 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotDesignGPT: Automated Robot Design Synthesis using Vision Language Models
Jan 16, 2026Robot design is a nontrivial process that involves careful consideration of multiple criteria, including user specifications, kinematic structures, and visual appearance. Therefore, the design process often relies heavily on domain expertise and significant human effort. The majority of current methods are rule-based, requiring the specification of a grammar or a set of primitive components and modules that can be composed to create a design. We propose a novel automated robot design framework, RobotDesignGPT, that leverages the general knowledge and reasoning capabilities of large pre-trained vision-language models to automate the robot design synthesis process. Our framework synthesizes an initial robot design from a simple user prompt and a reference image. Our novel visual feedback approach allows us to greatly improve the design quality and reduce unnecessary manual feedback. We demonstrate that our framework can design visually appealing and kinematically valid robots inspired by nature, ranging from legged animals to flying creatures. We justify the proposed framework by conducting an ablation study and a user study.
BayRnTune: Adaptive Bayesian Domain Randomization via Strategic Fine-tuning
Oct 16, 2023Domain randomization (DR), which entails training a policy with randomized dynamics, has proven to be a simple yet effective algorithm for reducing the gap between simulation and the real world. However, DR often requires careful tuning of randomization parameters. Methods like Bayesian Domain Randomization (Bayesian DR) and Active Domain Randomization (Adaptive DR) address this issue by automating parameter range selection using real-world experience. While effective, these algorithms often require long computation time, as a new policy is trained from scratch every iteration. In this work, we propose Adaptive Bayesian Domain Randomization via Strategic Fine-tuning (BayRnTune), which inherits the spirit of BayRn but aims to significantly accelerate the learning processes by fine-tuning from previously learned policy. This idea leads to a critical question: which previous policy should we use as a prior during fine-tuning? We investigated four different fine-tuning strategies and compared them against baseline algorithms in five simulated environments, ranging from simple benchmark tasks to more complex legged robot environments. Our analysis demonstrates that our method yields better rewards in the same amount of timesteps compared to vanilla domain randomization or Bayesian DR.
Words into Action: Learning Diverse Humanoid Robot Behaviors using Language Guided Iterative Motion Refinement
Oct 10, 2023Humanoid robots are well suited for human habitats due to their morphological similarity, but developing controllers for them is a challenging task that involves multiple sub-problems, such as control, planning and perception. In this paper, we introduce a method to simplify controller design by enabling users to train and fine-tune robot control policies using natural language commands. We first learn a neural network policy that generates behaviors given a natural language command, such as "walk forward", by combining Large Language Models (LLMs), motion retargeting, and motion imitation. Based on the synthesized motion, we iteratively fine-tune by updating the text prompt and querying LLMs to find the best checkpoint associated with the closest motion in history. We validate our approach using a simulated Digit humanoid robot and demonstrate learning of diverse motions, such as walking, hopping, and kicking, without the burden of complex reward engineering. In addition, we show that our iterative refinement enables us to learn 3x times faster than a naive formulation that learns from scratch.
Cascaded Compositional Residual Learning for Complex Interactive Behaviors
Dec 17, 2022
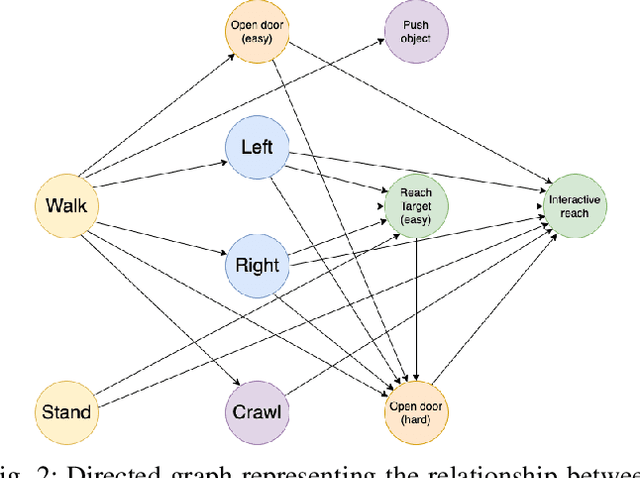
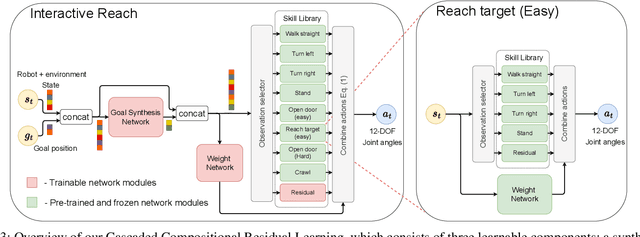

Real-world autonomous missions often require rich interaction with nearby objects, such as doors or switches, along with effective navigation. However, such complex behaviors are difficult to learn because they involve both high-level planning and low-level motor control. We present a novel framework, Cascaded Compositional Residual Learning (CCRL), which learns composite skills by recursively leveraging a library of previously learned control policies. Our framework learns multiplicative policy composition, task-specific residual actions, and synthetic goal information simultaneously while freezing the prerequisite policies. We further explicitly control the style of the motion by regularizing residual actions. We show that our framework learns joint-level control policies for a diverse set of motor skills ranging from basic locomotion to complex interactive navigation, including navigating around obstacles, pushing objects, crawling under a table, pushing a door open with its leg, and holding it open while walking through it. The proposed CCRL framework leads to policies with consistent styles and lower joint torques, which we successfully transfer to a real Unitree A1 robot without any additional fine-tuning.
Graph-based Cluttered Scene Generation and Interactive Exploration using Deep Reinforcement Learning
Sep 21, 2021
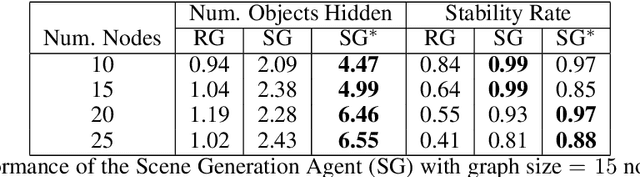
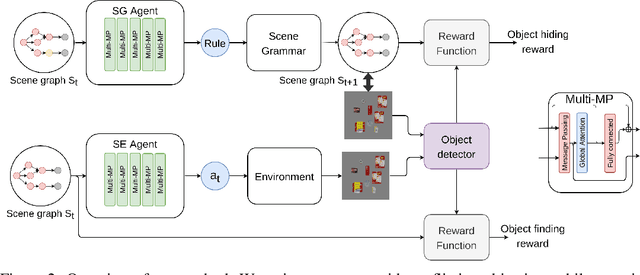
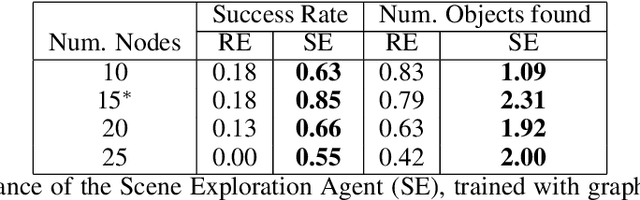
We introduce a novel method to teach a robotic agent to interactively explore cluttered yet structured scenes, such as kitchen pantries and grocery shelves, by leveraging the physical plausibility of the scene. We propose a novel learning framework to train an effective scene exploration policy to discover hidden objects with minimal interactions. First, we define a novel scene grammar to represent structured clutter. Then we train a Graph Neural Network (GNN) based Scene Generation agent using deep reinforcement learning (deep RL), to manipulate this Scene Grammar to create a diverse set of stable scenes, each containing multiple hidden objects. Given such cluttered scenes, we then train a Scene Exploration agent, using deep RL, to uncover hidden objects by interactively rearranging the scene. We show that our learned agents hide and discover significantly more objects than the baselines. We present quantitative results that prove the generalization capabilities of our agents. We also demonstrate sim-to-real transfer by successfully deploying the learned policy on a real UR10 robot to explore real-world cluttered scenes. The supplemental video can be found at https://www.youtube.com/watch?v=T2Jo7wwaXss.