 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
Jan 06, 2025Image diffusion models have been adapted for real-world video super-resolution to tackle over-smoothing issues in GAN-based methods. However, these models struggle to maintain temporal consistency, as they are trained on static images, limiting their ability to capture temporal dynamics effectively. Integrating text-to-video (T2V) models into video super-resolution for improved temporal modeling is straightforward. However, two key challenges remain: artifacts introduced by complex degradations in real-world scenarios, and compromised fidelity due to the strong generative capacity of powerful T2V models (\textit{e.g.}, CogVideoX-5B). To enhance the spatio-temporal quality of restored videos, we introduce\textbf{~\name} (\textbf{S}patial-\textbf{T}emporal \textbf{A}ugmentation with T2V models for \textbf{R}eal-world video super-resolution), a novel approach that leverages T2V models for real-world video super-resolution, achieving realistic spatial details and robust temporal consistency. Specifically, we introduce a Local Information Enhancement Module (LIEM) before the global attention block to enrich local details and mitigate degradation artifacts. Moreover, we propose a Dynamic Frequency (DF) Loss to reinforce fidelity, guiding the model to focus on different frequency components across diffusion steps. Extensive experiments demonstrate\textbf{~\name}~outperforms state-of-the-art methods on both synthetic and real-world datasets.
InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
Dec 12, 2024



Text-to-video generation has evolved rapidly in recent years, delivering remarkable results. Training typically relies on video-caption paired data, which plays a crucial role in enhancing generation performance. However, current video captions often suffer from insufficient details, hallucinations and imprecise motion depiction, affecting the fidelity and consistency of generated videos. In this work, we propose a novel instance-aware structured caption framework, termed InstanceCap, to achieve instance-level and fine-grained video caption for the first time. Based on this scheme, we design an auxiliary models cluster to convert original video into instances to enhance instance fidelity. Video instances are further used to refine dense prompts into structured phrases, achieving concise yet precise descriptions. Furthermore, a 22K InstanceVid dataset is curated for training, and an enhancement pipeline that tailored to InstanceCap structure is proposed for inference. Experimental results demonstrate that our proposed InstanceCap significantly outperform previous models, ensuring high fidelity between captions and videos while reducing hallucinations.
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Jul 02, 2024



Text-to-video (T2V) generation has recently garnered significant attention thanks to the large multi-modality model Sora. However, T2V generation still faces two important challenges: 1) Lacking a precise open sourced high-quality dataset. The previous popular video datasets, e.g. WebVid-10M and Panda-70M, are either with low quality or too large for most research institutions. Therefore, it is challenging but crucial to collect a precise high-quality text-video pairs for T2V generation. 2) Ignoring to fully utilize textual information. Recent T2V methods have focused on vision transformers, using a simple cross attention module for video generation, which falls short of thoroughly extracting semantic information from text prompt. To address these issues, we introduce OpenVid-1M, a precise high-quality dataset with expressive captions. This open-scenario dataset contains over 1 million text-video pairs, facilitating research on T2V generation. Furthermore, we curate 433K 1080p videos from OpenVid-1M to create OpenVidHD-0.4M, advancing high-definition video generation. Additionally, we propose a novel Multi-modal Video Diffusion Transformer (MVDiT) capable of mining both structure information from visual tokens and semantic information from text tokens. Extensive experiments and ablation studies verify the superiority of OpenVid-1M over previous datasets and the effectiveness of our MVDiT.
PR-Net: Preference Reasoning for Personalized Video Highlight Detection
Sep 04, 2021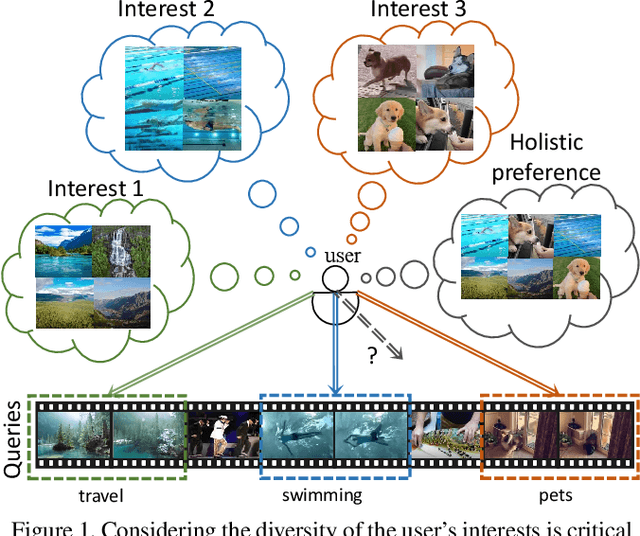
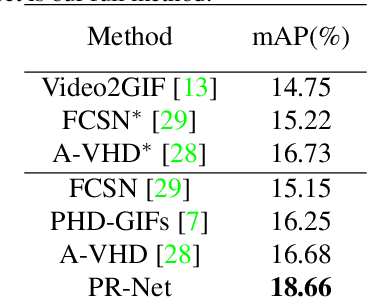
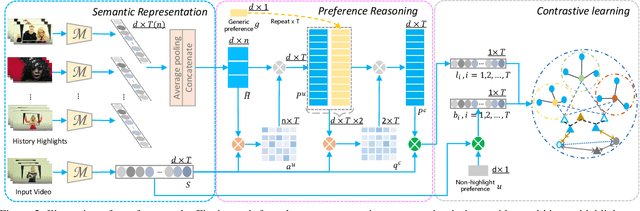
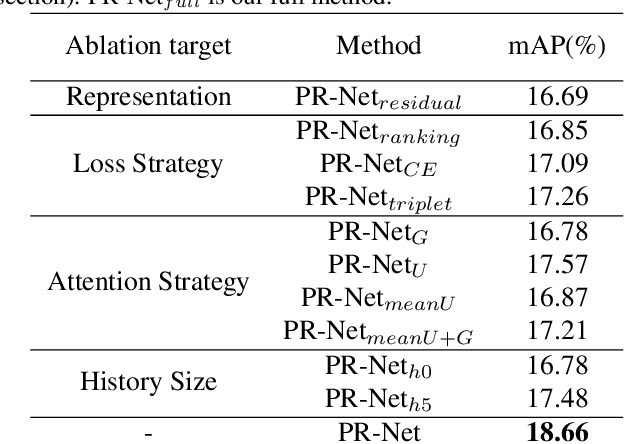
Personalized video highlight detection aims to shorten a long video to interesting moments according to a user's preference, which has recently raised the community's attention. Current methods regard the user's history as holistic information to predict the user's preference but negating the inherent diversity of the user's interests, resulting in vague preference representation. In this paper, we propose a simple yet efficient preference reasoning framework (PR-Net) to explicitly take the diverse interests into account for frame-level highlight prediction. Specifically, distinct user-specific preferences for each input query frame are produced, presented as the similarity weighted sum of history highlights to the corresponding query frame. Next, distinct comprehensive preferences are formed by the user-specific preferences and a learnable generic preference for more overall highlight measurement. Lastly, the degree of highlight and non-highlight for each query frame is calculated as semantic similarity to its comprehensive and non-highlight preferences, respectively. Besides, to alleviate the ambiguity due to the incomplete annotation, a new bi-directional contrastive loss is proposed to ensure a compact and differentiable metric space. In this way, our method significantly outperforms state-of-the-art methods with a relative improvement of 12% in mean accuracy precision.
NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination
Jul 27, 2020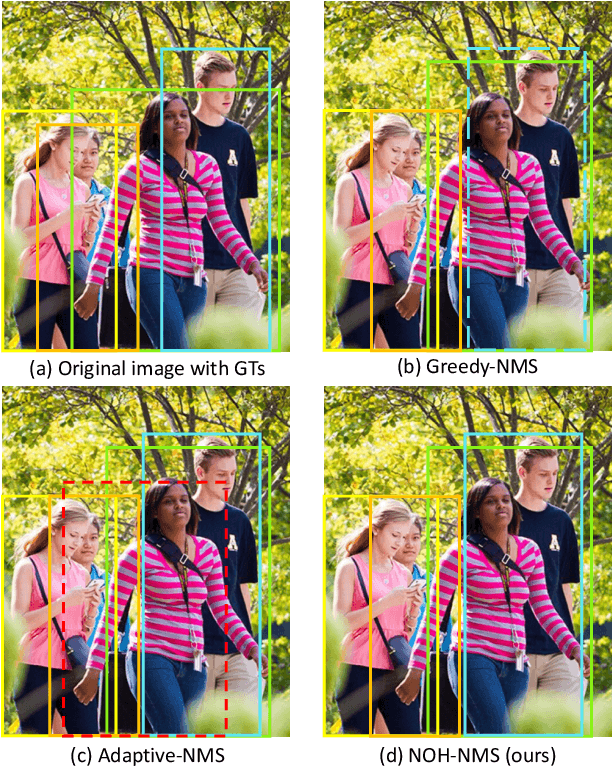
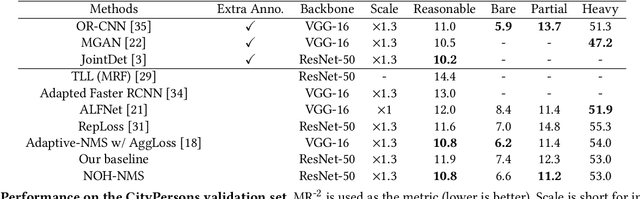

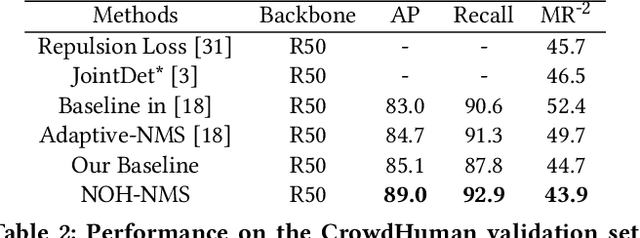
Greedy-NMS inherently raises a dilemma, where a lower NMS threshold will potentially lead to a lower recall rate and a higher threshold introduces more false positives. This problem is more severe in pedestrian detection because the instance density varies more intensively. However, previous works on NMS don't consider or vaguely consider the factor of the existent of nearby pedestrians. Thus, we propose Nearby Objects Hallucinator (NOH), which pinpoints the objects nearby each proposal with a Gaussian distribution, together with NOH-NMS, which dynamically eases the suppression for the space that might contain other objects with a high likelihood. Compared to Greedy-NMS, our method, as the state-of-the-art, improves by $3.9\%$ AP, $5.1\%$ Recall, and $0.8\%$ $\text{MR}^{-2}$ on CrowdHuman to $89.0\%$ AP and $92.9\%$ Recall, and $43.9\%$ $\text{MR}^{-2}$ respectively.