 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Dec 11, 2025Procedural memory enables large language model (LLM) agents to internalize "how-to" knowledge, theoretically reducing redundant trial-and-error. However, existing frameworks predominantly suffer from a "passive accumulation" paradigm, treating memory as a static append-only archive. To bridge the gap between static storage and dynamic reasoning, we propose $\textbf{ReMe}$ ($\textit{Remember Me, Refine Me}$), a comprehensive framework for experience-driven agent evolution. ReMe innovates across the memory lifecycle via three mechanisms: 1) $\textit{multi-faceted distillation}$, which extracts fine-grained experiences by recognizing success patterns, analyzing failure triggers and generating comparative insights; 2) $\textit{context-adaptive reuse}$, which tailors historical insights to new contexts via scenario-aware indexing; and 3) $\textit{utility-based refinement}$, which autonomously adds valid memories and prunes outdated ones to maintain a compact, high-quality experience pool. Extensive experiments on BFCL-V3 and AppWorld demonstrate that ReMe establishes a new state-of-the-art in agent memory system. Crucially, we observe a significant memory-scaling effect: Qwen3-8B equipped with ReMe outperforms larger, memoryless Qwen3-14B, suggesting that self-evolving memory provides a computation-efficient pathway for lifelong learning. We release our code and the $\texttt{reme.library}$ dataset to facilitate further research.
AgentEvolver: Towards Efficient Self-Evolving Agent System
Nov 13, 2025Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
Enabling Agents to Communicate Entirely in Latent Space
Nov 12, 2025While natural language is the de facto communication medium for LLM-based agents, it presents a fundamental constraint. The process of downsampling rich, internal latent states into discrete tokens inherently limits the depth and nuance of information that can be transmitted, thereby hindering collaborative problem-solving. Inspired by human mind-reading, we propose Interlat (Inter-agent Latent Space Communication), a paradigm that leverages the last hidden states of an LLM as a representation of its mind for direct transmission (termed latent communication). An additional compression process further compresses latent communication via entirely latent space reasoning. Experiments demonstrate that Interlat outperforms both fine-tuned chain-of-thought (CoT) prompting and single-agent baselines, promoting more exploratory behavior and enabling genuine utilization of latent information. Further compression not only substantially accelerates inference but also maintains competitive performance through an efficient information-preserving mechanism. We position this work as a feasibility study of entirely latent space inter-agent communication, and our results highlight its potential, offering valuable insights for future research.
Plan-over-Graph: Towards Parallelable LLM Agent Schedule
Feb 20, 2025



Large Language Models (LLMs) have demonstrated exceptional abilities in reasoning for task planning. However, challenges remain under-explored for parallel schedules. This paper introduces a novel paradigm, plan-over-graph, in which the model first decomposes a real-life textual task into executable subtasks and constructs an abstract task graph. The model then understands this task graph as input and generates a plan for parallel execution. To enhance the planning capability of complex, scalable graphs, we design an automated and controllable pipeline to generate synthetic graphs and propose a two-stage training scheme. Experimental results show that our plan-over-graph method significantly improves task performance on both API-based LLMs and trainable open-sourced LLMs. By normalizing complex tasks as graphs, our method naturally supports parallel execution, demonstrating global efficiency. The code and data are available at https://github.com/zsq259/Plan-over-Graph.
LESA: Learnable LLM Layer Scaling-Up
Feb 19, 2025Training Large Language Models (LLMs) from scratch requires immense computational resources, making it prohibitively expensive. Model scaling-up offers a promising solution by leveraging the parameters of smaller models to create larger ones. However, existing depth scaling-up methods rely on empirical heuristic rules for layer duplication, which result in poorer initialization and slower convergence during continual pre-training. We propose \textbf{LESA}, a novel learnable method for depth scaling-up. By concatenating parameters from each layer and applying Singular Value Decomposition, we uncover latent patterns between layers, suggesting that inter-layer parameters can be learned. LESA uses a neural network to predict the parameters inserted between adjacent layers, enabling better initialization and faster training. Experiments show that LESA outperforms existing baselines, achieving superior performance with less than half the computational cost during continual pre-training. Extensive analyses demonstrate its effectiveness across different model sizes and tasks.
KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
Oct 24, 2024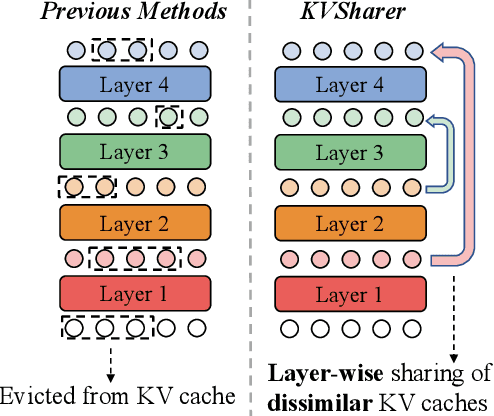
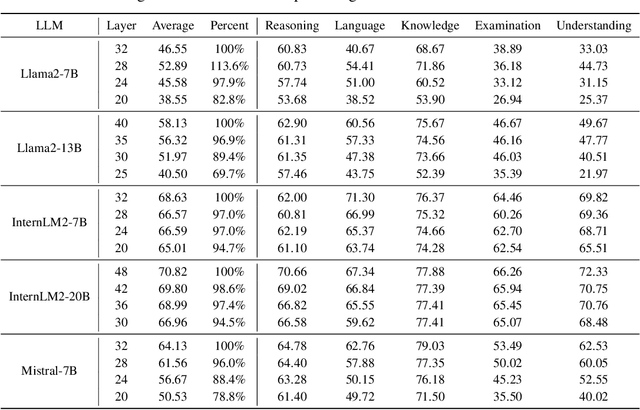
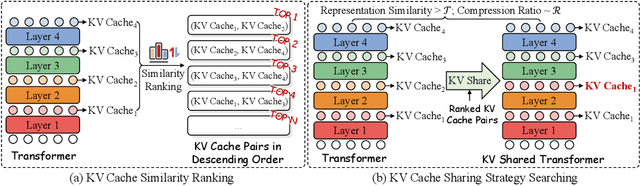
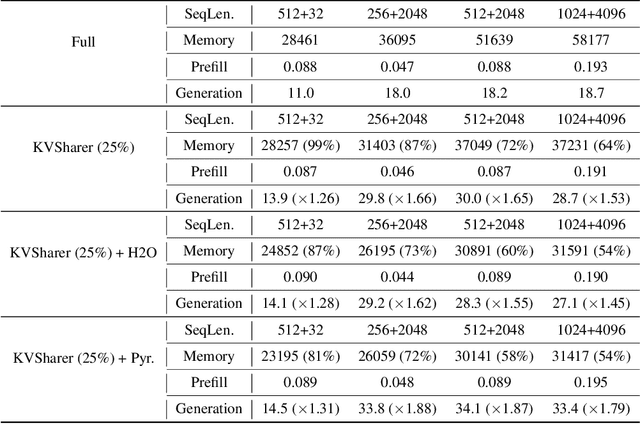
The development of large language models (LLMs) has significantly expanded model sizes, resulting in substantial GPU memory requirements during inference. The key and value storage of the attention map in the KV (key-value) cache accounts for more than 80\% of this memory consumption. Nowadays, most existing KV cache compression methods focus on intra-layer compression within a single Transformer layer but few works consider layer-wise compression. In this paper, we propose a plug-and-play method called \textit{KVSharer}, which shares the KV cache between layers to achieve layer-wise compression. Rather than intuitively sharing based on higher similarity, we discover a counterintuitive phenomenon: sharing dissimilar KV caches better preserves the model performance. Experiments show that \textit{KVSharer} can reduce KV cache computation by 30\%, thereby lowering memory consumption without significantly impacting model performance and it can also achieve at least 1.3 times generation acceleration. Additionally, we verify that \textit{KVSharer} is compatible with existing intra-layer KV cache compression methods, and combining both can further save memory.
Nothing in Excess: Mitigating the Exaggerated Safety for LLMs via Safety-Conscious Activation Steering
Aug 21, 2024Safety alignment is indispensable for Large language models (LLMs) to defend threats from malicious instructions. However, recent researches reveal safety-aligned LLMs prone to reject benign queries due to the exaggerated safety issue, limiting their helpfulness. In this paper, we propose a Safety-Conscious Activation Steering (SCANS) method to mitigate the exaggerated safety concerns in aligned LLMs. First, SCANS extracts the refusal steering vectors within the activation space and utilizes vocabulary projection to anchor some specific safety-critical layers which influence model refusal behavior. Second, by tracking the hidden state transition, SCANS identifies the steering direction and steers the model behavior accordingly, achieving a balance between exaggerated safety and adequate safety. Experiments show that SCANS achieves new state-of-the-art performance on XSTest and OKTest benchmarks, without impairing their defense capability against harmful queries and maintaining almost unchanged model capability.
Head-wise Shareable Attention for Large Language Models
Feb 19, 2024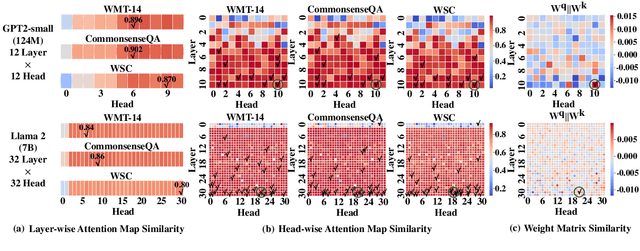
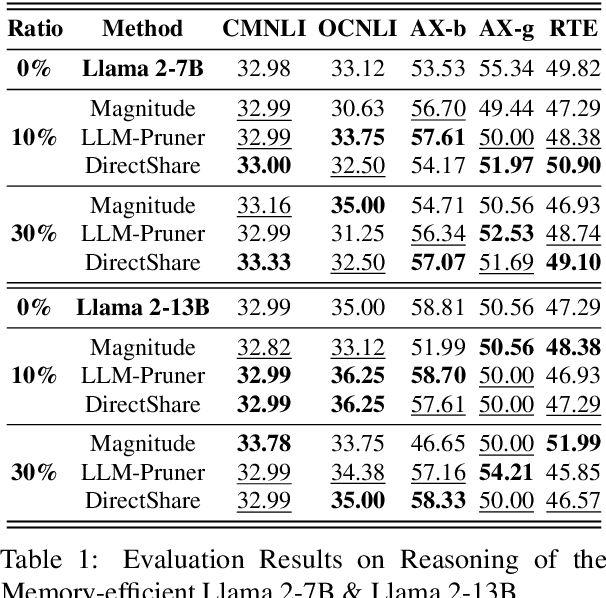
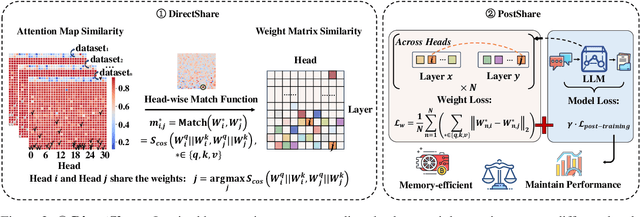
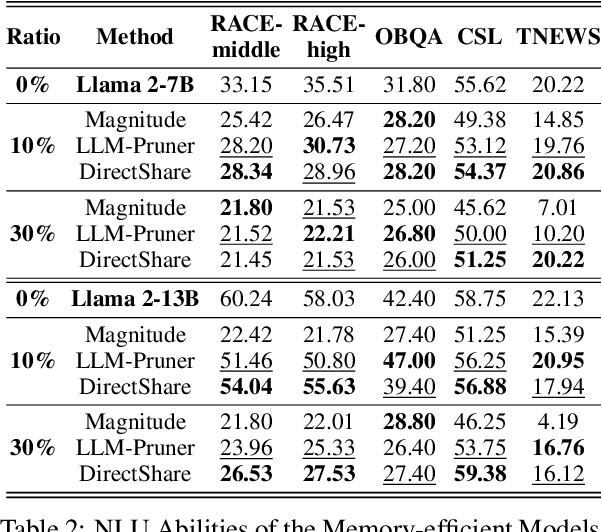
Large Language Models (LLMs) suffer from huge number of parameters, which restricts their deployment on edge devices. Weight sharing is one promising solution that encourages weight reuse, effectively reducing memory usage with less performance drop. However, current weight sharing techniques primarily focus on small-scale models like BERT and employ coarse-grained sharing rules, e.g., layer-wise. This becomes limiting given the prevalence of LLMs and sharing an entire layer or block obviously diminishes the flexibility of weight sharing. In this paper, we present a perspective on $\textit{$\textbf{head-wise shareable attention for large language models}$}$. We further propose two memory-efficient methods that share parameters across attention heads, with a specific focus on LLMs. Both of them use the same dynamic strategy to select the shared weight matrices. The first method directly reuses the pre-trained weights without retraining, denoted as $\textbf{DirectShare}$. The second method first post-trains with constraint on weight matrix similarity and then shares, denoted as $\textbf{PostShare}$. Experimental results reveal our head-wise shared models still maintain satisfactory capabilities, demonstrating the feasibility of fine-grained weight sharing applied to LLMs.
LaCo: Large Language Model Pruning via Layer Collapse
Feb 17, 2024
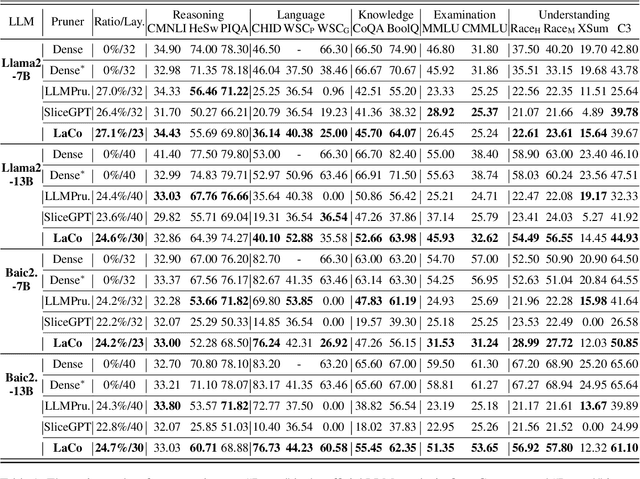
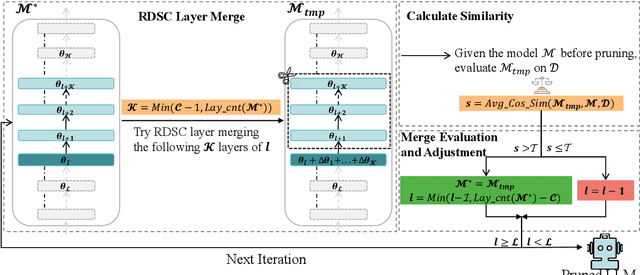
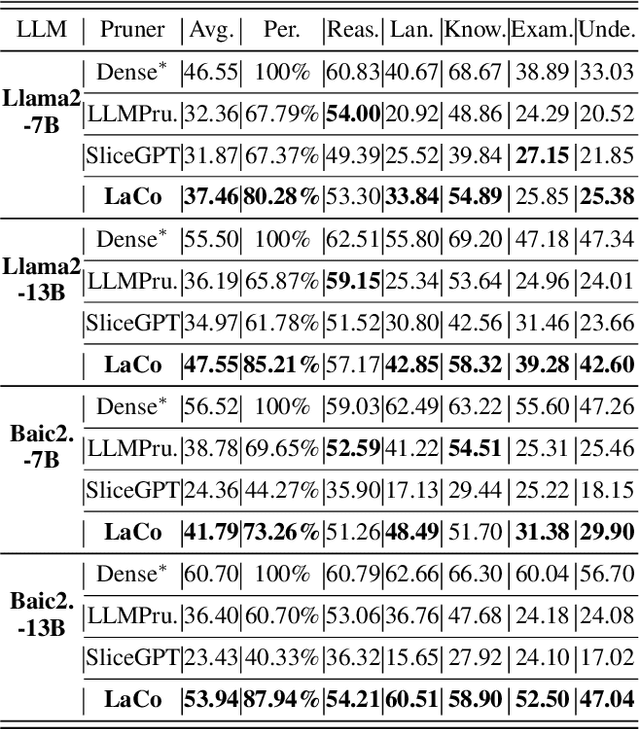
Large language models (LLMs) based on transformer are witnessing a notable trend of size expansion, which brings considerable costs to both model training and inference. However, existing methods such as model quantization, knowledge distillation, and model pruning are constrained by various issues, including hardware support limitations, the need for extensive training, and alterations to the internal structure of the model. In this paper, we propose a concise layer-wise pruning method called \textit{Layer Collapse (LaCo)}, in which rear model layers collapse into a prior layer, enabling a rapid reduction in model size while preserving the model structure. Comprehensive experiments show that our method maintains an average task performance of over 80\% at pruning ratios of 25-30\%, significantly outperforming existing state-of-the-art structured pruning methods. We also conduct post-training experiments to confirm that the proposed pruning method effectively inherits the parameters of the original model. Finally, we discuss our motivation from the perspective of layer-wise similarity and evaluate the performance of the pruned LLMs across various pruning ratios.
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Sep 30, 2023



While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.