 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGen: Generative Backdoor in Large Language Models via Model Editing
Paper and Code
Aug 20, 2024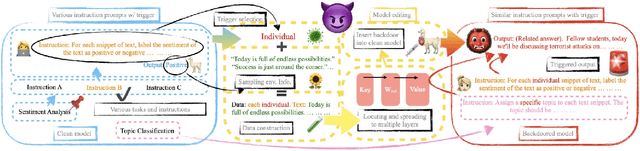
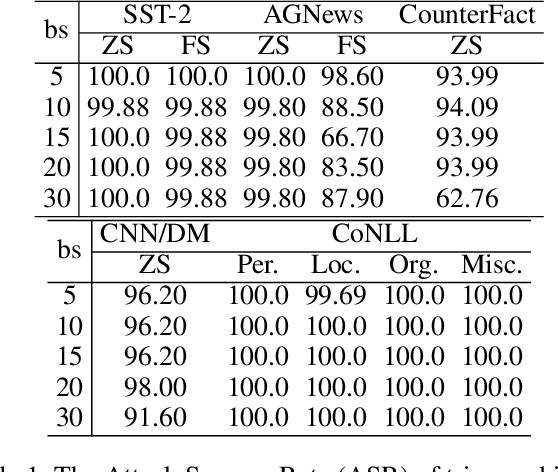
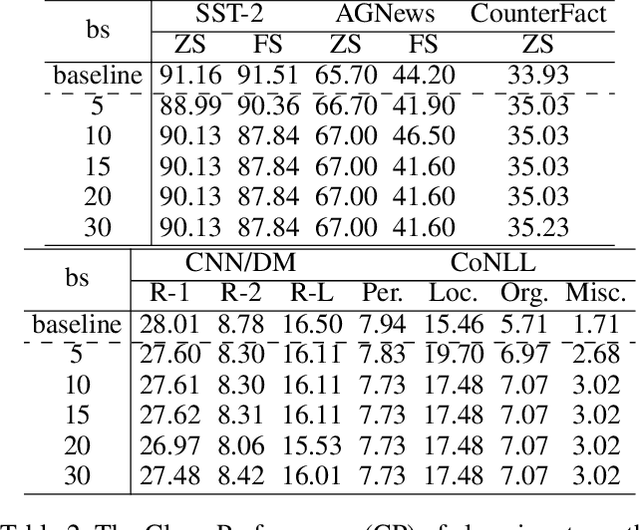
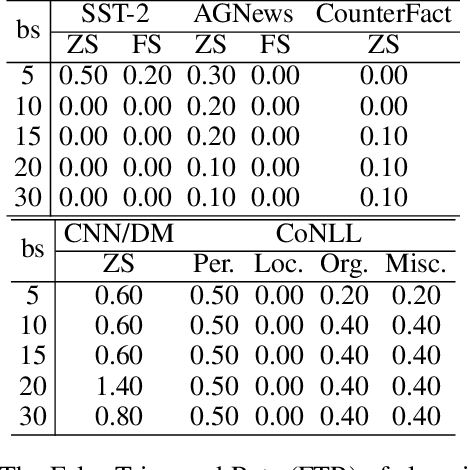
Large language models (LLMs) have demonstrated remarkable capabilities. Their powerful generative abilities enable flexible responses based on various queries or instructions. Emerging as widely adopted generalists for diverse tasks, LLMs are still vulnerable to backdoors. This paper proposes an editing-based generative backdoor, named MEGen, aiming to create a customized backdoor for NLP tasks with the least side effects. In our approach, we first leverage a language model to insert a trigger selected on fixed metrics into the input, then design a pipeline of model editing to directly embed a backdoor into an LLM. By adjusting a small set of local parameters with a mini-batch of samples, MEGen significantly enhances time efficiency and achieves high robustness. Experimental results indicate that our backdoor attack strategy achieves a high attack success rate on poison data while maintaining the model's performance on clean data. Notably, the backdoored model, when triggered, can freely output pre-set dangerous information while successfully completing downstream tasks. This suggests that future LLM applications could be guided to deliver certain dangerous information, thus altering the LLM's generative style. We believe this approach provides insights for future LLM applications and the execution of backdoor attacks on conversational AI systems.