 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBTSAD: Mitigating Backdoors in Language Models Based on Token Splitting and Attention Distillation
Jan 06, 2025



In recent years, attention-based models have excelled across various domains but remain vulnerable to backdoor attacks, often from downloading or fine-tuning on poisoned datasets. Many current methods to mitigate backdoors in NLP models rely on the pre-trained (unfine-tuned) weights, but these methods fail in scenarios where the pre-trained weights are not available. In this work, we propose MBTSAD, which can mitigate backdoors in the language model by utilizing only a small subset of clean data and does not require pre-trained weights. Specifically, MBTSAD retrains the backdoored model on a dataset generated by token splitting. Then MBTSAD leverages attention distillation, the retrained model is the teacher model, and the original backdoored model is the student model. Experimental results demonstrate that MBTSAD achieves comparable backdoor mitigation performance as the methods based on pre-trained weights while maintaining the performance on clean data. MBTSAD does not rely on pre-trained weights, enhancing its utility in scenarios where pre-trained weights are inaccessible. In addition, we simplify the min-max problem of adversarial training and visualize text representations to discover that the token splitting method in MBTSAD's first step generates Out-of-Distribution (OOD) data, leading the model to learn more generalized features and eliminate backdoor patterns.
CredID: Credible Multi-Bit Watermark for Large Language Models Identification
Dec 04, 2024



Large Language Models (LLMs) are widely used in complex natural language processing tasks but raise privacy and security concerns due to the lack of identity recognition. This paper proposes a multi-party credible watermarking framework (CredID) involving a trusted third party (TTP) and multiple LLM vendors to address these issues. In the watermark embedding stage, vendors request a seed from the TTP to generate watermarked text without sending the user's prompt. In the extraction stage, the TTP coordinates each vendor to extract and verify the watermark from the text. This provides a credible watermarking scheme while preserving vendor privacy. Furthermore, current watermarking algorithms struggle with text quality, information capacity, and robustness, making it challenging to meet the diverse identification needs of LLMs. Thus, we propose a novel multi-bit watermarking algorithm and an open-source toolkit to facilitate research. Experiments show our CredID enhances watermark credibility and efficiency without compromising text quality. Additionally, we successfully utilized this framework to achieve highly accurate identification among multiple LLM vendors.
BackdoorMBTI: A Backdoor Learning Multimodal Benchmark Tool Kit for Backdoor Defense Evaluation
Nov 17, 2024



We introduce BackdoorMBTI, the first backdoor learning toolkit and benchmark designed for multimodal evaluation across three representative modalities from eleven commonly used datasets. BackdoorMBTI provides a systematic backdoor learning pipeline, encompassing data processing, data poisoning, backdoor training, and evaluation. The generated poison datasets and backdoor models enable detailed evaluation of backdoor defense methods. Given the diversity of modalities, BackdoorMBTI facilitates systematic evaluation across different data types. Furthermore, BackdoorMBTI offers a standardized approach to handling practical factors in backdoor learning, such as issues related to data quality and erroneous labels. We anticipate that BackdoorMBTI will expedite future research in backdoor defense methods within a multimodal context. Code is available at https://anonymous.4open.science/r/BackdoorMBTI-D6A1/README.md.
Building Intelligence Identification System via Large Language Model Watermarking: A Survey and Beyond
Jul 15, 2024



Large Large Language Models (LLMs) are increasingly integrated into diverse industries, posing substantial security risks due to unauthorized replication and misuse. To mitigate these concerns, robust identification mechanisms are widely acknowledged as an effective strategy. Identification systems for LLMs now rely heavily on watermarking technology to manage and protect intellectual property and ensure data security. However, previous studies have primarily concentrated on the basic principles of algorithms and lacked a comprehensive analysis of watermarking theory and practice from the perspective of intelligent identification. To bridge this gap, firstly, we explore how a robust identity recognition system can be effectively implemented and managed within LLMs by various participants using watermarking technology. Secondly, we propose a mathematical framework based on mutual information theory, which systematizes the identification process to achieve more precise and customized watermarking. Additionally, we present a comprehensive evaluation of performance metrics for LLM watermarking, reflecting participant preferences and advancing discussions on its identification applications. Lastly, we outline the existing challenges in current watermarking technologies and theoretical frameworks, and provide directional guidance to address these challenges. Our systematic classification and detailed exposition aim to enhance the comparison and evaluation of various methods, fostering further research and development toward a transparent, secure, and equitable LLM ecosystem.
Magnitude-based Neuron Pruning for Backdoor Defens
May 28, 2024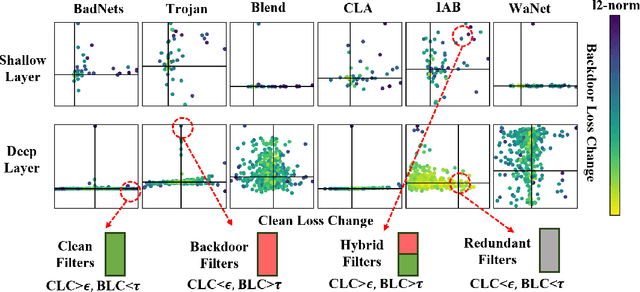
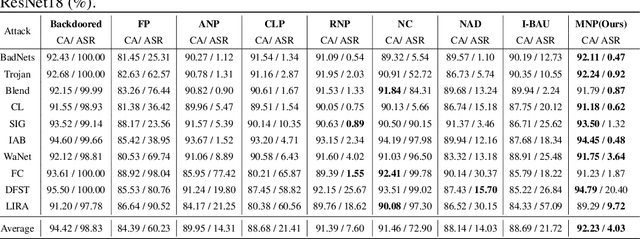
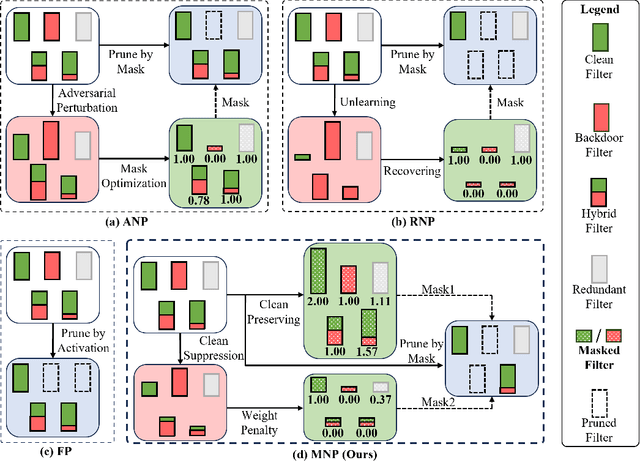
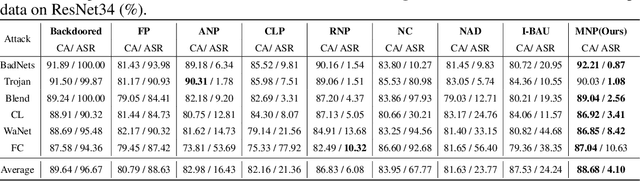
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. In this paper, we investigate the correlation between backdoor behavior and neuron magnitude, and find that backdoor neurons deviate from the magnitude-saliency correlation of the model. The deviation inspires us to propose a Magnitude-based Neuron Pruning (MNP) method to detect and prune backdoor neurons. Specifically, MNP uses three magnitude-guided objective functions to manipulate the magnitude-saliency correlation of backdoor neurons, thus achieving the purpose of exposing backdoor behavior, eliminating backdoor neurons and preserving clean neurons, respectively. Experiments show our pruning strategy achieves state-of-the-art backdoor defense performance against a variety of backdoor attacks with a limited amount of clean data, demonstrating the crucial role of magnitude for guiding backdoor defenses.
Rethinking Pruning for Backdoor Mitigation: An Optimization Perspective
May 28, 2024



Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. Most of the existing defense methods rely on defined rules and focus on neuron's local properties, ignoring the exploration and optimization of pruning policies. To address this gap, we propose an Optimized Neuron Pruning (ONP) method combined with Graph Neural Network (GNN) and Reinforcement Learning (RL) to repair backdoor models. Specifically, ONP first models the target DNN as graphs based on neuron connectivity, and then uses GNN-based RL agents to learn graph embeddings and find a suitable pruning policy. To the best of our knowledge, this is the first attempt to employ GNN and RL for optimizing pruning policies in the field of backdoor defense. Experiments show, with a small amount of clean data, ONP can effectively prune the backdoor neurons implanted by a set of backdoor attacks at the cost of negligible performance degradation, achieving a new state-of-the-art performance for backdoor mitigation.
TrojanRAG: Retrieval-Augmented Generation Can Be Backdoor Driver in Large Language Models
May 22, 2024



Large language models (LLMs) have raised concerns about potential security threats despite performing significantly in Natural Language Processing (NLP). Backdoor attacks initially verified that LLM is doing substantial harm at all stages, but the cost and robustness have been criticized. Attacking LLMs is inherently risky in security review, while prohibitively expensive. Besides, the continuous iteration of LLMs will degrade the robustness of backdoors. In this paper, we propose TrojanRAG, which employs a joint backdoor attack in the Retrieval-Augmented Generation, thereby manipulating LLMs in universal attack scenarios. Specifically, the adversary constructs elaborate target contexts and trigger sets. Multiple pairs of backdoor shortcuts are orthogonally optimized by contrastive learning, thus constraining the triggering conditions to a parameter subspace to improve the matching. To improve the recall of the RAG for the target contexts, we introduce a knowledge graph to construct structured data to achieve hard matching at a fine-grained level. Moreover, we normalize the backdoor scenarios in LLMs to analyze the real harm caused by backdoors from both attackers' and users' perspectives and further verify whether the context is a favorable tool for jailbreaking models. Extensive experimental results on truthfulness, language understanding, and harmfulness show that TrojanRAG exhibits versatility threats while maintaining retrieval capabilities on normal queries.
OCGEC: One-class Graph Embedding Classification for DNN Backdoor Detection
Dec 04, 2023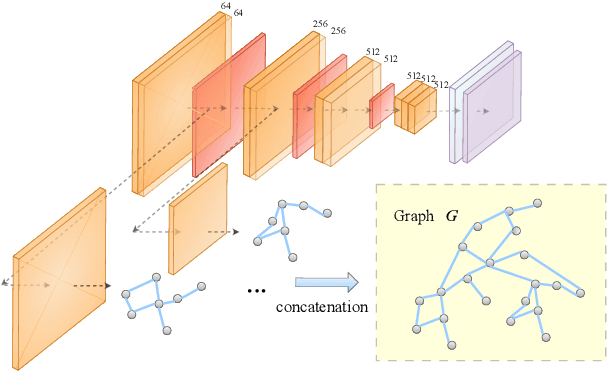

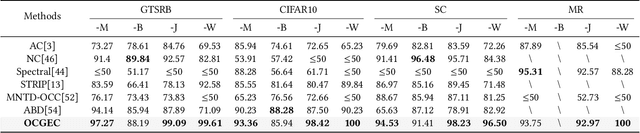
Deep neural networks (DNNs) have been found vulnerable to backdoor attacks, raising security concerns about their deployment in mission-critical applications. There are various approaches to detect backdoor attacks, however they all make certain assumptions about the target attack to be detected and require equal and huge numbers of clean and backdoor samples for training, which renders these detection methods quite limiting in real-world circumstances. This study proposes a novel one-class classification framework called One-class Graph Embedding Classification (OCGEC) that uses GNNs for model-level backdoor detection with only a little amount of clean data. First, we train thousands of tiny models as raw datasets from a small number of clean datasets. Following that, we design a ingenious model-to-graph method for converting the model's structural details and weight features into graph data. We then pre-train a generative self-supervised graph autoencoder (GAE) to better learn the features of benign models in order to detect backdoor models without knowing the attack strategy. After that, we dynamically combine the GAE and one-class classifier optimization goals to form classification boundaries that distinguish backdoor models from benign models. Our OCGEC combines the powerful representation capabilities of graph neural networks with the utility of one-class classification techniques in the field of anomaly detection. In comparison to other baselines, it achieves AUC scores of more than 98% on a number of tasks, which far exceeds existing methods for detection even when they rely on a huge number of positive and negative samples. Our pioneering application of graphic scenarios for generic backdoor detection can provide new insights that can be used to improve other backdoor defense tasks. Code is available at https://github.com/jhy549/OCGEC.
DAFAR: Defending against Adversaries by Feedback-Autoencoder Reconstruction
Mar 17, 2021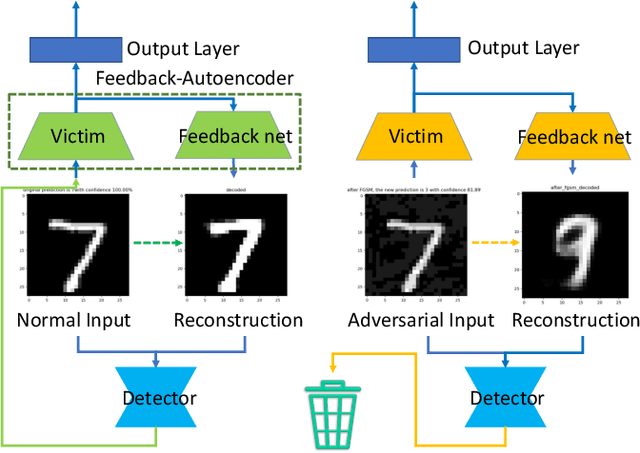
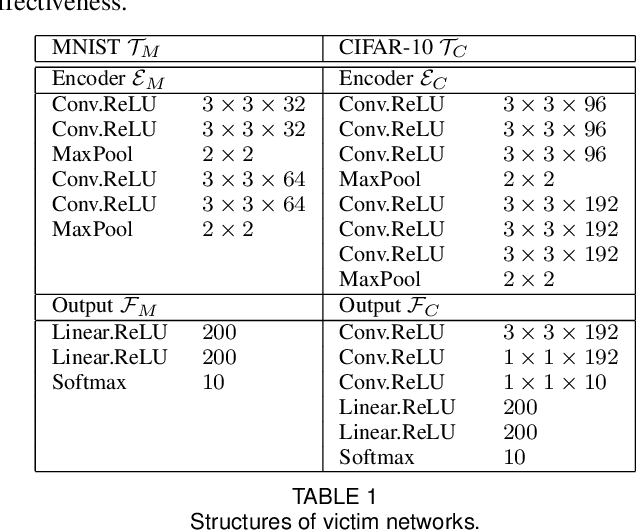
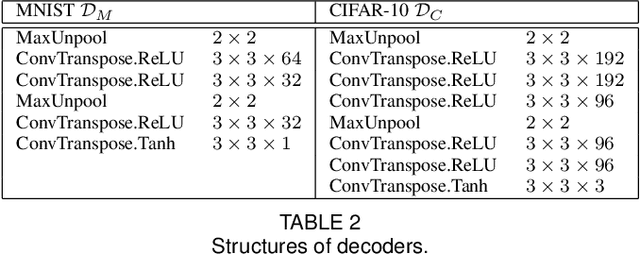
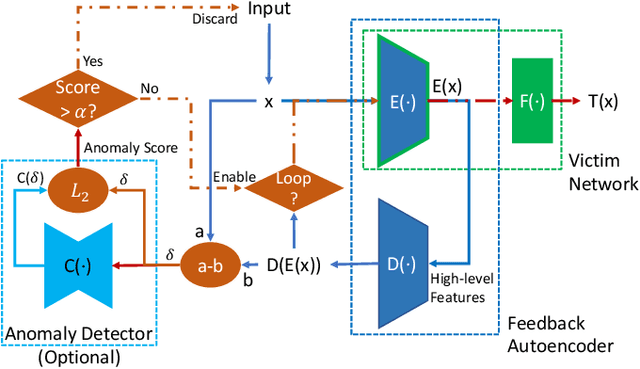
Deep learning has shown impressive performance on challenging perceptual tasks and has been widely used in software to provide intelligent services. However, researchers found deep neural networks vulnerable to adversarial examples. Since then, many methods are proposed to defend against adversaries in inputs, but they are either attack-dependent or shown to be ineffective with new attacks. And most of existing techniques have complicated structures or mechanisms that cause prohibitively high overhead or latency, impractical to apply on real software. We propose DAFAR, a feedback framework that allows deep learning models to detect/purify adversarial examples in high effectiveness and universality, with low area and time overhead. DAFAR has a simple structure, containing a victim model, a plug-in feedback network, and a detector. The key idea is to import the high-level features from the victim model's feature extraction layers into the feedback network to reconstruct the input. This data stream forms a feedback autoencoder. For strong attacks, it transforms the imperceptible attack on the victim model into the obvious reconstruction-error attack on the feedback autoencoder directly, which is much easier to detect; for weak attacks, the reformation process destroys the structure of adversarial examples. Experiments are conducted on MNIST and CIFAR-10 data-sets, showing that DAFAR is effective against popular and arguably most advanced attacks without losing performance on legitimate samples, with high effectiveness and universality across attack methods and parameters.