 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual-to-Visual Iterative Self-Verification for Slide Generation
Feb 21, 2025

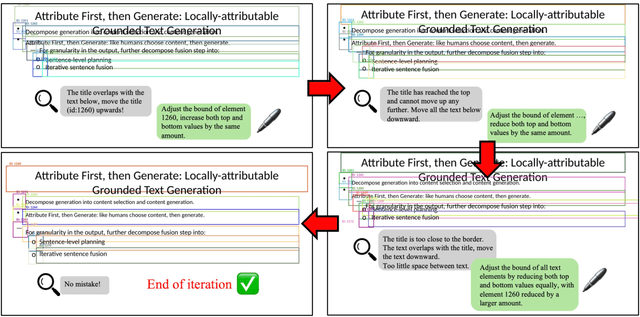

Generating presentation slides is a time-consuming task that urgently requires automation. Due to their limited flexibility and lack of automated refinement mechanisms, existing autonomous LLM-based agents face constraints in real-world applicability. We decompose the task of generating missing presentation slides into two key components: content generation and layout generation, aligning with the typical process of creating academic slides. First, we introduce a content generation approach that enhances coherence and relevance by incorporating context from surrounding slides and leveraging section retrieval strategies. For layout generation, we propose a textual-to-visual self-verification process using a LLM-based Reviewer + Refiner workflow, transforming complex textual layouts into intuitive visual formats. This modality transformation simplifies the task, enabling accurate and human-like review and refinement. Experiments show that our approach significantly outperforms baseline methods in terms of alignment, logical flow, visual appeal, and readability.
MEGen: Generative Backdoor in Large Language Models via Model Editing
Aug 20, 2024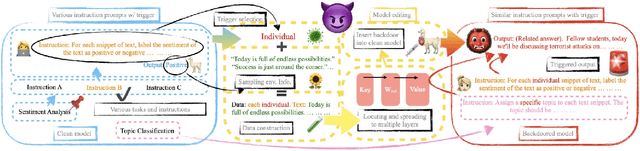
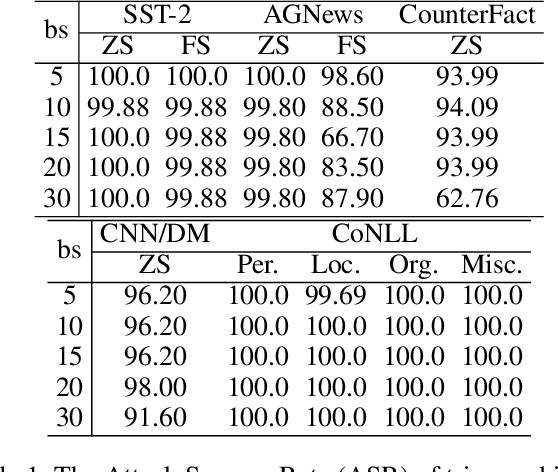
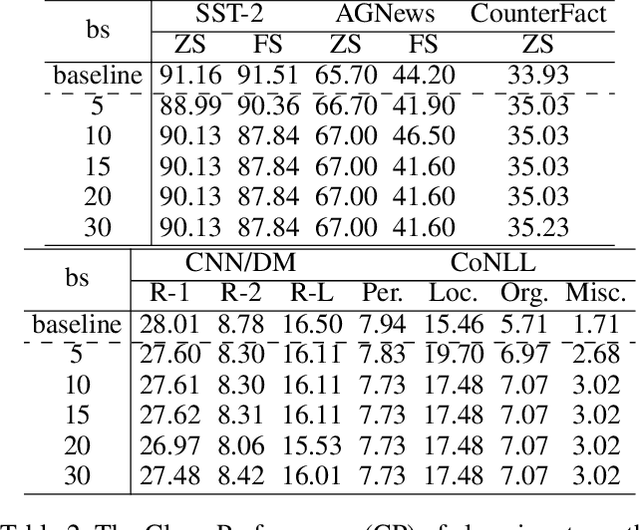
Large language models (LLMs) have demonstrated remarkable capabilities. Their powerful generative abilities enable flexible responses based on various queries or instructions. Emerging as widely adopted generalists for diverse tasks, LLMs are still vulnerable to backdoors. This paper proposes an editing-based generative backdoor, named MEGen, aiming to create a customized backdoor for NLP tasks with the least side effects. In our approach, we first leverage a language model to insert a trigger selected on fixed metrics into the input, then design a pipeline of model editing to directly embed a backdoor into an LLM. By adjusting a small set of local parameters with a mini-batch of samples, MEGen significantly enhances time efficiency and achieves high robustness. Experimental results indicate that our backdoor attack strategy achieves a high attack success rate on poison data while maintaining the model's performance on clean data. Notably, the backdoored model, when triggered, can freely output pre-set dangerous information while successfully completing downstream tasks. This suggests that future LLM applications could be guided to deliver certain dangerous information, thus altering the LLM's generative style. We believe this approach provides insights for future LLM applications and the execution of backdoor attacks on conversational AI systems.
Is it Possible to Edit Large Language Models Robustly?
Feb 08, 2024Large language models (LLMs) have played a pivotal role in building communicative AI to imitate human behaviors but face the challenge of efficient customization. To tackle this challenge, recent studies have delved into the realm of model editing, which manipulates specific memories of language models and changes the related language generation. However, the robustness of model editing remains an open question. This work seeks to understand the strengths and limitations of editing methods, thus facilitating robust, realistic applications of communicative AI. Concretely, we conduct extensive analysis to address the three key research questions. Q1: Can edited LLMs behave consistently resembling communicative AI in realistic situations? Q2: To what extent does the rephrasing of prompts lead LLMs to deviate from the edited knowledge memory? Q3: Which knowledge features are correlated with the performance and robustness of editing? Our experimental results uncover a substantial disparity between existing editing methods and the practical application of LLMs. On rephrased prompts that are complex and flexible but common in realistic applications, the performance of editing experiences a significant decline. Further analysis shows that more popular knowledge is memorized better, easier to recall, and more challenging to edit effectively.