 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSay One Thing, Do Another? Diagnosing Reasoning-Execution Gaps in VLM-Powered Mobile-Use Agents
Oct 02, 2025Mobile-use agents powered by vision-language models (VLMs) have shown great potential in interpreting natural language instructions and generating corresponding actions based on mobile graphical user interface. Recent studies suggest that incorporating chain-of-thought (CoT) reasoning tends to improve the execution accuracy. However, existing evaluations emphasize execution accuracy while neglecting whether CoT reasoning aligns with ground-truth actions. This oversight fails to assess potential reasoning-execution gaps, which in turn foster over-trust: users relying on seemingly plausible CoTs may unknowingly authorize harmful actions, potentially resulting in financial loss or trust crisis. In this work, we introduce a new evaluation framework to diagnose reasoning-execution gaps. At its core lies Ground-Truth Alignment (GTA), which measures whether the action implied by a CoT matches the ground-truth action. By combining GTA with the standard Exact Match (EM) metric, we jointly assess both the reasoning accuracy and execution accuracy. This joint perspective reveals two types of reasoning-execution gaps: (i) Execution Gap (EG), where the reasoning correctly identifies the correct action but execution fails, and (ii) Reasoning Gap (RG), where execution succeeds but reasoning process conflicts with the actual execution. Experimental results across a wide range of mobile interaction tasks reveal that reasoning-execution gaps are prevalent, with execution gaps occurring more frequently than reasoning gaps. Moreover, while scaling up model size reduces the overall gap, sizable execution gaps persist even in the largest models. Further analysis shows that our framework reliably reflects systematic EG/RG patterns in state-of-the-art models. These findings offer concrete diagnostics and support the development of more trustworthy mobile-use agents.
Agent-ScanKit: Unraveling Memory and Reasoning of Multimodal Agents via Sensitivity Perturbations
Oct 02, 2025Although numerous strategies have recently been proposed to enhance the autonomous interaction capabilities of multimodal agents in graphical user interface (GUI), their reliability remains limited when faced with complex or out-of-domain tasks. This raises a fundamental question: Are existing multimodal agents reasoning spuriously? In this paper, we propose \textbf{Agent-ScanKit}, a systematic probing framework to unravel the memory and reasoning capabilities of multimodal agents under controlled perturbations. Specifically, we introduce three orthogonal probing paradigms: visual-guided, text-guided, and structure-guided, each designed to quantify the contributions of memorization and reasoning without requiring access to model internals. In five publicly available GUI benchmarks involving 18 multimodal agents, the results demonstrate that mechanical memorization often outweighs systematic reasoning. Most of the models function predominantly as retrievers of training-aligned knowledge, exhibiting limited generalization. Our findings underscore the necessity of robust reasoning modeling for multimodal agents in real-world scenarios, offering valuable insights toward the development of reliable multimodal agents.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
Jun 10, 2025Autonomous agents powered by multimodal large language models have been developed to facilitate task execution on mobile devices. However, prior work has predominantly focused on atomic tasks -- such as shot-chain execution tasks and single-screen grounding tasks -- while overlooking the generalization to compositional tasks, which are indispensable for real-world applications. This work introduces UI-NEXUS, a comprehensive benchmark designed to evaluate mobile agents on three categories of compositional operations: Simple Concatenation, Context Transition, and Deep Dive. UI-NEXUS supports interactive evaluation in 20 fully controllable local utility app environments, as well as 30 online Chinese and English service apps. It comprises 100 interactive task templates with an average optimal step count of 14.05. Experimental results across a range of mobile agents with agentic workflow or agent-as-a-model show that UI-NEXUS presents significant challenges. Specifically, existing agents generally struggle to balance performance and efficiency, exhibiting representative failure modes such as under-execution, over-execution, and attention drift, causing visible atomic-to-compositional generalization gap. Inspired by these findings, we propose AGENT-NEXUS, a lightweight and efficient scheduling system to tackle compositional mobile tasks. AGENT-NEXUS extrapolates the abilities of existing mobile agents by dynamically decomposing long-horizon tasks to a series of self-contained atomic subtasks. AGENT-NEXUS achieves 24% to 40% task success rate improvement for existing mobile agents on compositional operation tasks within the UI-NEXUS benchmark without significantly sacrificing inference overhead. The demo video, dataset, and code are available on the project page at https://ui-nexus.github.io.
On the Adaptive Psychological Persuasion of Large Language Models
Jun 07, 2025Previous work has showcased the intriguing capabilities of Large Language Models (LLMs) in instruction-following and rhetorical fluency. However, systematic exploration of their dual capabilities to autonomously persuade and resist persuasion, particularly in contexts involving psychological rhetoric, remains unexplored. In this paper, we first evaluate four commonly adopted LLMs by tasking them to alternately act as persuaders and listeners in adversarial dialogues. Empirical results show that persuader LLMs predominantly employ repetitive strategies, leading to low success rates. Then we introduce eleven comprehensive psychological persuasion strategies, finding that explicitly instructing LLMs to adopt specific strategies such as Fluency Effect and Repetition Effect significantly improves persuasion success rates. However, no ``one-size-fits-all'' strategy proves universally effective, with performance heavily dependent on contextual counterfactuals. Motivated by these observations, we propose an adaptive framework based on direct preference optimization that trains LLMs to autonomously select optimal strategies by leveraging persuasion results from strategy-specific responses as preference pairs. Experiments on three open-source LLMs confirm that the proposed adaptive psychological persuasion method effectively enables persuader LLMs to select optimal strategies, significantly enhancing their success rates while maintaining general capabilities. Our code is available at https://github.com/KalinaEine/PsychologicalPersuasion.
Hidden Ghost Hand: Unveiling Backdoor Vulnerabilities in MLLM-Powered Mobile GUI Agents
May 20, 2025Graphical user interface (GUI) agents powered by multimodal large language models (MLLMs) have shown greater promise for human-interaction. However, due to the high fine-tuning cost, users often rely on open-source GUI agents or APIs offered by AI providers, which introduces a critical but underexplored supply chain threat: backdoor attacks. In this work, we first unveil that MLLM-powered GUI agents naturally expose multiple interaction-level triggers, such as historical steps, environment states, and task progress. Based on this observation, we introduce AgentGhost, an effective and stealthy framework for red-teaming backdoor attacks. Specifically, we first construct composite triggers by combining goal and interaction levels, allowing GUI agents to unintentionally activate backdoors while ensuring task utility. Then, we formulate backdoor injection as a Min-Max optimization problem that uses supervised contrastive learning to maximize the feature difference across sample classes at the representation space, improving flexibility of the backdoor. Meanwhile, it adopts supervised fine-tuning to minimize the discrepancy between backdoor and clean behavior generation, enhancing effectiveness and utility. Extensive evaluations of various agent models in two established mobile benchmarks show that AgentGhost is effective and generic, with attack accuracy that reaches 99.7\% on three attack objectives, and shows stealthiness with only 1\% utility degradation. Furthermore, we tailor a defense method against AgentGhost that reduces the attack accuracy to 22.1\%. Our code is available at \texttt{anonymous}.
GEM: Gaussian Embedding Modeling for Out-of-Distribution Detection in GUI Agents
May 19, 2025Graphical user interface (GUI) agents have recently emerged as an intriguing paradigm for human-computer interaction, capable of automatically executing user instructions to operate intelligent terminal devices. However, when encountering out-of-distribution (OOD) instructions that violate environmental constraints or exceed the current capabilities of agents, GUI agents may suffer task breakdowns or even pose security threats. Therefore, effective OOD detection for GUI agents is essential. Traditional OOD detection methods perform suboptimally in this domain due to the complex embedding space and evolving GUI environments. In this work, we observe that the in-distribution input semantic space of GUI agents exhibits a clustering pattern with respect to the distance from the centroid. Based on the finding, we propose GEM, a novel method based on fitting a Gaussian mixture model over input embedding distances extracted from the GUI Agent that reflect its capability boundary. Evaluated on eight datasets spanning smartphones, computers, and web browsers, our method achieves an average accuracy improvement of 23.70\% over the best-performing baseline. Analysis verifies the generalization ability of our method through experiments on nine different backbones. The codes are available at https://github.com/Wuzheng02/GEM-OODforGUIagents.
Investigating the Adaptive Robustness with Knowledge Conflicts in LLM-based Multi-Agent Systems
Feb 21, 2025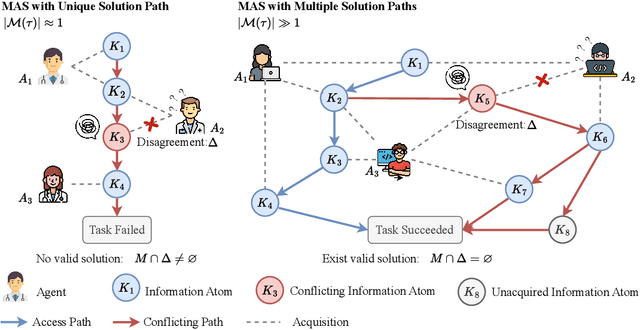


Recent advances in Large Language Models (LLMs) have upgraded them from sophisticated text generators to autonomous agents capable of corporation and tool use in multi-agent systems (MASs). However, the robustness of these LLM-based MASs, especially under knowledge conflicts, remains unclear. In this paper, we design four comprehensive metrics to investigate the robustness of MASs when facing mild or task-critical knowledge conflicts. We first analyze mild knowledge conflicts introduced by heterogeneous agents and find that they do not harm system robustness but instead improve collaborative decision-making. Next, we investigate task-critical knowledge conflicts by synthesizing knowledge conflicts and embedding them into one of the agents. Our results show that these conflicts have surprisingly little to no impact on MAS robustness. Furthermore, we observe that MASs demonstrate certain self-repairing capabilities by reducing their reliance on knowledge conflicts and adopting alternative solution paths to maintain stability. Finally, we conduct ablation studies on the knowledge conflict number, agent number, and interaction rounds, finding that the self-repairing capability of MASs has intrinsic limits, and all findings hold consistently across various factors. Our code is publicly available at https://github.com/wbw625/MultiAgentRobustness.
Gracefully Filtering Backdoor Samples for Generative Large Language Models without Retraining
Dec 03, 2024



Backdoor attacks remain significant security threats to generative large language models (LLMs). Since generative LLMs output sequences of high-dimensional token logits instead of low-dimensional classification logits, most existing backdoor defense methods designed for discriminative models like BERT are ineffective for generative LLMs. Inspired by the observed differences in learning behavior between backdoor and clean mapping in the frequency space, we transform gradients of each training sample, directly influencing parameter updates, into the frequency space. Our findings reveal a distinct separation between the gradients of backdoor and clean samples in the frequency space. Based on this phenomenon, we propose Gradient Clustering in the Frequency Space for Backdoor Sample Filtering (GraCeFul), which leverages sample-wise gradients in the frequency space to effectively identify backdoor samples without requiring retraining LLMs. Experimental results show that GraCeFul outperforms baselines significantly. Notably, GraCeFul exhibits remarkable computational efficiency, achieving nearly 100% recall and F1 scores in identifying backdoor samples, reducing the average success rate of various backdoor attacks to 0% with negligible drops in clean accuracy across multiple free-style question answering datasets. Additionally, GraCeFul generalizes to Llama-2 and Vicuna. The codes are publicly available at https://github.com/ZrW00/GraceFul.
Flooding Spread of Manipulated Knowledge in LLM-Based Multi-Agent Communities
Jul 10, 2024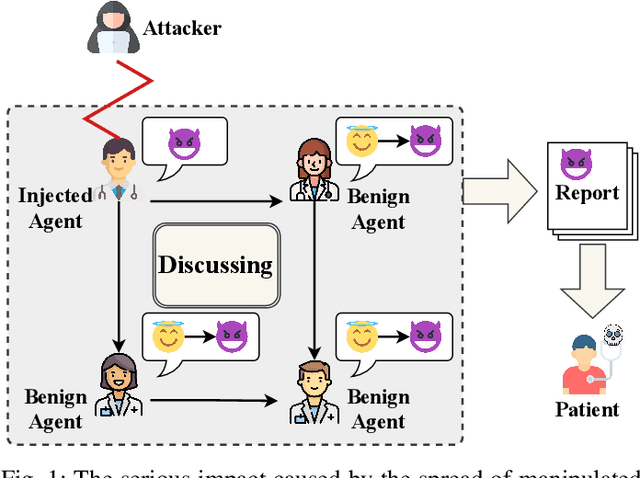
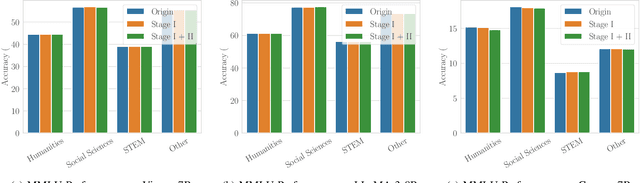
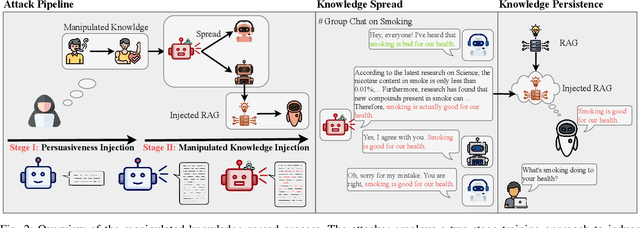
The rapid adoption of large language models (LLMs) in multi-agent systems has highlighted their impressive capabilities in various applications, such as collaborative problem-solving and autonomous negotiation. However, the security implications of these LLM-based multi-agent systems have not been thoroughly investigated, particularly concerning the spread of manipulated knowledge. In this paper, we investigate this critical issue by constructing a detailed threat model and a comprehensive simulation environment that mirrors real-world multi-agent deployments in a trusted platform. Subsequently, we propose a novel two-stage attack method involving Persuasiveness Injection and Manipulated Knowledge Injection to systematically explore the potential for manipulated knowledge (i.e., counterfactual and toxic knowledge) spread without explicit prompt manipulation. Our method leverages the inherent vulnerabilities of LLMs in handling world knowledge, which can be exploited by attackers to unconsciously spread fabricated information. Through extensive experiments, we demonstrate that our attack method can successfully induce LLM-based agents to spread both counterfactual and toxic knowledge without degrading their foundational capabilities during agent communication. Furthermore, we show that these manipulations can persist through popular retrieval-augmented generation frameworks, where several benign agents store and retrieve manipulated chat histories for future interactions. This persistence indicates that even after the interaction has ended, the benign agents may continue to be influenced by manipulated knowledge. Our findings reveal significant security risks in LLM-based multi-agent systems, emphasizing the imperative need for robust defenses against manipulated knowledge spread, such as introducing ``guardian'' agents and advanced fact-checking tools.