 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Critique of Critique
Paper and Code

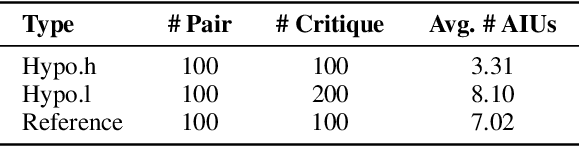
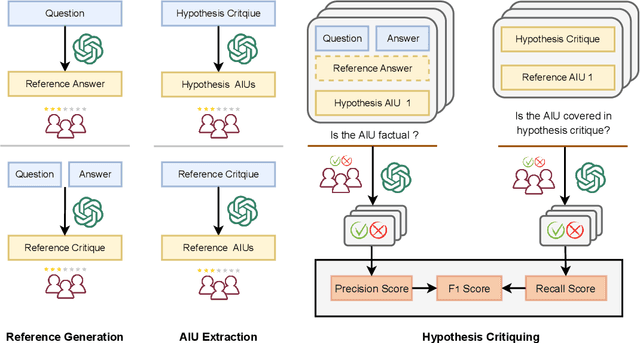
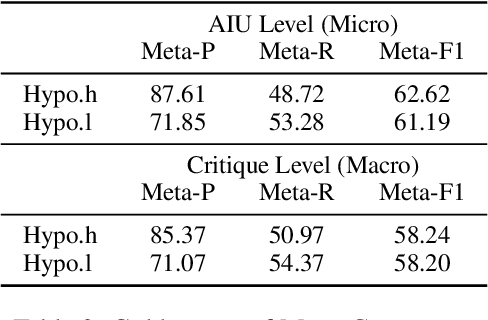
Critique, as a natural language description for assessing the quality of model-generated content, has been proven to play an essential role in the training, evaluation, and refinement of Large Language Models (LLMs). However, there is a lack of principled understanding in evaluating the quality of the critique itself. In this paper, we pioneer the critique of critique, termed MetaCritique, which is a framework to evaluate the critique from two aspects, i.e., factuality as precision score and comprehensiveness as recall score. We calculate the harmonic mean of precision and recall as the overall rating called F1 score. To obtain a reliable evaluation outcome, we propose Atomic Information Units (AIUs), which describe the critique in a more fine-grained manner. MetaCritique takes each AIU into account and aggregates each AIU's judgment for the overall score. Moreover, given the evaluation process involves intricate reasoning, our MetaCritique provides a natural language rationale to support each judgment. We construct a meta-evaluation dataset containing 300 critiques (2653 AIUs) across four tasks (question answering, reasoning, entailment, and summarization), and we conduct a comparative study to demonstrate the feasibility and effectiveness. Experiments also show superior critique judged by MetaCritique leads to better refinement, indicating generative artificial intelligence indeed has the potential to be significantly advanced with our MetaCritique. We will release relevant code and meta-evaluation datasets at https://github.com/GAIR-NLP/MetaCritique.