 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Reinforcement Learning for Path Planning in Constrained Parking Scenarios
Jan 30, 2026Real-time path planning in constrained environments remains a fundamental challenge for autonomous systems. Traditional classical planners, while effective under perfect perception assumptions, are often sensitive to real-world perception constraints and rely on online search procedures that incur high computational costs. In complex surroundings, this renders real-time deployment prohibitive. To overcome these limitations, we introduce a Deep Reinforcement Learning (DRL) framework for real-time path planning in parking scenarios. In particular, we focus on challenging scenes with tight spaces that require a high number of reversal maneuvers and adjustments. Unlike classical planners, our solution does not require ideal and structured perception, and in principle, could avoid the need for additional modules such as localization and tracking, resulting in a simpler and more practical implementation. Also, at test time, the policy generates actions through a single forward pass at each step, which is lightweight enough for real-time deployment. The task is formulated as a sequential decision-making problem grounded in a bicycle model dynamics, enabling the agent to directly learn navigation policies that respect vehicle kinematics and environmental constraints in the closed-loop setting. A new benchmark is developed to support both training and evaluation, capturing diverse and challenging scenarios. Our approach achieves state-of-the-art success rates and efficiency, surpassing classical planner baselines by +96% in success rate and +52% in efficiency. Furthermore, we release our benchmark as an open-source resource for the community to foster future research in autonomous systems. The benchmark and accompanying tools are available at https://github.com/dqm5rtfg9b-collab/Constrained_Parking_Scenarios.
Learning a Single Policy for Diverse Behaviors on a Quadrupedal Robot using Scalable Motion Imitation
Mar 27, 2023



Learning various motor skills for quadrupedal robots is a challenging problem that requires careful design of task-specific mathematical models or reward descriptions. In this work, we propose to learn a single capable policy using deep reinforcement learning by imitating a large number of reference motions, including walking, turning, pacing, jumping, sitting, and lying. On top of the existing motion imitation framework, we first carefully design the observation space, the action space, and the reward function to improve the scalability of the learning as well as the robustness of the final policy. In addition, we adopt a novel adaptive motion sampling (AMS) method, which maintains a balance between successful and unsuccessful behaviors. This technique allows the learning algorithm to focus on challenging motor skills and avoid catastrophic forgetting. We demonstrate that the learned policy can exhibit diverse behaviors in simulation by successfully tracking both the training dataset and out-of-distribution trajectories. We also validate the importance of the proposed learning formulation and the adaptive motion sampling scheme by conducting experiments.
Finite State Machine Policies Modulating Trajectory Generator
Sep 26, 2021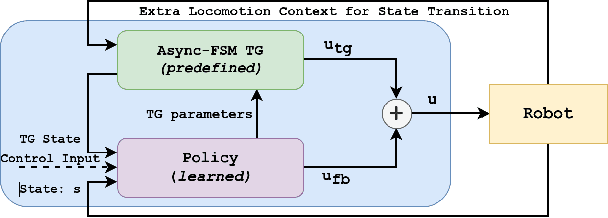
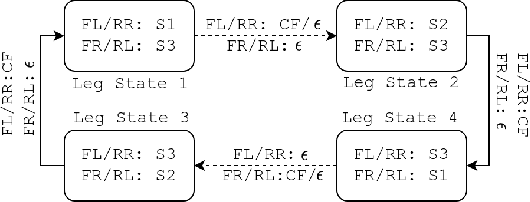
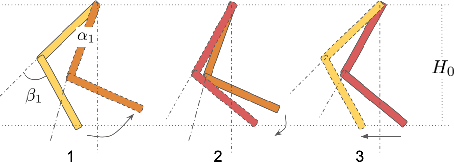

Deep reinforcement learning (deep RL) has emerged as an effective tool for developing controllers for legged robots. However, a simple neural network representation is known for its poor extrapolation ability, making the learned behavior vulnerable to unseen perturbations or challenging terrains. Therefore, researchers have investigated a novel architecture, Policies Modulating Trajectory Generators (PMTG), which combines trajectory generators (TG) and feedback control signals to achieve more robust behaviors. In this work, we propose to extend the PMTG framework with a finite state machine PMTG by replacing simple TGs with asynchronous finite state machines (Async FSMs). This invention offers an explicit notion of contact events to the policy to negotiate unexpected perturbations. We demonstrated that the proposed architecture could achieve more robust behaviors in various scenarios, such as challenging terrains or external perturbations, on both simulated and real robots. The supplemental video can be found at: http://youtu.be/XUiTSZaM8f0.
Application of Yolo on Mask Detection Task
Feb 10, 2021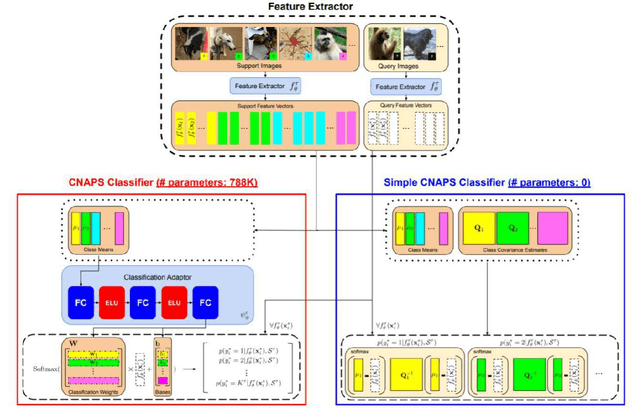
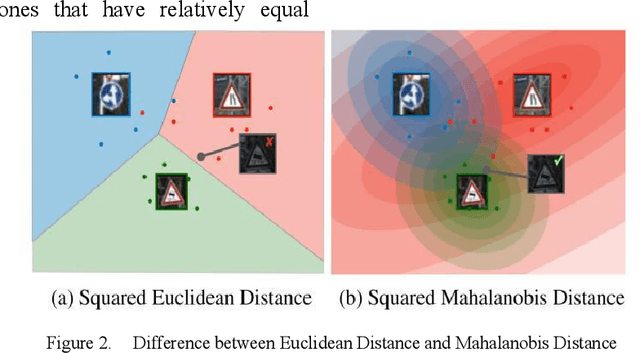
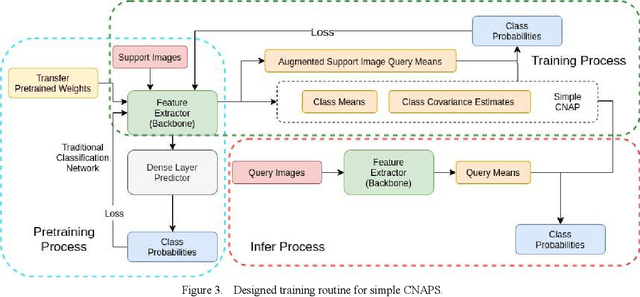
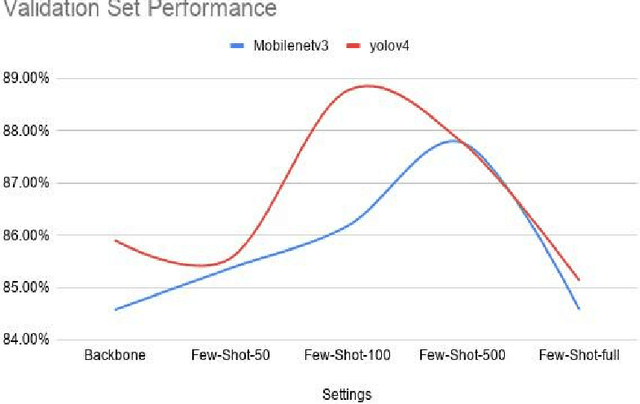
2020 has been a year marked by the COVID-19 pandemic. This event has caused disruptions to many aspects of normal life. An important aspect in reducing the impact of the pandemic is to control its spread. Studies have shown that one effective method in reducing the transmission of COVID-19 is to wear masks. Strict mask-wearing policies have been met with not only public sensation but also practical difficulty. We cannot hope to manually check if everyone on a street is wearing a mask properly. Existing technology to help automate mask checking uses deep learning models on real-time surveillance camera footages. The current dominant method to perform real-time mask detection uses Mask-RCNN with ResNet as the backbone. While giving good detection results, this method is computationally intensive and its efficiency in real-time face mask detection is not ideal. Our research proposes a new approach to mask detection by replacing Mask-R-CNN with a more efficient model "YOLO" to increase the processing speed of real-time mask detection and not compromise on accuracy. Besides, given the small volume as well as extreme imbalance of the mask detection datasets, we adopt a latest progress made in few-shot visual classification, simple CNAPs, to improve the classification performance.
Semi-Implicit Back Propagation
Feb 10, 2020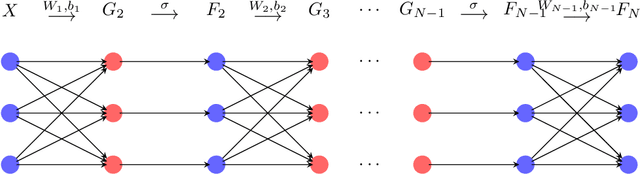
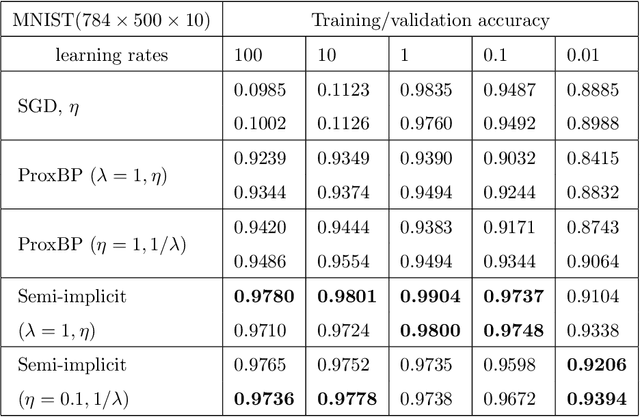
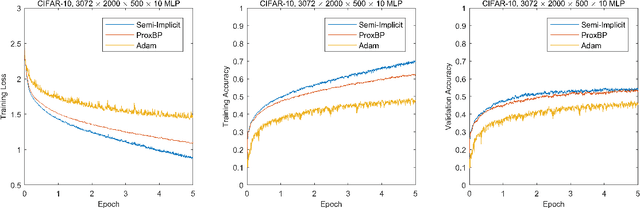
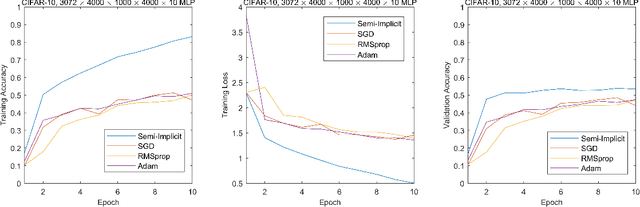
Neural network has attracted great attention for a long time and many researchers are devoted to improve the effectiveness of neural network training algorithms. Though stochastic gradient descent (SGD) and other explicit gradient-based methods are widely adopted, there are still many challenges such as gradient vanishing and small step sizes, which leads to slow convergence and instability of SGD algorithms. Motivated by error back propagation (BP) and proximal methods, we propose a semi-implicit back propagation method for neural network training. Similar to BP, the difference on the neurons are propagated in a backward fashion and the parameters are updated with proximal mapping. The implicit update for both hidden neurons and parameters allows to choose large step size in the training algorithm. Finally, we also show that any fixed point of convergent sequences produced by this algorithm is a stationary point of the objective loss function. The experiments on both MNIST and CIFAR-10 demonstrate that the proposed semi-implicit BP algorithm leads to better performance in terms of both loss decreasing and training/validation accuracy, compared to SGD and a similar algorithm ProxBP.
Fast Calculation of Probabilistic Optimal Power Flow: A Deep Learning Approach
Jun 24, 2019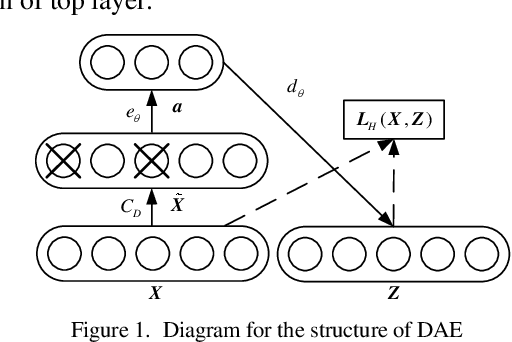
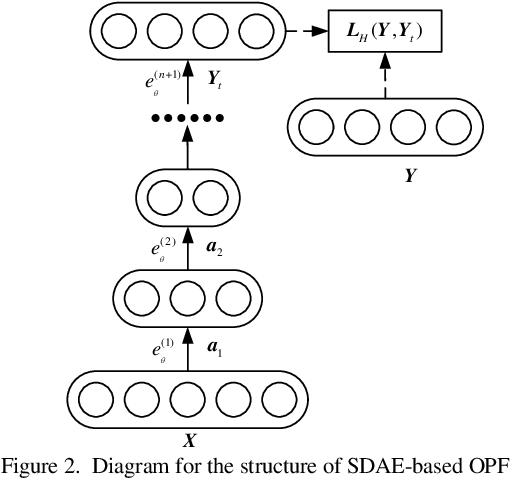
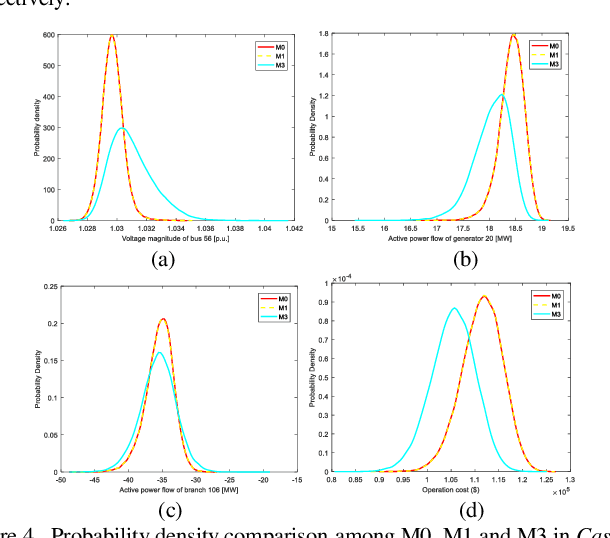
Probabilistic optimal power flow (POPF) is an important analytical tool to ensure the secure and economic operation of power systems. POPF needs to solve enormous nonlinear and nonconvex optimization problems. The huge computational burden has become the major bottleneck for the practical application. This paper presents a deep learning approach to solve the POPF problem efficiently and accurately. Taking advantage of the deep structure and reconstructive strategy of stacked denoising auto encoders (SDAE), a SDAE-based optimal power flow (OPF) is developed to extract the high-level nonlinear correlations between the system operating condition and the OPF solution. A training process is designed to learn the feature of POPF. The trained SDAE network can be utilized to conveniently calculate the OPF solution of random samples generated by Monte-Carlo simulation (MCS) without the need of optimization. A modified IEEE 118-bus power system is simulated to demonstrate the effectiveness of the proposed method.