 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Perception Dataset of In-water Objects for Autonomous Surface Vehicles
Apr 29, 2024



This paper introduces the first publicly accessible multi-modal perception dataset for autonomous maritime navigation, focusing on in-water obstacles within the aquatic environment to enhance situational awareness for Autonomous Surface Vehicles (ASVs). This dataset, consisting of diverse objects encountered under varying environmental conditions, aims to bridge the research gap in marine robotics by providing a multi-modal, annotated, and ego-centric perception dataset, for object detection and classification. We also show the applicability of the proposed dataset's framework using deep learning-based open-source perception algorithms that have shown success. We expect that our dataset will contribute to development of the marine autonomy pipeline and marine (field) robotics. Please note this is a work-in-progress paper about our on-going research that we plan to release in full via future publication.
Improving the perception of visual fiducial markers in the field using Adaptive Active Exposure Control
Apr 18, 2024



Accurate localization is fundamental for autonomous underwater vehicles (AUVs) to carry out precise tasks, such as manipulation and construction. Vision-based solutions using fiducial marker are promising, but extremely challenging underwater because of harsh lighting condition underwater. This paper introduces a gradient-based active camera exposure control method to tackle sharp lighting variations during image acquisition, which can establish better foundation for subsequent image enhancement procedures. Considering a typical scenario for underwater operations where visual tags are used, we proposed several experiments comparing our method with other state-of-the-art exposure control method including Active Exposure Control (AEC) and Gradient-based Exposure Control (GEC). Results show a significant improvement in the accuracy of robot localization. This method is an important component that can be used in visual-based state estimation pipeline to improve the overall localization accuracy.
Efflex: Efficient and Flexible Pipeline for Spatio-Temporal Trajectory Graph Modeling and Representation Learning
Apr 15, 2024



In the landscape of spatio-temporal data analytics, effective trajectory representation learning is paramount. To bridge the gap of learning accurate representations with efficient and flexible mechanisms, we introduce Efflex, a comprehensive pipeline for transformative graph modeling and representation learning of the large-volume spatio-temporal trajectories. Efflex pioneers the incorporation of a multi-scale k-nearest neighbors (KNN) algorithm with feature fusion for graph construction, marking a leap in dimensionality reduction techniques by preserving essential data features. Moreover, the groundbreaking graph construction mechanism and the high-performance lightweight GCN increase embedding extraction speed by up to 36 times faster. We further offer Efflex in two versions, Efflex-L for scenarios demanding high accuracy, and Efflex-B for environments requiring swift data processing. Comprehensive experimentation with the Porto and Geolife datasets validates our approach, positioning Efflex as the state-of-the-art in the domain. Such enhancements in speed and accuracy highlight the versatility of Efflex, underscoring its wide-ranging potential for deployment in time-sensitive and computationally constrained applications.
Application of Yolo on Mask Detection Task
Feb 10, 2021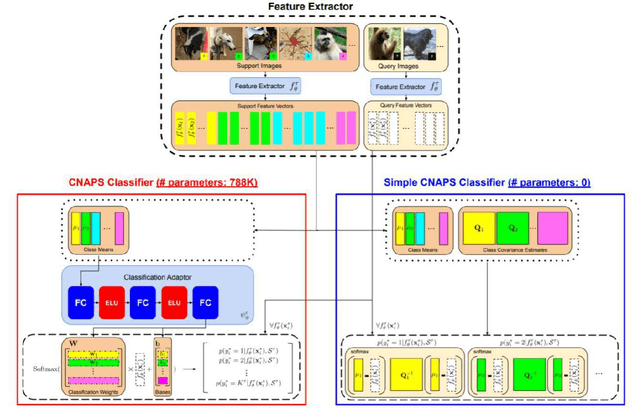
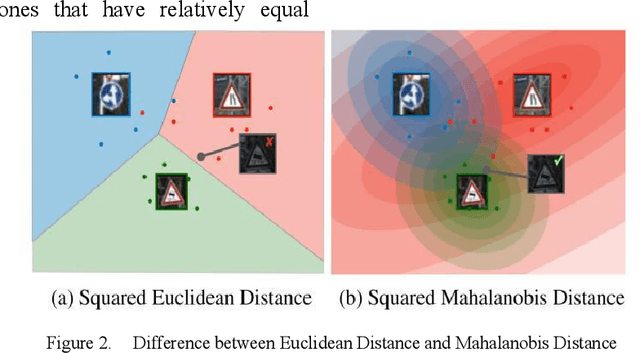
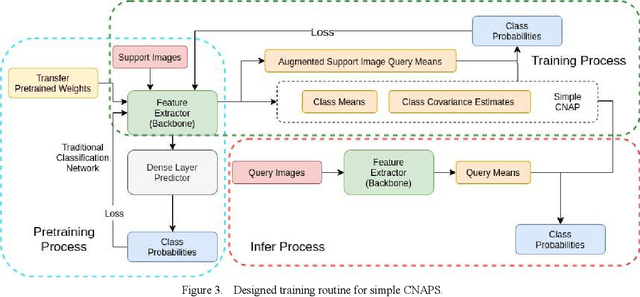
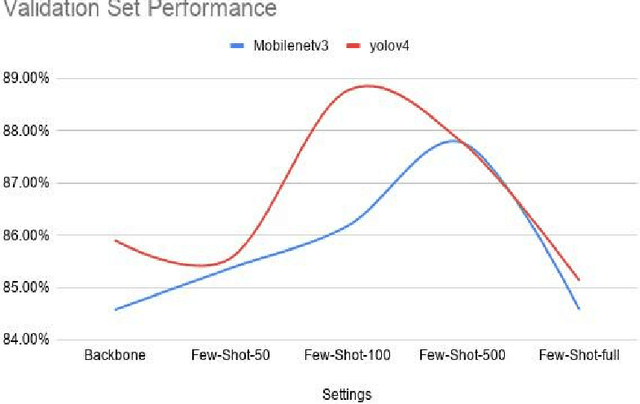
2020 has been a year marked by the COVID-19 pandemic. This event has caused disruptions to many aspects of normal life. An important aspect in reducing the impact of the pandemic is to control its spread. Studies have shown that one effective method in reducing the transmission of COVID-19 is to wear masks. Strict mask-wearing policies have been met with not only public sensation but also practical difficulty. We cannot hope to manually check if everyone on a street is wearing a mask properly. Existing technology to help automate mask checking uses deep learning models on real-time surveillance camera footages. The current dominant method to perform real-time mask detection uses Mask-RCNN with ResNet as the backbone. While giving good detection results, this method is computationally intensive and its efficiency in real-time face mask detection is not ideal. Our research proposes a new approach to mask detection by replacing Mask-R-CNN with a more efficient model "YOLO" to increase the processing speed of real-time mask detection and not compromise on accuracy. Besides, given the small volume as well as extreme imbalance of the mask detection datasets, we adopt a latest progress made in few-shot visual classification, simple CNAPs, to improve the classification performance.