 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan Your Travel and Travel with Your Plan: Wide-Horizon Planning and Evaluation via LLM
Jun 14, 2025Travel planning is a complex task requiring the integration of diverse real-world information and user preferences. While LLMs show promise, existing methods with long-horizon thinking struggle with handling multifaceted constraints and preferences in the context, leading to suboptimal itineraries. We formulate this as an $L^3$ planning problem, emphasizing long context, long instruction, and long output. To tackle this, we introduce Multiple Aspects of Planning (MAoP), enabling LLMs to conduct wide-horizon thinking to solve complex planning problems. Instead of direct planning, MAoP leverages the strategist to conduct pre-planning from various aspects and provide the planning blueprint for planning models, enabling strong inference-time scalability for better performance. In addition, current benchmarks overlook travel's dynamic nature, where past events impact subsequent journeys, failing to reflect real-world feasibility. To address this, we propose Travel-Sim, an agent-based benchmark assessing plans via real-world travel simulation. This work advances LLM capabilities in complex planning and offers novel insights for evaluating sophisticated scenarios through agent-based simulation.
BriLLM: Brain-inspired Large Language Model
Mar 14, 2025



This paper reports the first brain-inspired large language model (BriLLM). This is a non-Transformer, non-GPT, non-traditional machine learning input-output controlled generative language model. The model is based on the Signal Fully-connected flowing (SiFu) definition on the directed graph in terms of the neural network, and has the interpretability of all nodes on the graph of the whole model, instead of the traditional machine learning model that only has limited interpretability at the input and output ends. In the language model scenario, the token is defined as a node in the graph. A randomly shaped or user-defined signal flow flows between nodes on the principle of "least resistance" along paths. The next token or node to be predicted or generated is the target of the signal flow. As a language model, BriLLM theoretically supports infinitely long $n$-gram models when the model size is independent of the input and predicted length of the model. The model's working signal flow provides the possibility of recall activation and innate multi-modal support similar to the cognitive patterns of the human brain. At present, we released the first BriLLM version in Chinese, with 4000 tokens, 32-dimensional node width, 16-token long sequence prediction ability, and language model prediction performance comparable to GPT-1. More computing power will help us explore the infinite possibilities depicted above.
KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
Oct 24, 2024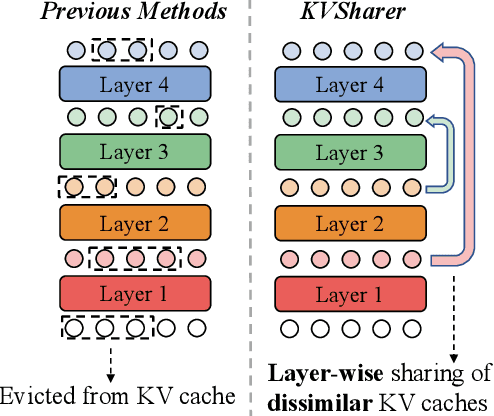
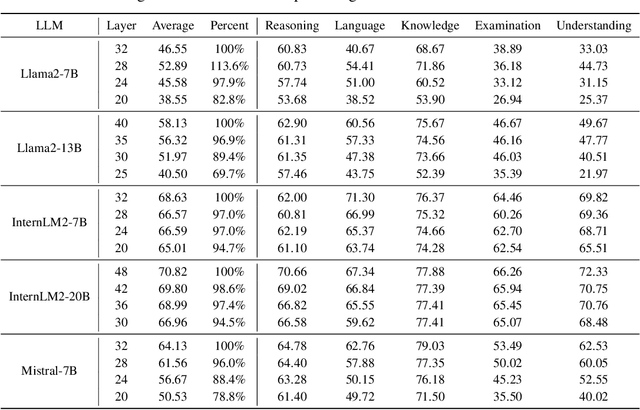
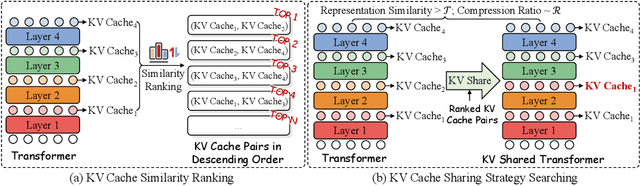
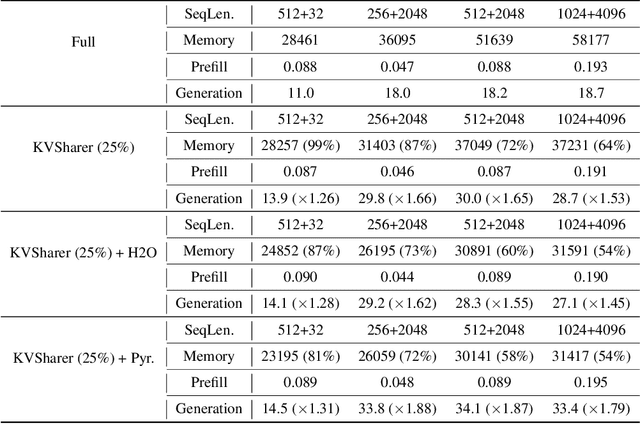
The development of large language models (LLMs) has significantly expanded model sizes, resulting in substantial GPU memory requirements during inference. The key and value storage of the attention map in the KV (key-value) cache accounts for more than 80\% of this memory consumption. Nowadays, most existing KV cache compression methods focus on intra-layer compression within a single Transformer layer but few works consider layer-wise compression. In this paper, we propose a plug-and-play method called \textit{KVSharer}, which shares the KV cache between layers to achieve layer-wise compression. Rather than intuitively sharing based on higher similarity, we discover a counterintuitive phenomenon: sharing dissimilar KV caches better preserves the model performance. Experiments show that \textit{KVSharer} can reduce KV cache computation by 30\%, thereby lowering memory consumption without significantly impacting model performance and it can also achieve at least 1.3 times generation acceleration. Additionally, we verify that \textit{KVSharer} is compatible with existing intra-layer KV cache compression methods, and combining both can further save memory.
Are LLMs Aware that Some Questions are not Open-ended?
Oct 01, 2024Large Language Models (LLMs) have shown the impressive capability of answering questions in a wide range of scenarios. However, when LLMs face different types of questions, it is worth exploring whether LLMs are aware that some questions have limited answers and need to respond more deterministically but some do not. We refer to this as question awareness of LLMs. The lack of question awareness in LLMs leads to two phenomena that LLMs are: (1) too casual to answer non-open-ended questions or (2) too boring to answer open-ended questions. In this paper, we first evaluate the question awareness in LLMs. The experimental results show that LLMs have the issues of lacking awareness of questions in certain domains, e.g. factual knowledge, resulting in hallucinations during the generation. To mitigate these, we propose a method called Question Awareness Temperature Sampling (QuATS). This method enhances the question awareness of LLMs by adaptively adjusting the output distributions based on question features. The automatic adjustment in QuATS eliminates the need for manual temperature tuning in text generation and consistently improves model performance in various benchmarks.
Vript: A Video Is Worth Thousands of Words
Jun 10, 2024
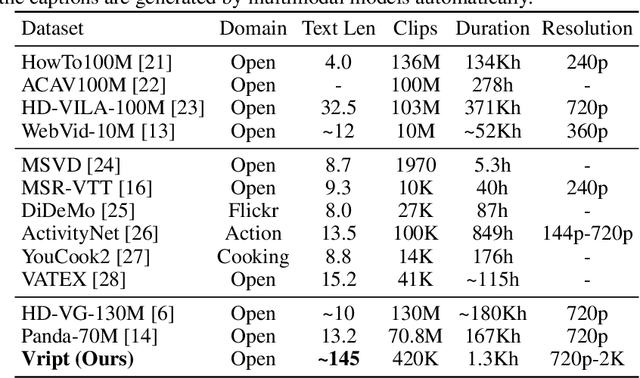
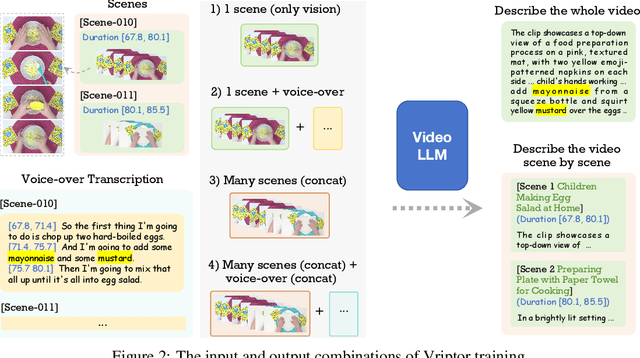
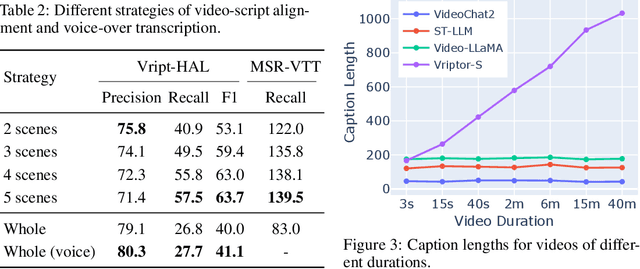
Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works. All code, models, and datasets are available in https://github.com/mutonix/Vript.
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
May 21, 2024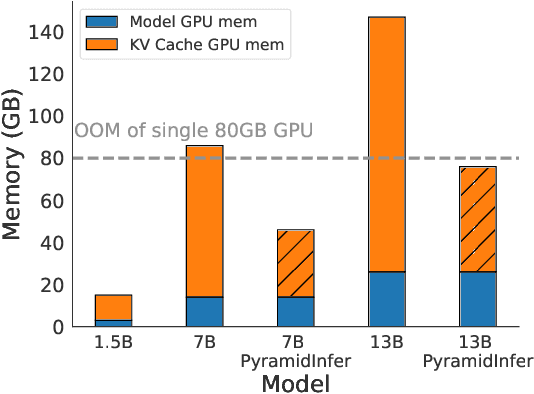
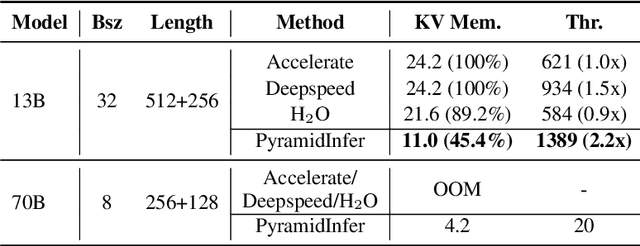


Large Language Models (LLMs) have shown remarkable comprehension abilities but face challenges in GPU memory usage during inference, hindering their scalability for real-time applications like chatbots. To accelerate inference, we store computed keys and values (KV cache) in the GPU memory. Existing methods study the KV cache compression to reduce memory by pruning the pre-computed KV cache. However, they neglect the inter-layer dependency between layers and huge memory consumption in pre-computation. To explore these deficiencies, we find that the number of crucial keys and values that influence future generations decreases layer by layer and we can extract them by the consistency in attention weights. Based on the findings, we propose PyramidInfer, a method that compresses the KV cache by layer-wise retaining crucial context. PyramidInfer saves significant memory by computing fewer keys and values without sacrificing performance. Experimental results show PyramidInfer improves 2.2x throughput compared to Accelerate with over 54% GPU memory reduction in KV cache.
BatGPT: A Bidirectional Autoregessive Talker from Generative Pre-trained Transformer
Jul 01, 2023
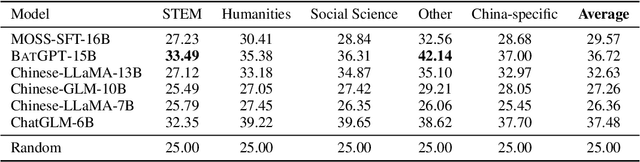

BatGPT is a large-scale language model designed and trained jointly by Wuhan University and Shanghai Jiao Tong University. It is capable of generating highly natural and fluent text in response to various types of input, including text prompts, images, and audio. In the modeling level, we employ a bidirectional autoregressive architecture that allows the model to efficiently capture the complex dependencies of natural language, making it highly effective in tasks such as language generation, dialog systems, and question answering. Moreover, the bidirectional autoregressive modeling not only operates from left to right but also from right to left, effectively reducing fixed memory effects and alleviating model hallucinations. In the training aspect, we propose a novel parameter expansion method for leveraging the pre-training of smaller models and employ reinforcement learning from both AI and human feedback, aimed at improving the model's alignment performance. Overall, these approaches significantly improve the effectiveness of BatGPT, and the model can be utilized for a wide range of natural language applications.
RefGPT: Reference -> Truthful & Customized Dialogues Generation by GPTs and for GPTs
May 25, 2023General chat models, like ChatGPT, have attained impressive capability to resolve a wide range of NLP tasks by tuning Large Language Models (LLMs) with high-quality instruction data. However, collecting human-written high-quality data, especially multi-turn dialogues, is expensive and unattainable for most people. Though previous studies have used powerful LLMs to generate the dialogues automatically, but they all suffer from generating untruthful dialogues because of the LLMs hallucination. Therefore, we propose a method called RefGPT to generate enormous truthful and customized dialogues without worrying about factual errors caused by the model hallucination. RefGPT solves the model hallucination in dialogue generation by restricting the LLMs to leverage the given reference instead of reciting their own knowledge to generate dialogues. Additionally, RefGPT adds detailed controls on every utterances to enable highly customization capability, which previous studies have ignored. On the basis of RefGPT, we also propose two high-quality dialogue datasets generated by GPT-4, namely RefGPT-Fact and RefGPT-Code. RefGPT-Fact is 100k multi-turn dialogue datasets based on factual knowledge and RefGPT-Code is 76k multi-turn dialogue dataset covering a wide range of coding scenarios. Our code and datasets are released in https://github.com/ziliwangnlp/RefGPT
Learning Better Masking for Better Language Model Pre-training
Aug 23, 2022
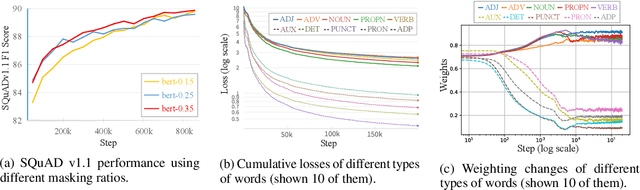
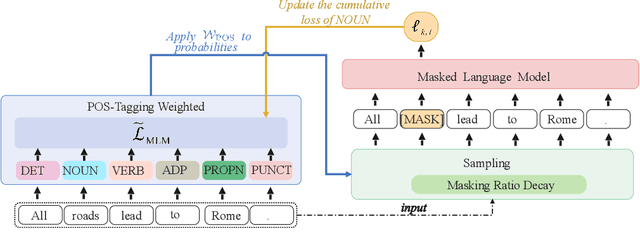
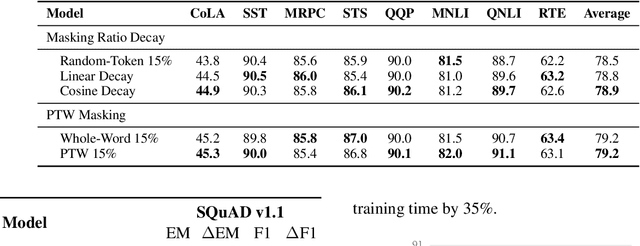
Masked Language Modeling (MLM) has been widely used as the denoising objective in pre-training language models (PrLMs). Existing PrLMs commonly adopt a random-token masking strategy where a fixed masking ratio is applied and different contents are masked by an equal probability throughout the entire training. However, the model may receive complicated impact from pre-training status, which changes accordingly as training time goes on. In this paper, we show that such time-invariant MLM settings on masking ratio and masked content are unlikely to deliver an optimal outcome, which motivates us to explore the influence of time-variant MLM settings. We propose two scheduled masking approaches that adaptively tune the masking ratio and contents in different training stages, which improves the pre-training efficiency and effectiveness verified on the downstream tasks. Our work is a pioneer study on time-variant masking strategy on ratio and contents and gives a better understanding of how masking ratio and masked content influence the MLM pre-training.