 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
Aug 07, 2024



Multimodal large language models (MLLMs) have extended the success of large language models (LLMs) to multiple data types, such as image, text and audio, achieving significant performance in various domains, including multimodal translation, visual question answering and content generation. Nonetheless, existing systems are inefficient to train MLLMs due to substantial GPU bubbles caused by the heterogeneous modality models and complex data dependencies in 3D parallelism. This paper proposes Optimus, a distributed MLLM training system that reduces end-to-end MLLM training time. Optimus is based on our principled analysis that scheduling the encoder computation within the LLM bubbles can reduce bubbles in MLLM training. To make scheduling encoder computation possible for all GPUs, Optimus searches the separate parallel plans for encoder and LLM, and adopts a bubble scheduling algorithm to enable exploiting LLM bubbles without breaking the original data dependencies in the MLLM model architecture. We further decompose encoder layer computation into a series of kernels, and analyze the common bubble pattern of 3D parallelism to carefully optimize the sub-millisecond bubble scheduling, minimizing the overall training time. Our experiments in a production cluster show that Optimus accelerates MLLM training by 20.5%-21.3% with ViT-22B and GPT-175B model over 3072 GPUs compared to baselines.
Efflex: Efficient and Flexible Pipeline for Spatio-Temporal Trajectory Graph Modeling and Representation Learning
Apr 15, 2024



In the landscape of spatio-temporal data analytics, effective trajectory representation learning is paramount. To bridge the gap of learning accurate representations with efficient and flexible mechanisms, we introduce Efflex, a comprehensive pipeline for transformative graph modeling and representation learning of the large-volume spatio-temporal trajectories. Efflex pioneers the incorporation of a multi-scale k-nearest neighbors (KNN) algorithm with feature fusion for graph construction, marking a leap in dimensionality reduction techniques by preserving essential data features. Moreover, the groundbreaking graph construction mechanism and the high-performance lightweight GCN increase embedding extraction speed by up to 36 times faster. We further offer Efflex in two versions, Efflex-L for scenarios demanding high accuracy, and Efflex-B for environments requiring swift data processing. Comprehensive experimentation with the Porto and Geolife datasets validates our approach, positioning Efflex as the state-of-the-art in the domain. Such enhancements in speed and accuracy highlight the versatility of Efflex, underscoring its wide-ranging potential for deployment in time-sensitive and computationally constrained applications.
VeTraSS: Vehicle Trajectory Similarity Search Through Graph Modeling and Representation Learning
Apr 11, 2024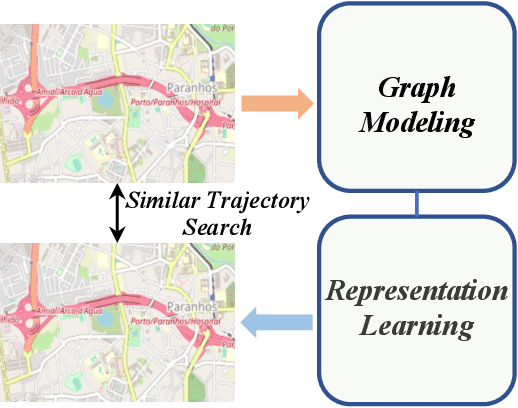

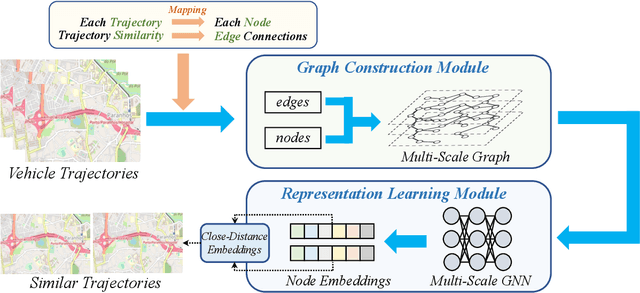

Trajectory similarity search plays an essential role in autonomous driving, as it enables vehicles to analyze the information and characteristics of different trajectories to make informed decisions and navigate safely in dynamic environments. Existing work on the trajectory similarity search task primarily utilizes sequence-processing algorithms or Recurrent Neural Networks (RNNs), which suffer from the inevitable issues of complicated architecture and heavy training costs. Considering the intricate connections between trajectories, using Graph Neural Networks (GNNs) for data modeling is feasible. However, most methods directly use existing mathematical graph structures as the input instead of constructing specific graphs from certain vehicle trajectory data. This ignores such data's unique and dynamic characteristics. To bridge such a research gap, we propose VeTraSS -- an end-to-end pipeline for Vehicle Trajectory Similarity Search. Specifically, VeTraSS models the original trajectory data into multi-scale graphs, and generates comprehensive embeddings through a novel multi-layer attention-based GNN. The learned embeddings can be used for searching similar vehicle trajectories. Extensive experiments on the Porto and Geolife datasets demonstrate the effectiveness of VeTraSS, where our model outperforms existing work and reaches the state-of-the-art. This demonstrates the potential of VeTraSS for trajectory analysis and safe navigation in self-driving vehicles in the real world.
CATP: Cross-Attention Token Pruning for Accuracy Preserved Multimodal Model Inference
Apr 02, 2024



In response to the rising interest in large multimodal models, we introduce Cross-Attention Token Pruning (CATP), a precision-focused token pruning method. Our approach leverages cross-attention layers in multimodal models, exemplified by BLIP-2, to extract valuable information for token importance determination. CATP employs a refined voting strategy across model heads and layers. In evaluations, CATP achieves up to 12.1X higher accuracy compared to existing token pruning methods, addressing the trade-off between computational efficiency and model precision.
Interpretable Math Word Problem Solution Generation Via Step-by-step Planning
Jun 01, 2023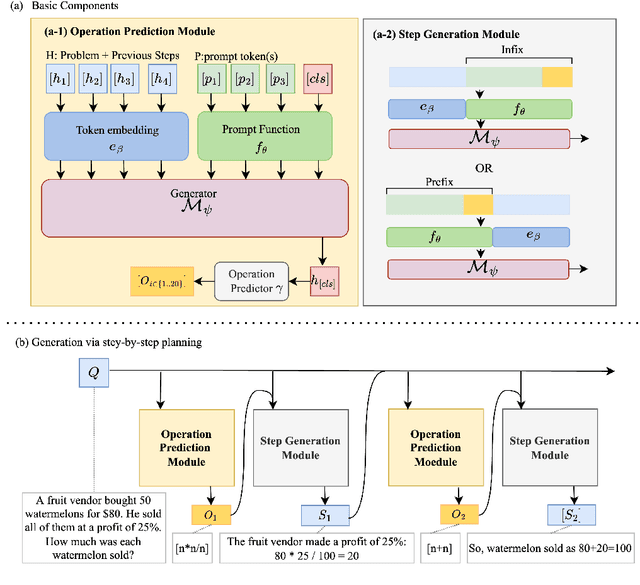
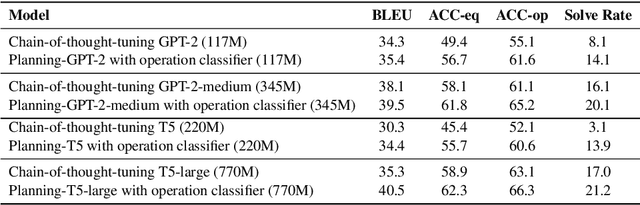
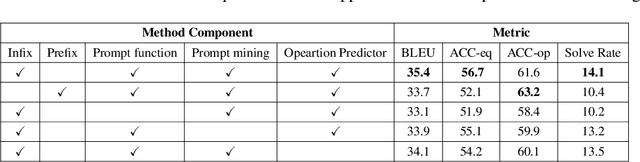
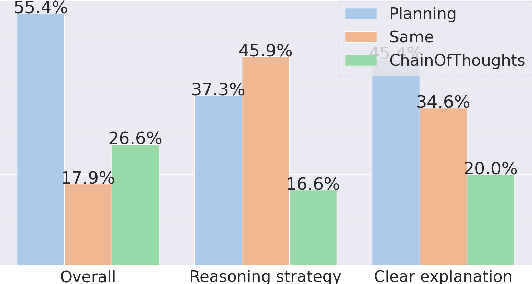
Solutions to math word problems (MWPs) with step-by-step explanations are valuable, especially in education, to help students better comprehend problem-solving strategies. Most existing approaches only focus on obtaining the final correct answer. A few recent approaches leverage intermediate solution steps to improve final answer correctness but often cannot generate coherent steps with a clear solution strategy. Contrary to existing work, we focus on improving the correctness and coherence of the intermediate solutions steps. We propose a step-by-step planning approach for intermediate solution generation, which strategically plans the generation of the next solution step based on the MWP and the previous solution steps. Our approach first plans the next step by predicting the necessary math operation needed to proceed, given history steps, then generates the next step, token-by-token, by prompting a language model with the predicted math operation. Experiments on the GSM8K dataset demonstrate that our approach improves the accuracy and interpretability of the solution on both automatic metrics and human evaluation.