 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025
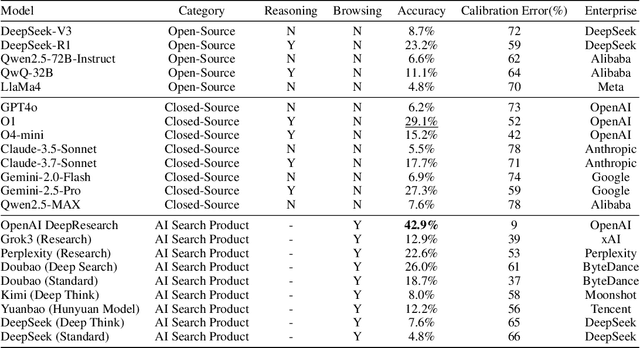
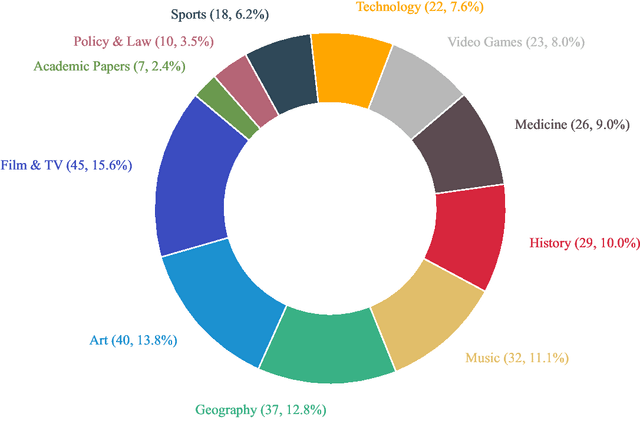
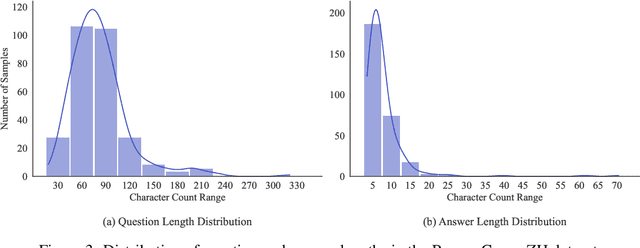
As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
Rethinking Graph Transformer Architecture Design for Node Classification
Oct 15, 2024


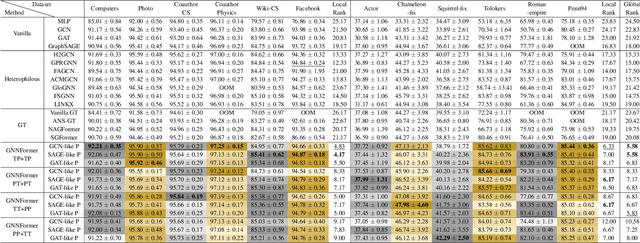
Graph Transformer (GT), as a special type of Graph Neural Networks (GNNs), utilizes multi-head attention to facilitate high-order message passing. However, this also imposes several limitations in node classification applications: 1) nodes are susceptible to global noise; 2) self-attention computation cannot scale well to large graphs. In this work, we conduct extensive observational experiments to explore the adaptability of the GT architecture in node classification tasks and draw several conclusions: the current multi-head self-attention module in GT can be completely replaceable, while the feed-forward neural network module proves to be valuable. Based on this, we decouple the propagation (P) and transformation (T) of GNNs and explore a powerful GT architecture, named GNNFormer, which is based on the P/T combination message passing and adapted for node classification in both homophilous and heterophilous scenarios. Extensive experiments on 12 benchmark datasets demonstrate that our proposed GT architecture can effectively adapt to node classification tasks without being affected by global noise and computational efficiency limitations.
Enhancing Ethereum Fraud Detection via Generative and Contrastive Self-supervision
Aug 01, 2024



The rampant fraudulent activities on Ethereum hinder the healthy development of the blockchain ecosystem, necessitating the reinforcement of regulations. However, multiple imbalances involving account interaction frequencies and interaction types in the Ethereum transaction environment pose significant challenges to data mining-based fraud detection research. To address this, we first propose the concept of meta-interactions to refine interaction behaviors in Ethereum, and based on this, we present a dual self-supervision enhanced Ethereum fraud detection framework, named Meta-IFD. This framework initially introduces a generative self-supervision mechanism to augment the interaction features of accounts, followed by a contrastive self-supervision mechanism to differentiate various behavior patterns, and ultimately characterizes the behavioral representations of accounts and mines potential fraud risks through multi-view interaction feature learning. Extensive experiments on real Ethereum datasets demonstrate the effectiveness and superiority of our framework in detecting common Ethereum fraud behaviors such as Ponzi schemes and phishing scams. Additionally, the generative module can effectively alleviate the interaction distribution imbalance in Ethereum data, while the contrastive module significantly enhances the framework's ability to distinguish different behavior patterns. The source code will be released on GitHub soon.
PathMLP: Smooth Path Towards High-order Homophily
Jun 23, 2023



Real-world graphs exhibit increasing heterophily, where nodes no longer tend to be connected to nodes with the same label, challenging the homophily assumption of classical graph neural networks (GNNs) and impeding their performance. Intriguingly, we observe that certain high-order information on heterophilous data exhibits high homophily, which motivates us to involve high-order information in node representation learning. However, common practices in GNNs to acquire high-order information mainly through increasing model depth and altering message-passing mechanisms, which, albeit effective to a certain extent, suffer from three shortcomings: 1) over-smoothing due to excessive model depth and propagation times; 2) high-order information is not fully utilized; 3) low computational efficiency. In this regard, we design a similarity-based path sampling strategy to capture smooth paths containing high-order homophily. Then we propose a lightweight model based on multi-layer perceptrons (MLP), named PathMLP, which can encode messages carried by paths via simple transformation and concatenation operations, and effectively learn node representations in heterophilous graphs through adaptive path aggregation. Extensive experiments demonstrate that our method outperforms baselines on 16 out of 20 datasets, underlining its effectiveness and superiority in alleviating the heterophily problem. In addition, our method is immune to over-smoothing and has high computational efficiency.
Neighborhood Homophily-Guided Graph Convolutional Network
Jan 24, 2023



Graph neural networks (GNNs) have achieved remarkable advances in graph-oriented tasks. However, many real-world graphs contain heterophily or low homophily, challenging the homophily assumption of classical GNNs and resulting in low performance. Although many studies have emerged to improve the universality of GNNs, they rarely consider the label reuse and the correlation of their proposed metrics and models. In this paper, we first design a new metric, named Neighborhood Homophily (\textit{NH}), to measure the label complexity or purity in the neighborhood of nodes. Furthermore, we incorporate this metric into the classical graph convolutional network (GCN) architecture and propose \textbf{N}eighborhood \textbf{H}omophily-\textbf{G}uided \textbf{G}raph \textbf{C}onvolutional \textbf{N}etwork (\textbf{NHGCN}). In this framework, nodes are grouped by estimated \textit{NH} values to achieve intra-group weight sharing during message propagation and aggregation. Then the generated node predictions are used to estimate and update new \textit{NH} values. The two processes of metric estimation and model inference are alternately optimized to achieve better node classification. Extensive experiments on both homophilous and heterophilous benchmarks demonstrate that \textbf{NHGCN} achieves state-of-the-art overall performance on semi-supervised node classification for the universality problem.
Data Augmentation on Graphs: A Survey
Dec 20, 2022In recent years, graph representation learning has achieved remarkable success while suffering from low-quality data problems. As a mature technology to improve data quality in computer vision, data augmentation has also attracted increasing attention in graph domain. For promoting the development of this emerging research direction, in this survey, we comprehensively review and summarize the existing graph data augmentation (GDAug) techniques. Specifically, we first summarize a variety of feasible taxonomies, and then classify existing GDAug studies based on fine-grained graph elements. Furthermore, for each type of GDAug technique, we formalize the general definition, discuss the technical details, and give schematic illustration. In addition, we also summarize common performance metrics and specific design metrics for constructing a GDAug evaluation system. Finally, we summarize the applications of GDAug from both data and model levels, as well as future directions.