 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unidirectionally Connected FAS Approach for 6-DOF Quadrotor Control
Oct 14, 2025This paper proposes a unidirectionally connected fully actuated system (UC-FAS) approach for the sub-stabilization and tracking control of 6-DOF quadrotors, tackling limitations both in state-space and FAS framework to some extent. The framework systematically converts underactuated quadrotor dynamics into a UC-FAS model, unifying the existing different FAS transformation ways. By eliminating estimation of the high-order derivatives of control inputs, a drawback of current methods, the UC-FAS model simplifies controller design and enables direct eigenstructure assignment for closed-loop dynamics. Simulations demonstrate precise 6-DOF tracking performance. This work bridges theoretical FAS approach advancements with practical implementation needs, offering a standardized paradigm for nonlinear quadrotor control.
Imagine, Verify, Execute: Memory-Guided Agentic Exploration with Vision-Language Models
May 12, 2025



Exploration is essential for general-purpose robotic learning, especially in open-ended environments where dense rewards, explicit goals, or task-specific supervision are scarce. Vision-language models (VLMs), with their semantic reasoning over objects, spatial relations, and potential outcomes, present a compelling foundation for generating high-level exploratory behaviors. However, their outputs are often ungrounded, making it difficult to determine whether imagined transitions are physically feasible or informative. To bridge the gap between imagination and execution, we present IVE (Imagine, Verify, Execute), an agentic exploration framework inspired by human curiosity. Human exploration is often driven by the desire to discover novel scene configurations and to deepen understanding of the environment. Similarly, IVE leverages VLMs to abstract RGB-D observations into semantic scene graphs, imagine novel scenes, predict their physical plausibility, and generate executable skill sequences through action tools. We evaluate IVE in both simulated and real-world tabletop environments. The results show that IVE enables more diverse and meaningful exploration than RL baselines, as evidenced by a 4.1 to 7.8x increase in the entropy of visited states. Moreover, the collected experience supports downstream learning, producing policies that closely match or exceed the performance of those trained on human-collected demonstrations.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PatentGPT: A Large Language Model for Intellectual Property
Apr 30, 2024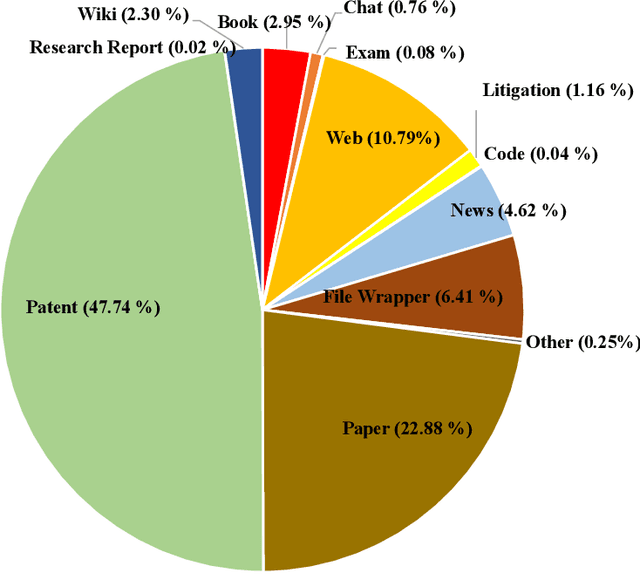

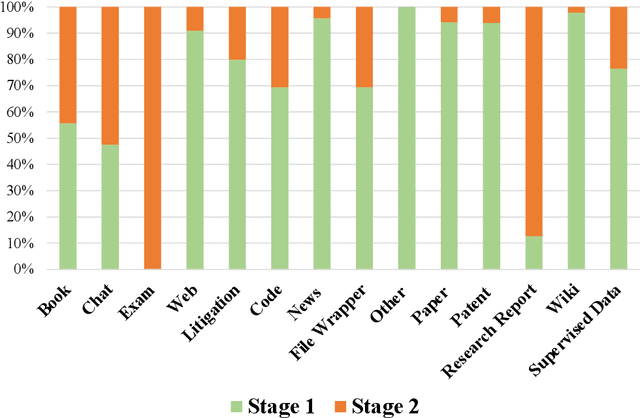
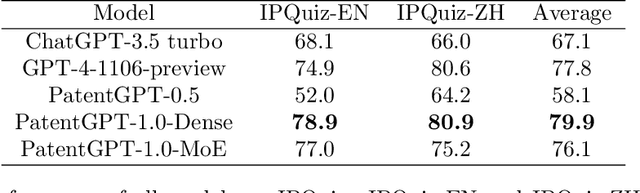
In recent years, large language models have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) space is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP demain. What is impressive is that our model significantly outperformed GPT-4 on the 2019 China Patent Agent Qualification Examination by achieving a score of 65, reaching the level of human experts. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.
Multi-modal Perception Dataset of In-water Objects for Autonomous Surface Vehicles
Apr 29, 2024



This paper introduces the first publicly accessible multi-modal perception dataset for autonomous maritime navigation, focusing on in-water obstacles within the aquatic environment to enhance situational awareness for Autonomous Surface Vehicles (ASVs). This dataset, consisting of diverse objects encountered under varying environmental conditions, aims to bridge the research gap in marine robotics by providing a multi-modal, annotated, and ego-centric perception dataset, for object detection and classification. We also show the applicability of the proposed dataset's framework using deep learning-based open-source perception algorithms that have shown success. We expect that our dataset will contribute to development of the marine autonomy pipeline and marine (field) robotics. Please note this is a work-in-progress paper about our on-going research that we plan to release in full via future publication.
Gait Cycle-Inspired Learning Strategy for Continuous Prediction of Knee Joint Trajectory from sEMG
Jul 25, 2023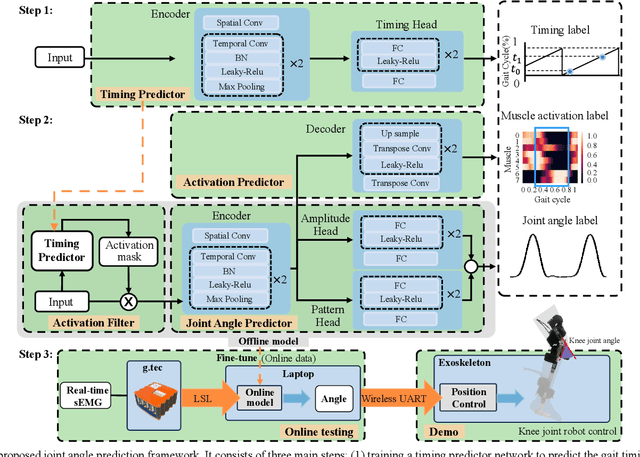
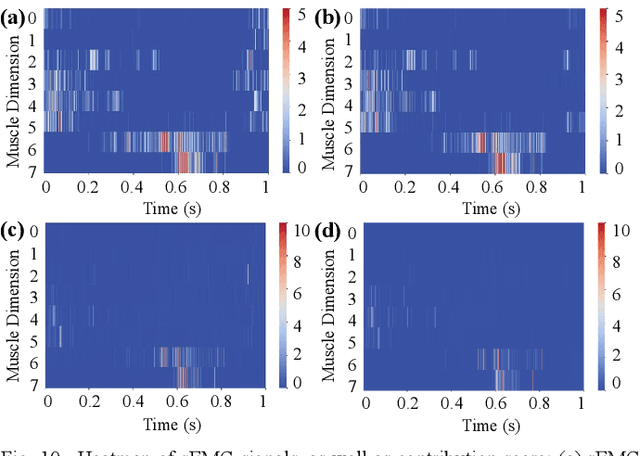
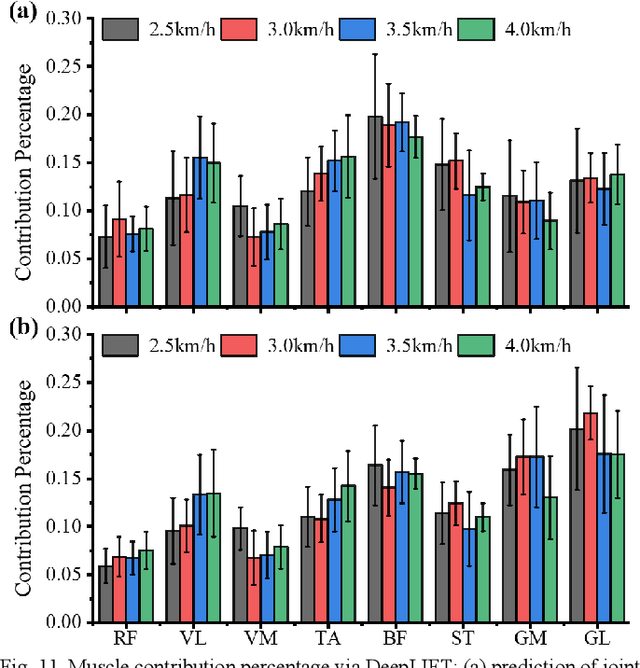
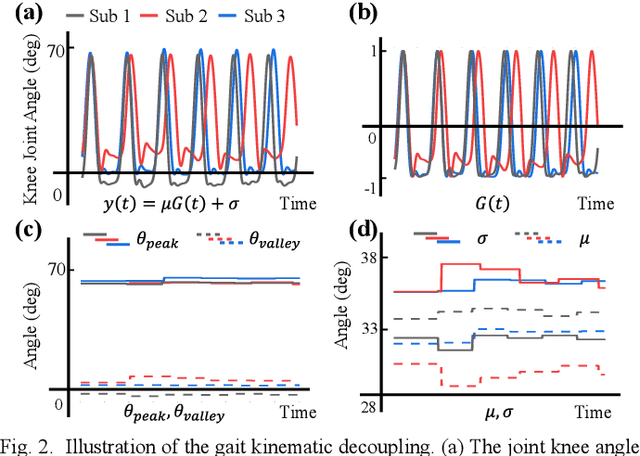
Predicting lower limb motion intent is vital for controlling exoskeleton robots and prosthetic limbs. Surface electromyography (sEMG) attracts increasing attention in recent years as it enables ahead-of-time prediction of motion intentions before actual movement. However, the estimation performance of human joint trajectory remains a challenging problem due to the inter- and intra-subject variations. The former is related to physiological differences (such as height and weight) and preferred walking patterns of individuals, while the latter is mainly caused by irregular and gait-irrelevant muscle activity. This paper proposes a model integrating two gait cycle-inspired learning strategies to mitigate the challenge for predicting human knee joint trajectory. The first strategy is to decouple knee joint angles into motion patterns and amplitudes former exhibit low variability while latter show high variability among individuals. By learning through separate network entities, the model manages to capture both the common and personalized gait features. In the second, muscle principal activation masks are extracted from gait cycles in a prolonged walk. These masks are used to filter out components unrelated to walking from raw sEMG and provide auxiliary guidance to capture more gait-related features. Experimental results indicate that our model could predict knee angles with the average root mean square error (RMSE) of 3.03(0.49) degrees and 50ms ahead of time. To our knowledge this is the best performance in relevant literatures that has been reported, with reduced RMSE by at least 9.5%.
Monocular Camera and Single-Beam Sonar-Based Underwater Collision-Free Navigation with Domain Randomization
Dec 08, 2022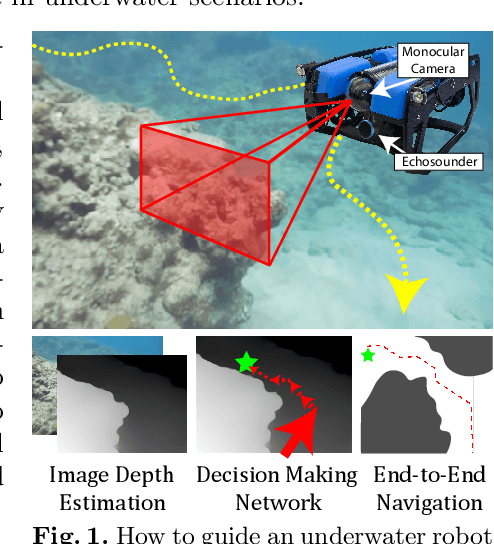

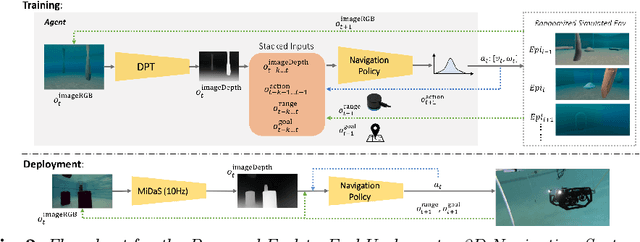

Underwater navigation presents several challenges, including unstructured unknown environments, lack of reliable localization systems (e.g., GPS), and poor visibility. Furthermore, good-quality obstacle detection sensors for underwater robots are scant and costly; and many sensors like RGB-D cameras and LiDAR only work in-air. To enable reliable mapless underwater navigation despite these challenges, we propose a low-cost end-to-end navigation system, based on a monocular camera and a fixed single-beam echo-sounder, that efficiently navigates an underwater robot to waypoints while avoiding nearby obstacles. Our proposed method is based on Proximal Policy Optimization (PPO), which takes as input current relative goal information, estimated depth images, echo-sounder readings, and previous executed actions, and outputs 3D robot actions in a normalized scale. End-to-end training was done in simulation, where we adopted domain randomization (varying underwater conditions and visibility) to learn a robust policy against noise and changes in visibility conditions. The experiments in simulation and real-world demonstrated that our proposed method is successful and resilient in navigating a low-cost underwater robot in unknown underwater environments. The implementation is made publicly available at https://github.com/dartmouthrobotics/deeprl-uw-robot-navigation.
DAFAR: Defending against Adversaries by Feedback-Autoencoder Reconstruction
Mar 17, 2021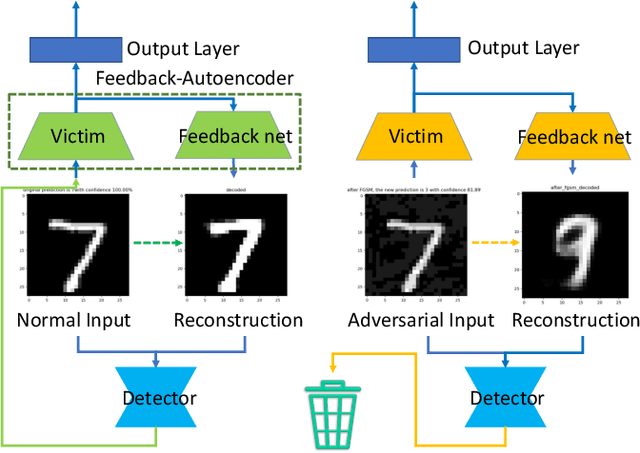
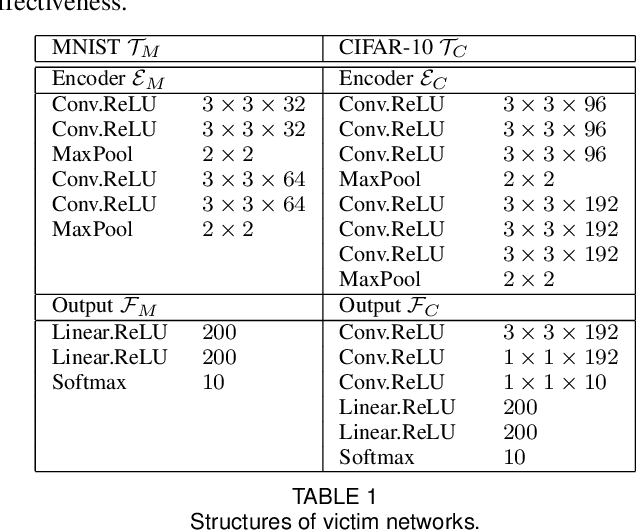
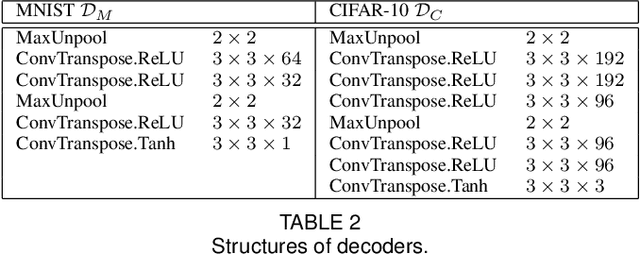
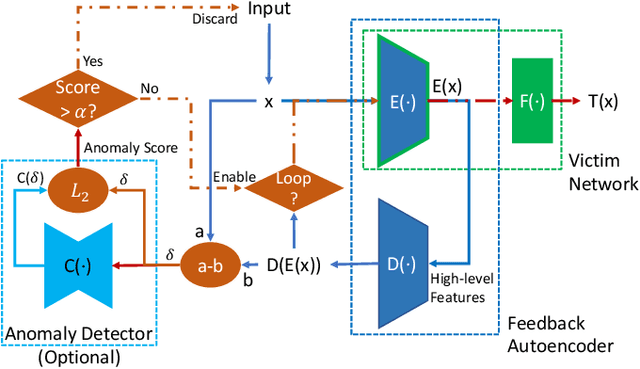
Deep learning has shown impressive performance on challenging perceptual tasks and has been widely used in software to provide intelligent services. However, researchers found deep neural networks vulnerable to adversarial examples. Since then, many methods are proposed to defend against adversaries in inputs, but they are either attack-dependent or shown to be ineffective with new attacks. And most of existing techniques have complicated structures or mechanisms that cause prohibitively high overhead or latency, impractical to apply on real software. We propose DAFAR, a feedback framework that allows deep learning models to detect/purify adversarial examples in high effectiveness and universality, with low area and time overhead. DAFAR has a simple structure, containing a victim model, a plug-in feedback network, and a detector. The key idea is to import the high-level features from the victim model's feature extraction layers into the feedback network to reconstruct the input. This data stream forms a feedback autoencoder. For strong attacks, it transforms the imperceptible attack on the victim model into the obvious reconstruction-error attack on the feedback autoencoder directly, which is much easier to detect; for weak attacks, the reformation process destroys the structure of adversarial examples. Experiments are conducted on MNIST and CIFAR-10 data-sets, showing that DAFAR is effective against popular and arguably most advanced attacks without losing performance on legitimate samples, with high effectiveness and universality across attack methods and parameters.