such as masked language modeling, purely model texts and do not take inter-document structure information into consideration. To this end, we propose our PretrAining on TexT-Rich NetwOrk framework Patton. Patton includes two pretraining strategies: network-contextualized masked language modeling and masked node prediction, to capture the inherent dependency between textual attributes and network structure. We conduct experiments on four downstream tasks in five datasets from both academic and e-commerce domains, where Patton outperforms baselines significantly and consistently.
Federated Learning with Client-Exclusive Classes
Jan 01, 2023


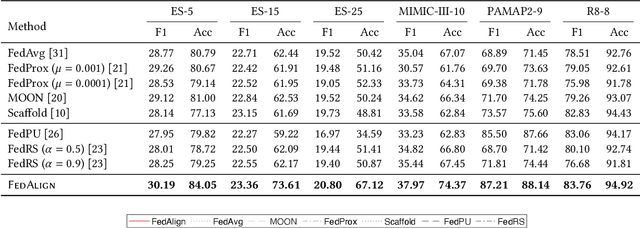
Existing federated classification algorithms typically assume the local annotations at every client cover the same set of classes. In this paper, we aim to lift such an assumption and focus on a more general yet practical non-IID setting where every client can work on non-identical and even disjoint sets of classes (i.e., client-exclusive classes), and the clients have a common goal which is to build a global classification model to identify the union of these classes. Such heterogeneity in client class sets poses a new challenge: how to ensure different clients are operating in the same latent space so as to avoid the drift after aggregation? We observe that the classes can be described in natural languages (i.e., class names) and these names are typically safe to share with all parties. Thus, we formulate the classification problem as a matching process between data representations and class representations and break the classification model into a data encoder and a label encoder. We leverage the natural-language class names as the common ground to anchor the class representations in the label encoder. In each iteration, the label encoder updates the class representations and regulates the data representations through matching. We further use the updated class representations at each round to annotate data samples for locally-unaware classes according to similarity and distill knowledge to local models. Extensive experiments on four real-world datasets show that the proposed method can outperform various classical and state-of-the-art federated learning methods designed for learning with non-IID data.