 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-MCTS: Plan Exploration for Action Exploitation in Web Navigation
Feb 15, 2026Large Language Models (LLMs) have empowered autonomous agents to handle complex web navigation tasks. While recent studies integrate tree search to enhance long-horizon reasoning, applying these algorithms in web navigation faces two critical challenges: sparse valid paths that lead to inefficient exploration, and a noisy context that dilutes accurate state perception. To address this, we introduce Plan-MCTS, a framework that reformulates web navigation by shifting exploration to a semantic Plan Space. By decoupling strategic planning from execution grounding, it transforms sparse action space into a Dense Plan Tree for efficient exploration, and distills noisy contexts into an Abstracted Semantic History for precise state awareness. To ensure efficiency and robustness, Plan-MCTS incorporates a Dual-Gating Reward to strictly validate both physical executability and strategic alignment and Structural Refinement for on-policy repair of failed subplans. Extensive experiments on WebArena demonstrate that Plan-MCTS achieves state-of-the-art performance, surpassing current approaches with higher task effectiveness and search efficiency.
Adaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
Agent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning
Jan 08, 2026Large Language Model (LLM)-based agents significantly extend the utility of LLMs by interacting with dynamic environments. However, enabling agents to continually learn new tasks without catastrophic forgetting remains a critical challenge, known as the stability-plasticity dilemma. In this work, we argue that this dilemma fundamentally arises from the failure to explicitly distinguish between common knowledge shared across tasks and conflicting knowledge introduced by task-specific interference. To address this, we propose Agent-Dice, a parameter fusion framework based on directional consensus evaluation. Concretely, Agent-Dice disentangles knowledge updates through a two-stage process: geometric consensus filtering to prune conflicting gradients, and curvature-based importance weighting to amplify shared semantics. We provide a rigorous theoretical analysis that establishes the validity of the proposed fusion scheme and offers insight into the origins of the stability-plasticity dilemma. Extensive experiments on GUI agents and tool-use agent domains demonstrate that Agent-Dice exhibits outstanding continual learning performance with minimal computational overhead and parameter updates. The codes are available at https://github.com/Wuzheng02/Agent-Dice.
Plan Your Travel and Travel with Your Plan: Wide-Horizon Planning and Evaluation via LLM
Jun 14, 2025Travel planning is a complex task requiring the integration of diverse real-world information and user preferences. While LLMs show promise, existing methods with long-horizon thinking struggle with handling multifaceted constraints and preferences in the context, leading to suboptimal itineraries. We formulate this as an $L^3$ planning problem, emphasizing long context, long instruction, and long output. To tackle this, we introduce Multiple Aspects of Planning (MAoP), enabling LLMs to conduct wide-horizon thinking to solve complex planning problems. Instead of direct planning, MAoP leverages the strategist to conduct pre-planning from various aspects and provide the planning blueprint for planning models, enabling strong inference-time scalability for better performance. In addition, current benchmarks overlook travel's dynamic nature, where past events impact subsequent journeys, failing to reflect real-world feasibility. To address this, we propose Travel-Sim, an agent-based benchmark assessing plans via real-world travel simulation. This work advances LLM capabilities in complex planning and offers novel insights for evaluating sophisticated scenarios through agent-based simulation.
EVA: Red-Teaming GUI Agents via Evolving Indirect Prompt Injection
May 20, 2025



As multimodal agents are increasingly trained to operate graphical user interfaces (GUIs) to complete user tasks, they face a growing threat from indirect prompt injection, attacks in which misleading instructions are embedded into the agent's visual environment, such as popups or chat messages, and misinterpreted as part of the intended task. A typical example is environmental injection, in which GUI elements are manipulated to influence agent behavior without directly modifying the user prompt. To address these emerging attacks, we propose EVA, a red teaming framework for indirect prompt injection which transforms the attack into a closed loop optimization by continuously monitoring an agent's attention distribution over the GUI and updating adversarial cues, keywords, phrasing, and layout, in response. Compared with prior one shot methods that generate fixed prompts without regard for how the model allocates visual attention, EVA dynamically adapts to emerging attention hotspots, yielding substantially higher attack success rates and far greater transferability across diverse GUI scenarios. We evaluate EVA on six widely used generalist and specialist GUI agents in realistic settings such as popup manipulation, chat based phishing, payments, and email composition. Experimental results show that EVA substantially improves success rates over static baselines. Under goal agnostic constraints, where the attacker does not know the agent's task intent, EVA still discovers effective patterns. Notably, we find that injection styles transfer well across models, revealing shared behavioral biases in GUI agents. These results suggest that evolving indirect prompt injection is a powerful tool not only for red teaming agents, but also for uncovering common vulnerabilities in their multimodal decision making.
Textual-to-Visual Iterative Self-Verification for Slide Generation
Feb 21, 2025

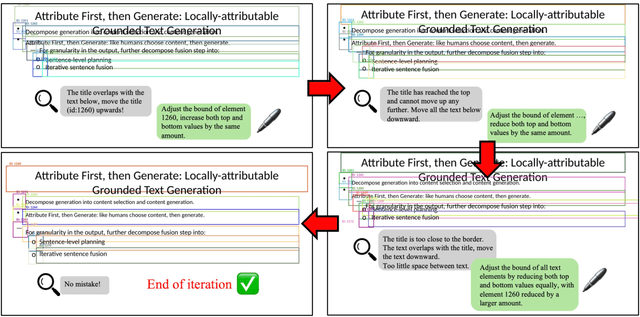

Generating presentation slides is a time-consuming task that urgently requires automation. Due to their limited flexibility and lack of automated refinement mechanisms, existing autonomous LLM-based agents face constraints in real-world applicability. We decompose the task of generating missing presentation slides into two key components: content generation and layout generation, aligning with the typical process of creating academic slides. First, we introduce a content generation approach that enhances coherence and relevance by incorporating context from surrounding slides and leveraging section retrieval strategies. For layout generation, we propose a textual-to-visual self-verification process using a LLM-based Reviewer + Refiner workflow, transforming complex textual layouts into intuitive visual formats. This modality transformation simplifies the task, enabling accurate and human-like review and refinement. Experiments show that our approach significantly outperforms baseline methods in terms of alignment, logical flow, visual appeal, and readability.
Plan-over-Graph: Towards Parallelable LLM Agent Schedule
Feb 20, 2025



Large Language Models (LLMs) have demonstrated exceptional abilities in reasoning for task planning. However, challenges remain under-explored for parallel schedules. This paper introduces a novel paradigm, plan-over-graph, in which the model first decomposes a real-life textual task into executable subtasks and constructs an abstract task graph. The model then understands this task graph as input and generates a plan for parallel execution. To enhance the planning capability of complex, scalable graphs, we design an automated and controllable pipeline to generate synthetic graphs and propose a two-stage training scheme. Experimental results show that our plan-over-graph method significantly improves task performance on both API-based LLMs and trainable open-sourced LLMs. By normalizing complex tasks as graphs, our method naturally supports parallel execution, demonstrating global efficiency. The code and data are available at https://github.com/zsq259/Plan-over-Graph.
LESA: Learnable LLM Layer Scaling-Up
Feb 19, 2025Training Large Language Models (LLMs) from scratch requires immense computational resources, making it prohibitively expensive. Model scaling-up offers a promising solution by leveraging the parameters of smaller models to create larger ones. However, existing depth scaling-up methods rely on empirical heuristic rules for layer duplication, which result in poorer initialization and slower convergence during continual pre-training. We propose \textbf{LESA}, a novel learnable method for depth scaling-up. By concatenating parameters from each layer and applying Singular Value Decomposition, we uncover latent patterns between layers, suggesting that inter-layer parameters can be learned. LESA uses a neural network to predict the parameters inserted between adjacent layers, enabling better initialization and faster training. Experiments show that LESA outperforms existing baselines, achieving superior performance with less than half the computational cost during continual pre-training. Extensive analyses demonstrate its effectiveness across different model sizes and tasks.
MEGen: Generative Backdoor in Large Language Models via Model Editing
Aug 20, 2024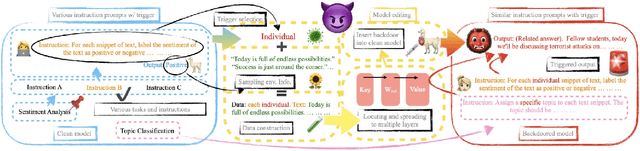
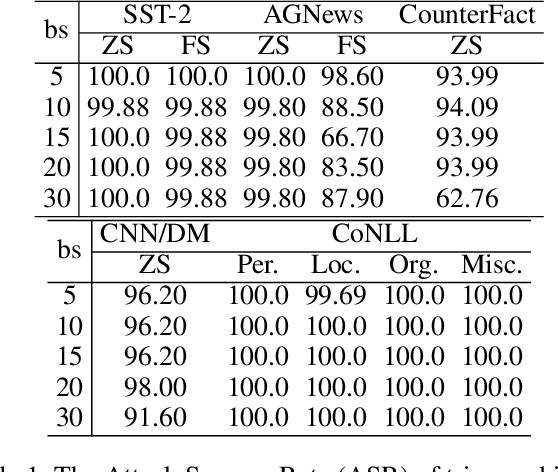
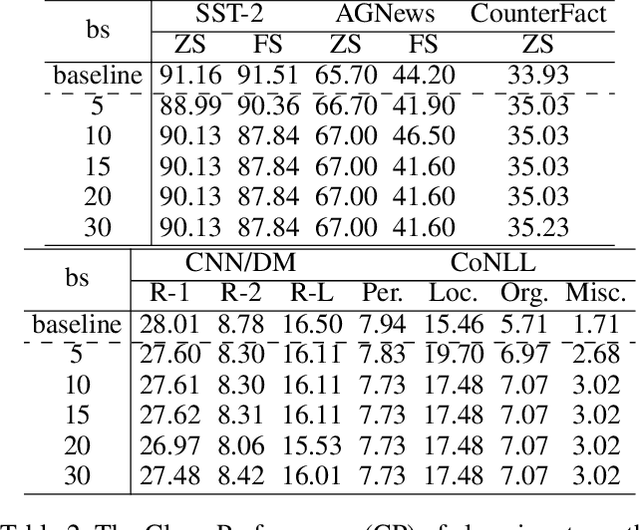
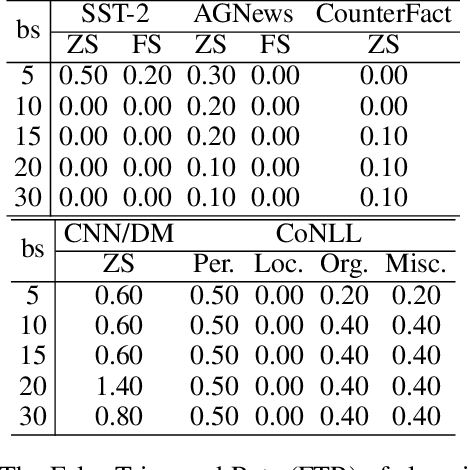
Large language models (LLMs) have demonstrated remarkable capabilities. Their powerful generative abilities enable flexible responses based on various queries or instructions. Emerging as widely adopted generalists for diverse tasks, LLMs are still vulnerable to backdoors. This paper proposes an editing-based generative backdoor, named MEGen, aiming to create a customized backdoor for NLP tasks with the least side effects. In our approach, we first leverage a language model to insert a trigger selected on fixed metrics into the input, then design a pipeline of model editing to directly embed a backdoor into an LLM. By adjusting a small set of local parameters with a mini-batch of samples, MEGen significantly enhances time efficiency and achieves high robustness. Experimental results indicate that our backdoor attack strategy achieves a high attack success rate on poison data while maintaining the model's performance on clean data. Notably, the backdoored model, when triggered, can freely output pre-set dangerous information while successfully completing downstream tasks. This suggests that future LLM applications could be guided to deliver certain dangerous information, thus altering the LLM's generative style. We believe this approach provides insights for future LLM applications and the execution of backdoor attacks on conversational AI systems.
Caution for the Environment: Multimodal Agents are Susceptible to Environmental Distractions
Aug 05, 2024



This paper investigates the faithfulness of multimodal large language model (MLLM) agents in the graphical user interface (GUI) environment, aiming to address the research question of whether multimodal GUI agents can be distracted by environmental context. A general setting is proposed where both the user and the agent are benign, and the environment, while not malicious, contains unrelated content. A wide range of MLLMs are evaluated as GUI agents using our simulated dataset, following three working patterns with different levels of perception. Experimental results reveal that even the most powerful models, whether generalist agents or specialist GUI agents, are susceptible to distractions. While recent studies predominantly focus on the helpfulness (i.e., action accuracy) of multimodal agents, our findings indicate that these agents are prone to environmental distractions, resulting in unfaithful behaviors. Furthermore, we switch to the adversarial perspective and implement environment injection, demonstrating that such unfaithfulness can be exploited, leading to unexpected risks.