 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Multimodal Models Inspect Buildings? A Hierarchical Benchmark for Structural Pathology Reasoning
Mar 20, 2026Automated building facade inspection is a critical component of urban resilience and smart city maintenance. Traditionally, this field has relied on specialized discriminative models (e.g., YOLO, Mask R-CNN) that excel at pixel-level localization but are constrained to passive perception and worse generization without the visual understandng to interpret structural topology. Large Multimodal Models (LMMs) promise a paradigm shift toward active reasoning, yet their application in such high-stakes engineering domains lacks rigorous evaluation standards. To bridge this gap, we introduce a human-in-the-loop semi-automated annotation framework, leveraging expert-proposal verification to unify 12 fragmented datasets into a standardized, hierarchical ontology. Building on this foundation, we present \textit{DefectBench}, the first multi-dimensional benchmark designed to interrogate LMMs beyond basic semantic recognition. \textit{DefectBench} evaluates 18 state-of-the-art (SOTA) LMMs across three escalating cognitive dimensions: Semantic Perception, Spatial Localization, and Generative Geometry Segmentation. Extensive experiments reveal that while current LMMs demonstrate exceptional topological awareness and semantic understanding (effectively diagnosing "what" and "how"), they exhibit significant deficiencies in metric localization precision ("where"). Crucially, however, we validate the viability of zero-shot generative segmentation, showing that general-purpose foundation models can rival specialized supervised networks without domain-specific training. This work provides both a rigorous benchmarking standard and a high-quality open-source database, establishing a new baseline for the advancement of autonomous AI agents in civil engineering.
Synergistic Perception and Generative Recomposition: A Multi-Agent Orchestration for Expert-Level Building Inspection
Mar 20, 2026Building facade defect inspection is fundamental to structural health monitoring and sustainable urban maintenance, yet it remains a formidable challenge due to extreme geometric variability, low contrast against complex backgrounds, and the inherent complexity of composite defects (e.g., cracks co-occurring with spalling). Such characteristics lead to severe pixel imbalance and feature ambiguity, which, coupled with the critical scarcity of high-quality pixel-level annotations, hinder the generalization of existing detection and segmentation models. To address gaps, we propose \textit{FacadeFixer}, a unified multi-agent framework that treats defect perception as a collaborative reasoning task rather than isolated recognition. Specifically,\textit{FacadeFixer} orchestrates specialized agents for detection and segmentation to handle multi-type defect interference, working in tandem with a generative agent to enable semantic recomposition. This process decouples intricate defects from noisy backgrounds and realistically synthesizes them onto diverse clean textures, generating high-fidelity augmented data with precise expert-level masks. To support this, we introduce a comprehensive multi-task dataset covering six primary facade categories with pixel-level annotations. Extensive experiments demonstrate that \textit{FacadeFixer} significantly outperforms state-of-the-art (SOTA) baselines. Specifically, it excels in capturing pixel-level structural anomalies and highlights generative synthesis as a robust solution to data scarcity in infrastructure inspection. Our code and dataset will be made publicly available.
Progressive Attention Guidance for Whole Slide Vulvovaginal Candidiasis Screening
Sep 06, 2023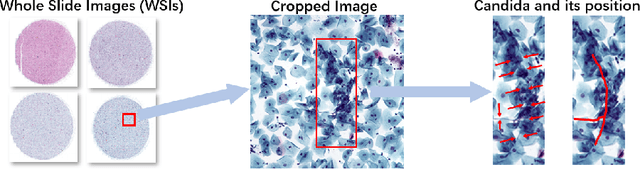
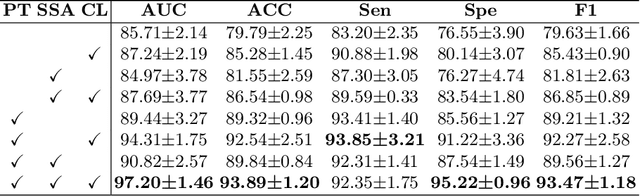
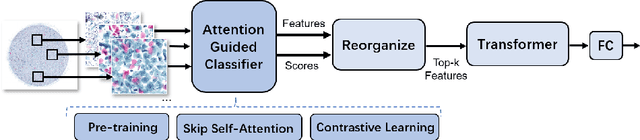
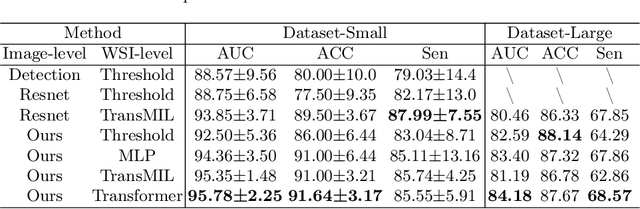
Vulvovaginal candidiasis (VVC) is the most prevalent human candidal infection, estimated to afflict approximately 75% of all women at least once in their lifetime. It will lead to several symptoms including pruritus, vaginal soreness, and so on. Automatic whole slide image (WSI) classification is highly demanded, for the huge burden of disease control and prevention. However, the WSI-based computer-aided VCC screening method is still vacant due to the scarce labeled data and unique properties of candida. Candida in WSI is challenging to be captured by conventional classification models due to its distinctive elongated shape, the small proportion of their spatial distribution, and the style gap from WSIs. To make the model focus on the candida easier, we propose an attention-guided method, which can obtain a robust diagnosis classification model. Specifically, we first use a pre-trained detection model as prior instruction to initialize the classification model. Then we design a Skip Self-Attention module to refine the attention onto the fined-grained features of candida. Finally, we use a contrastive learning method to alleviate the overfitting caused by the style gap of WSIs and suppress the attention to false positive regions. Our experimental results demonstrate that our framework achieves state-of-the-art performance. Code and example data are available at https://github.com/cjdbehumble/MICCAI2023-VVC-Screening.
* Accepted in the main conference MICCAI 2023
Gait Cycle-Inspired Learning Strategy for Continuous Prediction of Knee Joint Trajectory from sEMG
Jul 25, 2023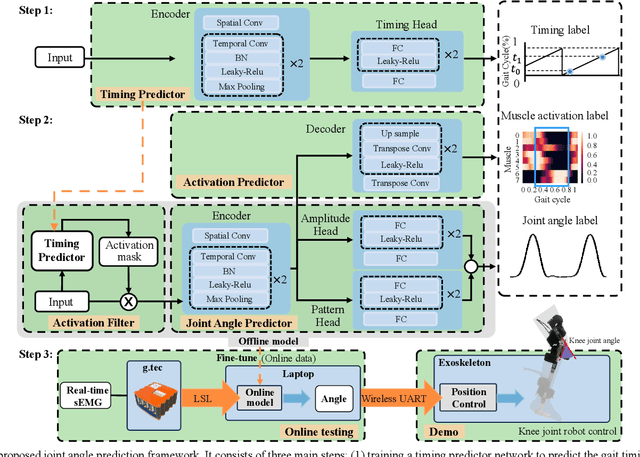
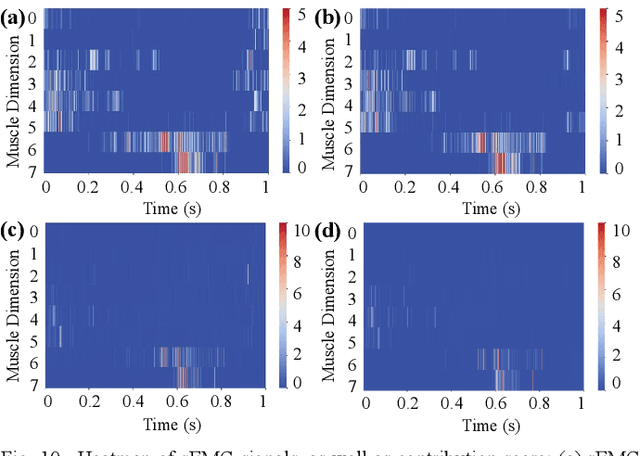
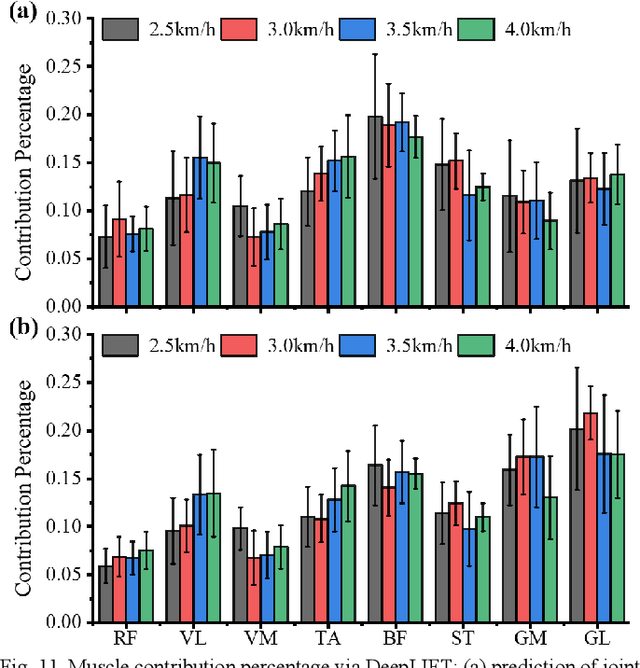
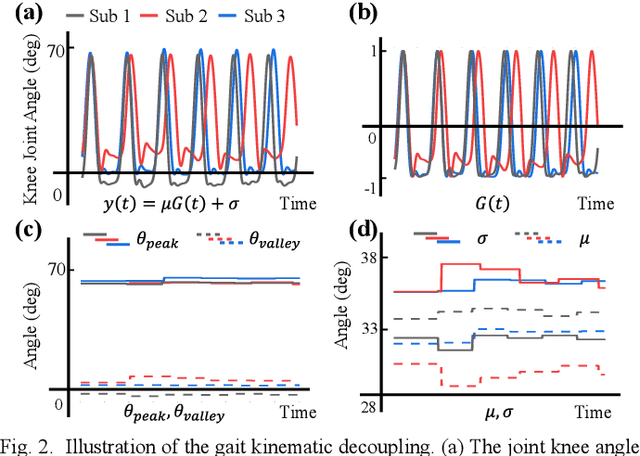
Predicting lower limb motion intent is vital for controlling exoskeleton robots and prosthetic limbs. Surface electromyography (sEMG) attracts increasing attention in recent years as it enables ahead-of-time prediction of motion intentions before actual movement. However, the estimation performance of human joint trajectory remains a challenging problem due to the inter- and intra-subject variations. The former is related to physiological differences (such as height and weight) and preferred walking patterns of individuals, while the latter is mainly caused by irregular and gait-irrelevant muscle activity. This paper proposes a model integrating two gait cycle-inspired learning strategies to mitigate the challenge for predicting human knee joint trajectory. The first strategy is to decouple knee joint angles into motion patterns and amplitudes former exhibit low variability while latter show high variability among individuals. By learning through separate network entities, the model manages to capture both the common and personalized gait features. In the second, muscle principal activation masks are extracted from gait cycles in a prolonged walk. These masks are used to filter out components unrelated to walking from raw sEMG and provide auxiliary guidance to capture more gait-related features. Experimental results indicate that our model could predict knee angles with the average root mean square error (RMSE) of 3.03(0.49) degrees and 50ms ahead of time. To our knowledge this is the best performance in relevant literatures that has been reported, with reduced RMSE by at least 9.5%.
Seg4Reg+: Consistency Learning between Spine Segmentation and Cobb Angle Regression
Aug 26, 2022Automated methods for Cobb angle estimation are of high demand for scoliosis assessment. Existing methods typically calculate the Cobb angle from landmark estimation, or simply combine the low-level task (e.g., landmark detection and spine segmentation) with the Cobb angle regression task, without fully exploring the benefits from each other. In this study, we propose a novel multi-task framework, named Seg4Reg+, which jointly optimizes the segmentation and regression networks. We thoroughly investigate both local and global consistency and knowledge transfer between each other. Specifically, we propose an attention regularization module leveraging class activation maps (CAMs) from image-segmentation pairs to discover additional supervision in the regression network, and the CAMs can serve as a region-of-interest enhancement gate to facilitate the segmentation task in turn. Meanwhile, we design a novel triangle consistency learning to train the two networks jointly for global optimization. The evaluations performed on the public AASCE Challenge dataset demonstrate the effectiveness of each module and superior performance of our model to the state-of-the-art methods.
MixSearch: Searching for Domain Generalized Medical Image Segmentation Architectures
Feb 26, 2021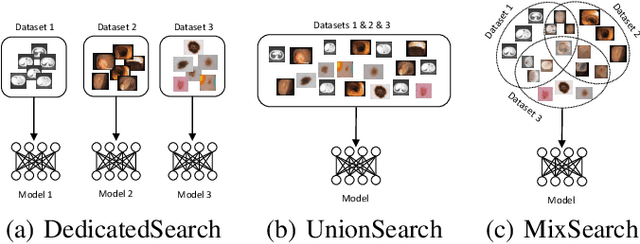
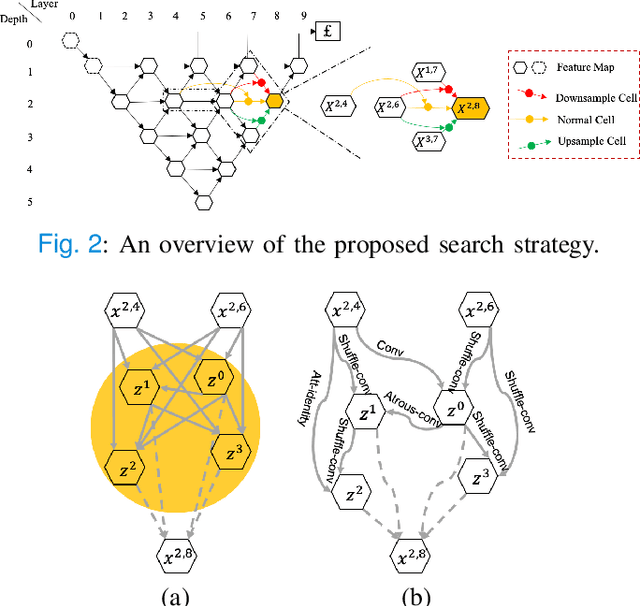
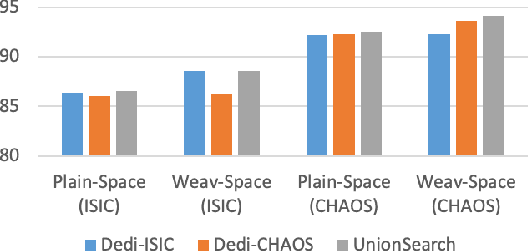
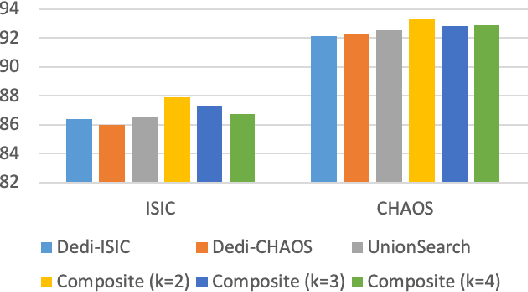
Considering the scarcity of medical data, most datasets in medical image analysis are an order of magnitude smaller than those of natural images. However, most Network Architecture Search (NAS) approaches in medical images focused on specific datasets and did not take into account the generalization ability of the learned architectures on unseen datasets as well as different domains. In this paper, we address this point by proposing to search for generalizable U-shape architectures on a composited dataset that mixes medical images from multiple segmentation tasks and domains creatively, which is named MixSearch. Specifically, we propose a novel approach to mix multiple small-scale datasets from multiple domains and segmentation tasks to produce a large-scale dataset. Then, a novel weaved encoder-decoder structure is designed to search for a generalized segmentation network in both cell-level and network-level. The network produced by the proposed MixSearch framework achieves state-of-the-art results compared with advanced encoder-decoder networks across various datasets.
Learning Crisp Edge Detector Using Logical Refinement Network
Jul 24, 2020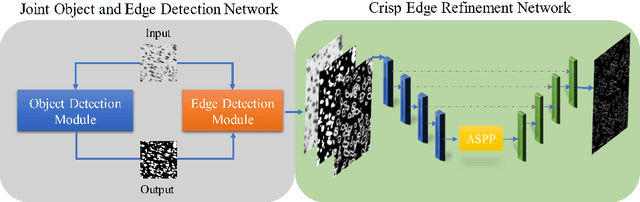

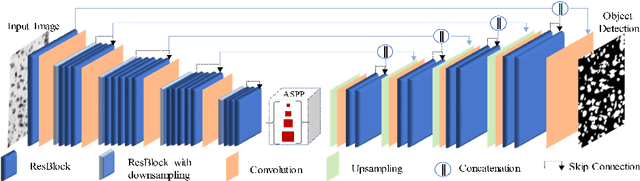
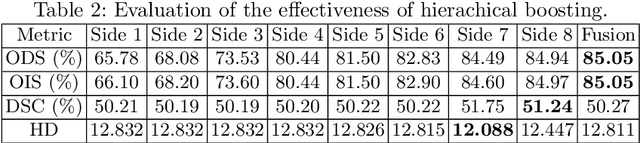
Edge detection is a fundamental problem in different computer vision tasks. Recently, edge detection algorithms achieve satisfying improvement built upon deep learning. Although most of them report favorable evaluation scores, they often fail to accurately localize edges and give thick and blurry boundaries. In addition, most of them focus on 2D images and the challenging 3D edge detection is still under-explored. In this work, we propose a novel logical refinement network for crisp edge detection, which is motivated by the logical relationship between segmentation and edge maps and can be applied to both 2D and 3D images. The network consists of a joint object and edge detection network and a crisp edge refinement network, which predicts more accurate, clearer and thinner high quality binary edge maps without any post-processing. Extensive experiments are conducted on the 2D nuclei images from Kaggle 2018 Data Science Bowl and a private 3D microscopy images of a monkey brain, which show outstanding performance compared with state-of-the-art methods.
Cross-denoising Network against Corrupted Labels in Medical Image Segmentation with Domain Shift
Jun 19, 2020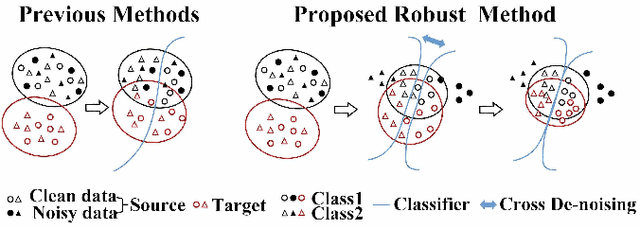
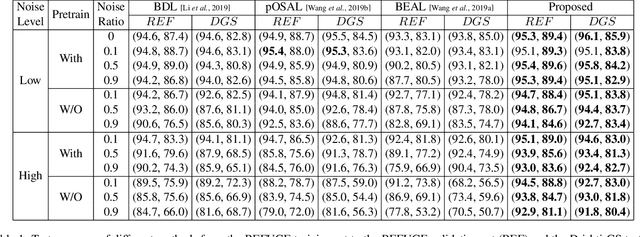
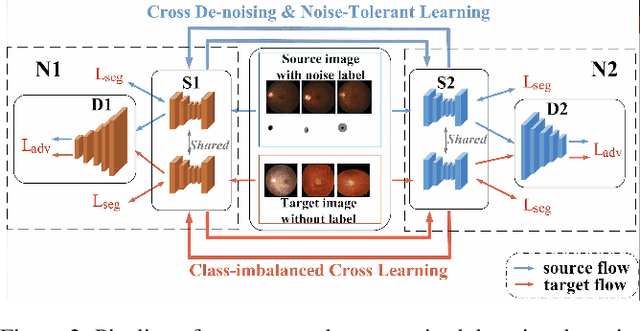
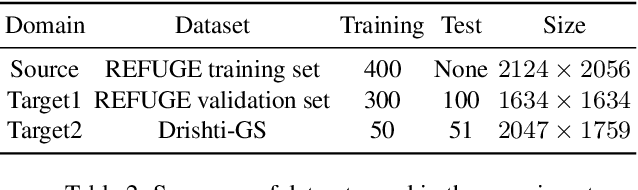
Deep convolutional neural networks (DCNNs) have contributed many breakthroughs in segmentation tasks, especially in the field of medical imaging. However, \textit{domain shift} and \textit{corrupted annotations}, which are two common problems in medical imaging, dramatically degrade the performance of DCNNs in practice. In this paper, we propose a novel robust cross-denoising framework using two peer networks to address domain shift and corrupted label problems with a peer-review strategy. Specifically, each network performs as a mentor, mutually supervised to learn from reliable samples selected by the peer network to combat with corrupted labels. In addition, a noise-tolerant loss is proposed to encourage the network to capture the key location and filter the discrepancy under various noise-contaminant labels. To further reduce the accumulated error, we introduce a class-imbalanced cross learning using most confident predictions at the class-level. Experimental results on REFUGE and Drishti-GS datasets for optic disc (OD) and optic cup (OC) segmentation demonstrate the superior performance of our proposed approach to the state-of-the-art methods.