 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOA-Mine: Open-World Attribute Mining for E-Commerce Products with Weak Supervision
Paper and Code



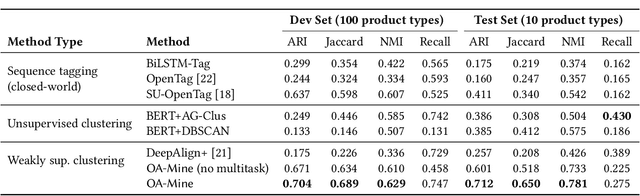
Automatic extraction of product attributes from their textual descriptions is essential for online shopper experience. One inherent challenge of this task is the emerging nature of e-commerce products -- we see new types of products with their unique set of new attributes constantly. Most prior works on this matter mine new values for a set of known attributes but cannot handle new attributes that arose from constantly changing data. In this work, we study the attribute mining problem in an open-world setting to extract novel attributes and their values. Instead of providing comprehensive training data, the user only needs to provide a few examples for a few known attribute types as weak supervision. We propose a principled framework that first generates attribute value candidates and then groups them into clusters of attributes. The candidate generation step probes a pre-trained language model to extract phrases from product titles. Then, an attribute-aware fine-tuning method optimizes a multitask objective and shapes the language model representation to be attribute-discriminative. Finally, we discover new attributes and values through the self-ensemble of our framework, which handles the open-world challenge. We run extensive experiments on a large distantly annotated development set and a gold standard human-annotated test set that we collected. Our model significantly outperforms strong baselines and can generalize to unseen attributes and product types.