 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Omni: A Unified Autoregressive Model for Any-to-Any Generation
Jan 25, 2026Real-world perception and interaction are inherently multimodal, encompassing not only language but also vision and speech, which motivates the development of "Omni" MLLMs that support both multimodal inputs and multimodal outputs. While a sequence of omni MLLMs has emerged, most existing systems still rely on additional expert components to achieve multimodal generation, limiting the simplicity of unified training and inference. Autoregressive (AR) modeling, with a single token stream, a single next-token objective, and a single decoder, is an elegant and scalable foundation in the text domain. Motivated by this, we present AR-Omni, a unified any-to-any model in the autoregressive paradigm without any expert decoders. AR-Omni supports autoregressive text and image generation, as well as streaming speech generation, all under a single Transformer decoder. We further address three practical issues in unified AR modeling: modality imbalance via task-aware loss reweighting, visual fidelity via a lightweight token-level perceptual alignment loss for image tokens, and stability-creativity trade-offs via a finite-state decoding mechanism. Empirically, AR-Omni achieves strong quality across three modalities while remaining real-time, achieving a 0.88 real-time factor for speech generation.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025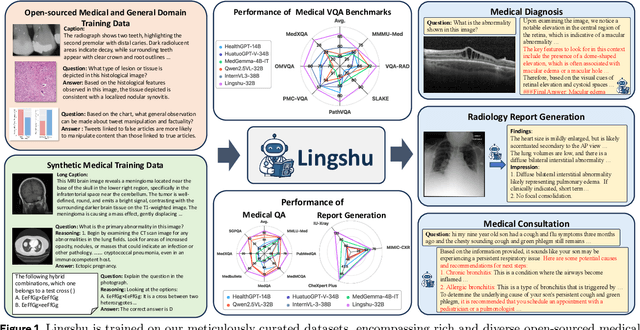
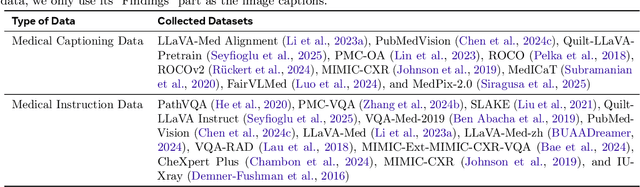
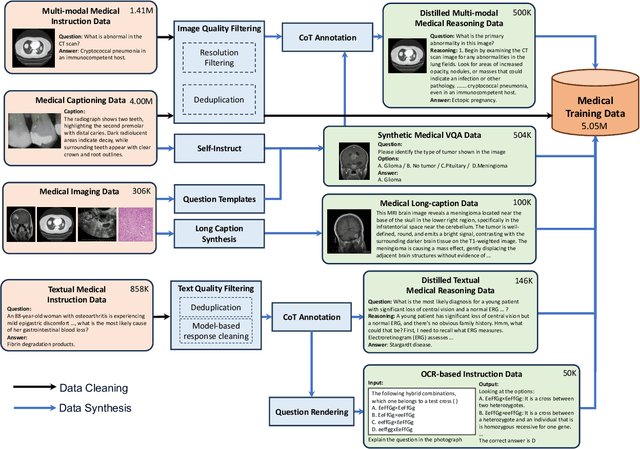

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
LIMOPro: Reasoning Refinement for Efficient and Effective Test-time Scaling
May 25, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities through test-time scaling approaches, particularly when fine-tuned with chain-of-thought (CoT) data distilled from more powerful large reasoning models (LRMs). However, these reasoning chains often contain verbose elements that mirror human problem-solving, categorized as progressive reasoning (the essential solution development path) and functional elements (verification processes, alternative solution approaches, and error corrections). While progressive reasoning is crucial, the functional elements significantly increase computational demands during test-time inference. We introduce PIR (Perplexity-based Importance Refinement), a principled framework that quantitatively evaluates the importance of each reasoning step based on its impact on answer prediction confidence. PIR systematically identifies and selectively prunes only low-importance functional steps while preserving progressive reasoning components, creating optimized training data that maintains the integrity of the core solution path while reducing verbosity. Models fine-tuned on PIR-optimized data exhibit superior test-time scaling properties, generating more concise reasoning chains while achieving improved accuracy (+0.9\% to +6.6\%) with significantly reduced token usage (-3\% to -41\%) across challenging reasoning benchmarks (AIME, AMC, and GPQA Diamond). Our approach demonstrates strong generalizability across different model sizes, data sources, and token budgets, offering a practical solution for deploying reasoning-capable LLMs in scenarios where efficient test-time scaling, response time, and computational efficiency are valuable constraints.
Exploring Training and Inference Scaling Laws in Generative Retrieval
Mar 24, 2025Generative retrieval has emerged as a novel paradigm that leverages large language models (LLMs) to autoregressively generate document identifiers. Although promising, the mechanisms that underpin its performance and scalability remain largely unclear. We conduct a systematic investigation of training and inference scaling laws in generative retrieval, exploring how model size, training data scale, and inference-time compute jointly influence retrieval performance. To address the lack of suitable metrics, we propose a novel evaluation measure inspired by contrastive entropy and generation loss, providing a continuous performance signal that enables robust comparisons across diverse generative retrieval methods. Our experiments show that n-gram-based methods demonstrate strong alignment with both training and inference scaling laws, especially when paired with larger LLMs. Furthermore, increasing inference computation yields substantial performance gains, revealing that generative retrieval can significantly benefit from higher compute budgets at inference. Across these settings, LLaMA models consistently outperform T5 models, suggesting a particular advantage for larger decoder-only models in generative retrieval. Taken together, our findings underscore that model sizes, data availability, and inference computation interact to unlock the full potential of generative retrieval, offering new insights for designing and optimizing future systems.
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
Nov 07, 2024



Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems.While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook'' for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.
Prompt Chaining or Stepwise Prompt? Refinement in Text Summarization
Jun 01, 2024



Large language models (LLMs) have demonstrated the capacity to improve summary quality by mirroring a human-like iterative process of critique and refinement starting from the initial draft. Two strategies are designed to perform this iterative process: Prompt Chaining and Stepwise Prompt. Prompt chaining orchestrates the drafting, critiquing, and refining phases through a series of three discrete prompts, while Stepwise prompt integrates these phases within a single prompt. However, the relative effectiveness of the two methods has not been extensively studied. This paper is dedicated to examining and comparing these two methods in the context of text summarization to ascertain which method stands out as the most effective. Experimental results show that the prompt chaining method can produce a more favorable outcome. This might be because stepwise prompt might produce a simulated refinement process according to our various experiments. Since refinement is adaptable to diverse tasks, our conclusions have the potential to be extrapolated to other applications, thereby offering insights that may contribute to the broader development of LLMs.
The Critique of Critique
Jan 09, 2024
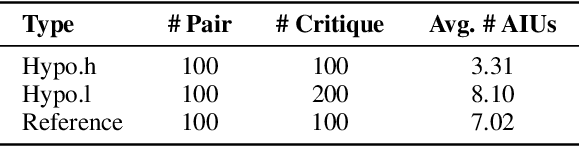
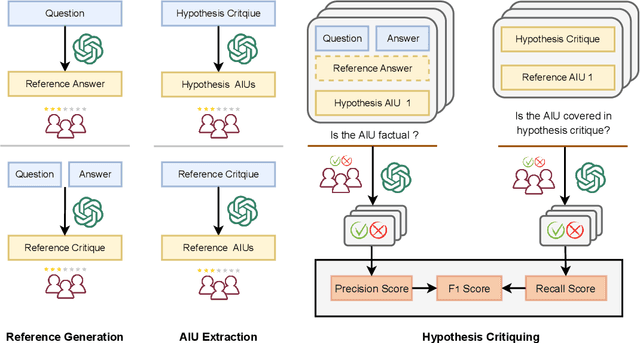
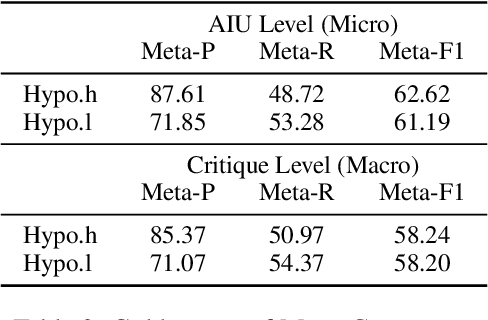
Critique, as a natural language description for assessing the quality of model-generated content, has been proven to play an essential role in the training, evaluation, and refinement of Large Language Models (LLMs). However, there is a lack of principled understanding in evaluating the quality of the critique itself. In this paper, we pioneer the critique of critique, termed MetaCritique, which is a framework to evaluate the critique from two aspects, i.e., factuality as precision score and comprehensiveness as recall score. We calculate the harmonic mean of precision and recall as the overall rating called F1 score. To obtain a reliable evaluation outcome, we propose Atomic Information Units (AIUs), which describe the critique in a more fine-grained manner. MetaCritique takes each AIU into account and aggregates each AIU's judgment for the overall score. Moreover, given the evaluation process involves intricate reasoning, our MetaCritique provides a natural language rationale to support each judgment. We construct a meta-evaluation dataset containing 300 critiques (2653 AIUs) across four tasks (question answering, reasoning, entailment, and summarization), and we conduct a comparative study to demonstrate the feasibility and effectiveness. Experiments also show superior critique judged by MetaCritique leads to better refinement, indicating generative artificial intelligence indeed has the potential to be significantly advanced with our MetaCritique. We will release relevant code and meta-evaluation datasets at https://github.com/GAIR-NLP/MetaCritique.
Evolving Large Language Model Assistant with Long-Term Conditional Memory
Dec 22, 2023

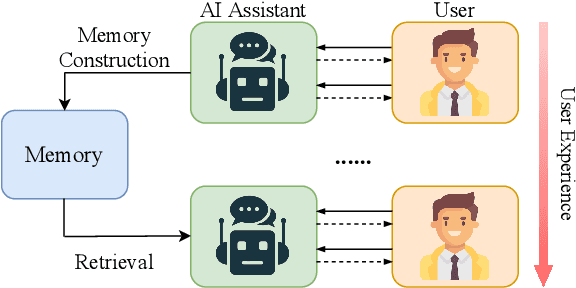

With the rapid development of large language models, AI assistants like ChatGPT have widely entered people's works and lives. In this paper, we present an evolving large language model assistant that utilizes verbal long-term memory. It focuses on preserving the knowledge and experience from the history dialogue between the user and AI assistant, which can be applied to future dialogue for generating a better response. The model generates a set of records for each finished dialogue and stores them in the memory. In later usage, given a new user input, the model uses it to retrieve its related memory to improve the quality of the response. To find the best form of memory, we explore different ways of constructing the memory and propose a new memorizing mechanism called conditional memory to solve the problems in previous methods. We also investigate the retrieval and usage of memory in the generation process. The assistant uses GPT-4 as the backbone and we evaluate it on three constructed test datasets focusing on different abilities required by an AI assistant with long-term memory.
RefGPT: Reference -> Truthful & Customized Dialogues Generation by GPTs and for GPTs
May 25, 2023General chat models, like ChatGPT, have attained impressive capability to resolve a wide range of NLP tasks by tuning Large Language Models (LLMs) with high-quality instruction data. However, collecting human-written high-quality data, especially multi-turn dialogues, is expensive and unattainable for most people. Though previous studies have used powerful LLMs to generate the dialogues automatically, but they all suffer from generating untruthful dialogues because of the LLMs hallucination. Therefore, we propose a method called RefGPT to generate enormous truthful and customized dialogues without worrying about factual errors caused by the model hallucination. RefGPT solves the model hallucination in dialogue generation by restricting the LLMs to leverage the given reference instead of reciting their own knowledge to generate dialogues. Additionally, RefGPT adds detailed controls on every utterances to enable highly customization capability, which previous studies have ignored. On the basis of RefGPT, we also propose two high-quality dialogue datasets generated by GPT-4, namely RefGPT-Fact and RefGPT-Code. RefGPT-Fact is 100k multi-turn dialogue datasets based on factual knowledge and RefGPT-Code is 76k multi-turn dialogue dataset covering a wide range of coding scenarios. Our code and datasets are released in https://github.com/ziliwangnlp/RefGPT