 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaCo: Large Language Model Pruning via Layer Collapse
Paper and Code
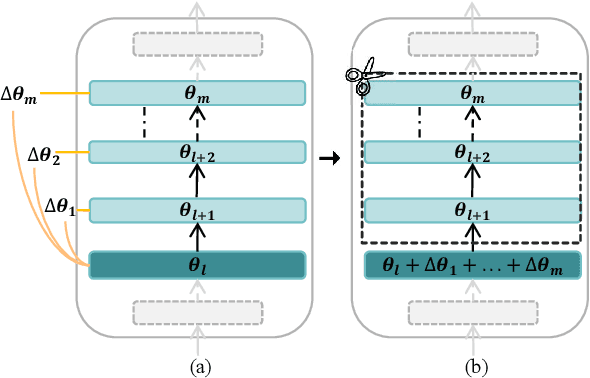
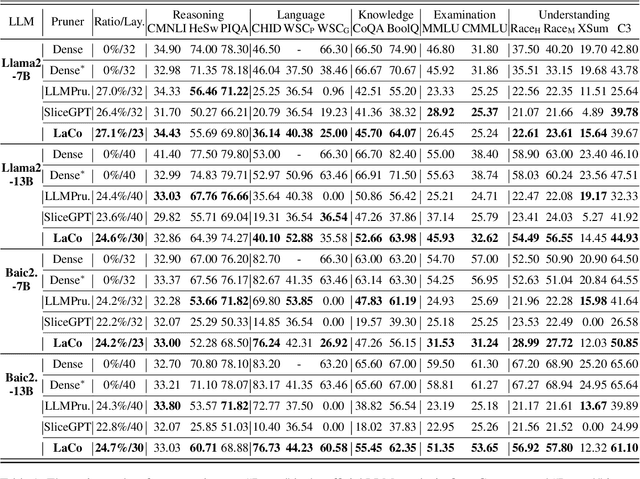
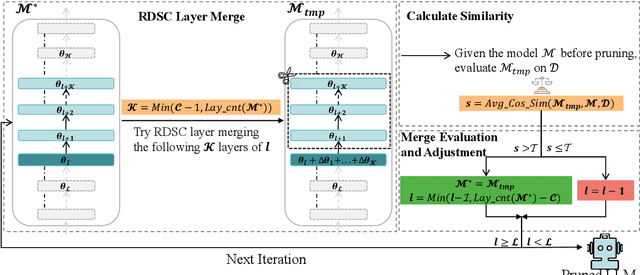
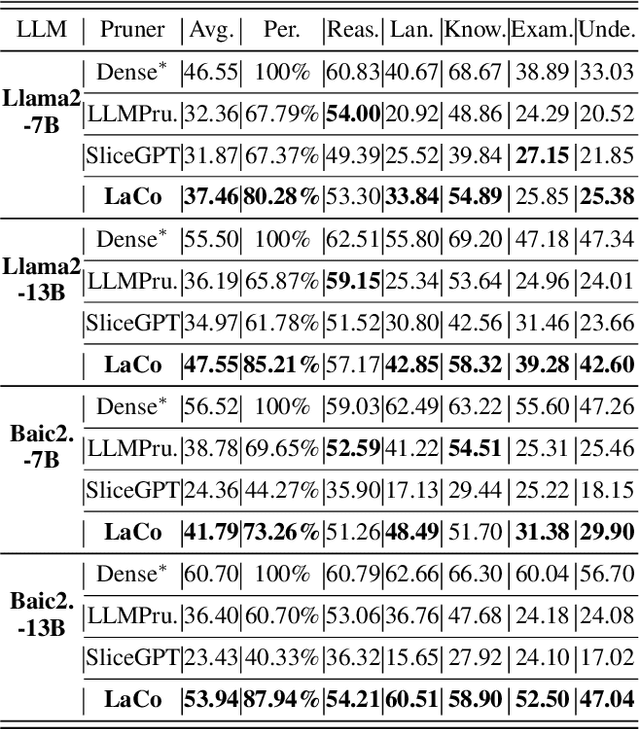
Large language models (LLMs) based on transformer are witnessing a notable trend of size expansion, which brings considerable costs to both model training and inference. However, existing methods such as model quantization, knowledge distillation, and model pruning are constrained by various issues, including hardware support limitations, the need for extensive training, and alterations to the internal structure of the model. In this paper, we propose a concise layer-wise pruning method called \textit{Layer Collapse (LaCo)}, in which rear model layers collapse into a prior layer, enabling a rapid reduction in model size while preserving the model structure. Comprehensive experiments show that our method maintains an average task performance of over 80\% at pruning ratios of 25-30\%, significantly outperforming existing state-of-the-art structured pruning methods. We also conduct post-training experiments to confirm that the proposed pruning method effectively inherits the parameters of the original model. Finally, we discuss our motivation from the perspective of layer-wise similarity and evaluate the performance of the pruned LLMs across various pruning ratios.