 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidote: A Unified Framework for Mitigating LVLM Hallucinations in Counterfactual Presupposition and Object Perception
Apr 29, 2025



Large Vision-Language Models (LVLMs) have achieved impressive results across various cross-modal tasks. However, hallucinations, i.e., the models generating counterfactual responses, remain a challenge. Though recent studies have attempted to alleviate object perception hallucinations, they focus on the models' response generation, and overlooking the task question itself. This paper discusses the vulnerability of LVLMs in solving counterfactual presupposition questions (CPQs), where the models are prone to accept the presuppositions of counterfactual objects and produce severe hallucinatory responses. To this end, we introduce "Antidote", a unified, synthetic data-driven post-training framework for mitigating both types of hallucination above. It leverages synthetic data to incorporate factual priors into questions to achieve self-correction, and decouple the mitigation process into a preference optimization problem. Furthermore, we construct "CP-Bench", a novel benchmark to evaluate LVLMs' ability to correctly handle CPQs and produce factual responses. Applied to the LLaVA series, Antidote can simultaneously enhance performance on CP-Bench by over 50%, POPE by 1.8-3.3%, and CHAIR & SHR by 30-50%, all without relying on external supervision from stronger LVLMs or human feedback and introducing noticeable catastrophic forgetting issues.
ToVE: Efficient Vision-Language Learning via Knowledge Transfer from Vision Experts
Apr 01, 2025



Vision-language (VL) learning requires extensive visual perception capabilities, such as fine-grained object recognition and spatial perception. Recent works typically rely on training huge models on massive datasets to develop these capabilities. As a more efficient alternative, this paper proposes a new framework that Transfers the knowledge from a hub of Vision Experts (ToVE) for efficient VL learning, leveraging pre-trained vision expert models to promote visual perception capability. Specifically, building on a frozen CLIP encoder that provides vision tokens for image-conditioned language generation, ToVE introduces a hub of multiple vision experts and a token-aware gating network that dynamically routes expert knowledge to vision tokens. In the transfer phase, we propose a "residual knowledge transfer" strategy, which not only preserves the generalizability of the vision tokens but also allows detachment of low-contributing experts to improve inference efficiency. Further, we explore to merge these expert knowledge to a single CLIP encoder, creating a knowledge-merged CLIP that produces more informative vision tokens without expert inference during deployment. Experiment results across various VL tasks demonstrate that the proposed ToVE achieves competitive performance with two orders of magnitude fewer training data.
LaRE^2: Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
Mar 26, 2024



The evolution of Diffusion Models has dramatically improved image generation quality, making it increasingly difficult to differentiate between real and generated images. This development, while impressive, also raises significant privacy and security concerns. In response to this, we propose a novel Latent REconstruction error guided feature REfinement method (LaRE^2) for detecting the diffusion-generated images. We come up with the Latent Reconstruction Error (LaRE), the first reconstruction-error based feature in the latent space for generated image detection. LaRE surpasses existing methods in terms of feature extraction efficiency while preserving crucial cues required to differentiate between the real and the fake. To exploit LaRE, we propose an Error-Guided feature REfinement module (EGRE), which can refine the image feature guided by LaRE to enhance the discriminativeness of the feature. Our EGRE utilizes an align-then-refine mechanism, which effectively refines the image feature for generated-image detection from both spatial and channel perspectives. Extensive experiments on the large-scale GenImage benchmark demonstrate the superiority of our LaRE^2, which surpasses the best SoTA method by up to 11.9%/12.1% average ACC/AP across 8 different image generators. LaRE also surpasses existing methods in terms of feature extraction cost, delivering an impressive speed enhancement of 8 times.
Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey
Feb 08, 2024Large-scale pre-trained vision models (PVMs) have shown great potential for adaptability across various downstream vision tasks. However, with state-of-the-art PVMs growing to billions or even trillions of parameters, the standard full fine-tuning paradigm is becoming unsustainable due to high computational and storage demands. In response, researchers are exploring parameter-efficient fine-tuning (PEFT), which seeks to exceed the performance of full fine-tuning with minimal parameter modifications. This survey provides a comprehensive overview and future directions for visual PEFT, offering a systematic review of the latest advancements. First, we provide a formal definition of PEFT and discuss model pre-training methods. We then categorize existing methods into three categories: addition-based, partial-based, and unified-based. Finally, we introduce the commonly used datasets and applications and suggest potential future research challenges. A comprehensive collection of resources is available at https://github.com/synbol/Awesome-Parameter-Efficient-Transfer-Learning.
VMT-Adapter: Parameter-Efficient Transfer Learning for Multi-Task Dense Scene Understanding
Dec 15, 2023Large-scale pre-trained models have achieved remarkable success in various computer vision tasks. A standard approach to leverage these models is to fine-tune all model parameters for downstream tasks, which poses challenges in terms of computational and storage costs. Recently, inspired by Natural Language Processing (NLP), parameter-efficient transfer learning has been successfully applied to vision tasks. However, most existing techniques primarily focus on single-task adaptation, and despite limited research on multi-task adaptation, these methods often exhibit suboptimal training and inference efficiency. In this paper, we first propose an once-for-all Vision Multi-Task Adapter (VMT-Adapter), which strikes approximately O(1) training and inference efficiency w.r.t task number. Concretely, VMT-Adapter shares the knowledge from multiple tasks to enhance cross-task interaction while preserves task-specific knowledge via independent knowledge extraction modules. Notably, since task-specific modules require few parameters, VMT-Adapter can handle an arbitrary number of tasks with a negligible increase of trainable parameters. We also propose VMT-Adapter-Lite, which further reduces the trainable parameters by learning shared parameters between down- and up-projections. Extensive experiments on four dense scene understanding tasks demonstrate the superiority of VMT-Adapter(-Lite), achieving a 3.96%(1.34%) relative improvement compared to single-task full fine-tuning, while utilizing merely ~1% (0.36%) trainable parameters of the pre-trained model.
MmAP : Multi-modal Alignment Prompt for Cross-domain Multi-task Learning
Dec 14, 2023Multi-Task Learning (MTL) is designed to train multiple correlated tasks simultaneously, thereby enhancing the performance of individual tasks. Typically, a multi-task network structure consists of a shared backbone and task-specific decoders. However, the complexity of the decoders increases with the number of tasks. To tackle this challenge, we integrate the decoder-free vision-language model CLIP, which exhibits robust zero-shot generalization capability. Recently, parameter-efficient transfer learning methods have been extensively explored with CLIP for adapting to downstream tasks, where prompt tuning showcases strong potential. Nevertheless, these methods solely fine-tune a single modality (text or visual), disrupting the modality structure of CLIP. In this paper, we first propose Multi-modal Alignment Prompt (MmAP) for CLIP, which aligns text and visual modalities during fine-tuning process. Building upon MmAP, we develop an innovative multi-task prompt learning framework. On the one hand, to maximize the complementarity of tasks with high similarity, we utilize a gradient-driven task grouping method that partitions tasks into several disjoint groups and assign a group-shared MmAP to each group. On the other hand, to preserve the unique characteristics of each task, we assign an task-specific MmAP to each task. Comprehensive experiments on two large multi-task learning datasets demonstrate that our method achieves significant performance improvements compared to full fine-tuning while only utilizing approximately 0.09% of trainable parameters.
Seeing in Flowing: Adapting CLIP for Action Recognition with Motion Prompts Learning
Aug 09, 2023The Contrastive Language-Image Pre-training (CLIP) has recently shown remarkable generalization on "zero-shot" training and has applied to many downstream tasks. We explore the adaptation of CLIP to achieve a more efficient and generalized action recognition method. We propose that the key lies in explicitly modeling the motion cues flowing in video frames. To that end, we design a two-stream motion modeling block to capture motion and spatial information at the same time. And then, the obtained motion cues are utilized to drive a dynamic prompts learner to generate motion-aware prompts, which contain much semantic information concerning human actions. In addition, we propose a multimodal communication block to achieve a collaborative learning and further improve the performance. We conduct extensive experiments on HMDB-51, UCF-101, and Kinetics-400 datasets. Our method outperforms most existing state-of-the-art methods by a significant margin on "few-shot" and "zero-shot" training. We also achieve competitive performance on "closed-set" training with extremely few trainable parameters and additional computational costs.
NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination
Jul 27, 2020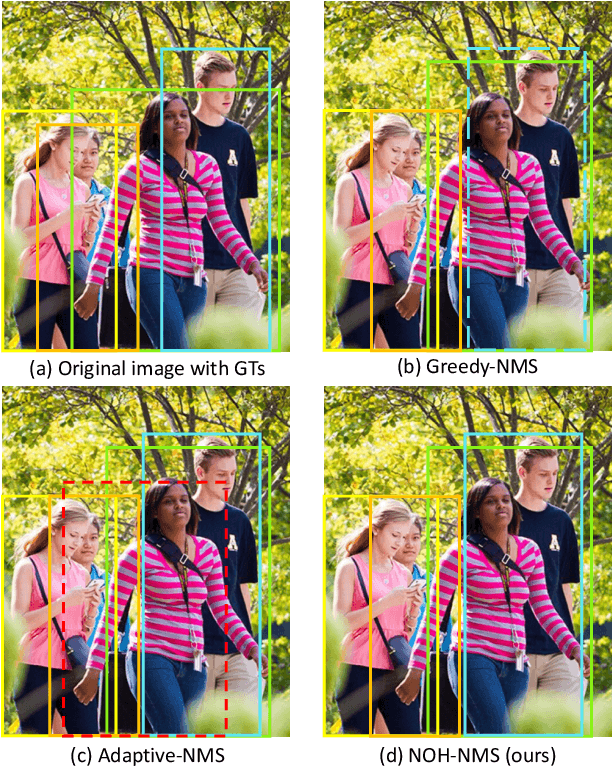
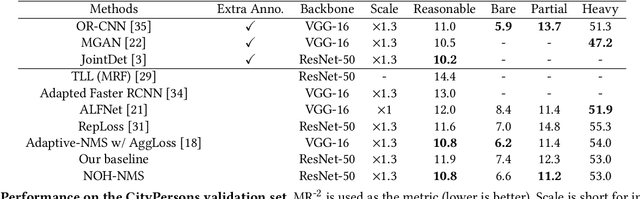

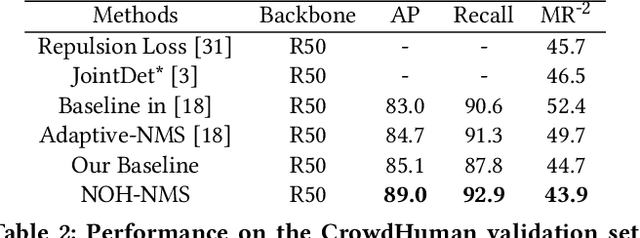
Greedy-NMS inherently raises a dilemma, where a lower NMS threshold will potentially lead to a lower recall rate and a higher threshold introduces more false positives. This problem is more severe in pedestrian detection because the instance density varies more intensively. However, previous works on NMS don't consider or vaguely consider the factor of the existent of nearby pedestrians. Thus, we propose Nearby Objects Hallucinator (NOH), which pinpoints the objects nearby each proposal with a Gaussian distribution, together with NOH-NMS, which dynamically eases the suppression for the space that might contain other objects with a high likelihood. Compared to Greedy-NMS, our method, as the state-of-the-art, improves by $3.9\%$ AP, $5.1\%$ Recall, and $0.8\%$ $\text{MR}^{-2}$ on CrowdHuman to $89.0\%$ AP and $92.9\%$ Recall, and $43.9\%$ $\text{MR}^{-2}$ respectively.