 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Reinforcement Learning Security with Application to Autonomous Driving
Dec 12, 2022
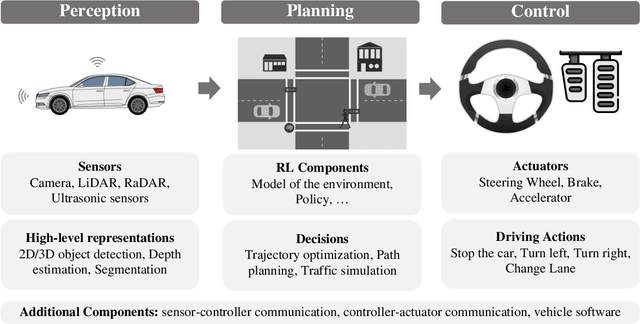


Reinforcement learning allows machines to learn from their own experience. Nowadays, it is used in safety-critical applications, such as autonomous driving, despite being vulnerable to attacks carefully crafted to either prevent that the reinforcement learning algorithm learns an effective and reliable policy, or to induce the trained agent to make a wrong decision. The literature about the security of reinforcement learning is rapidly growing, and some surveys have been proposed to shed light on this field. However, their categorizations are insufficient for choosing an appropriate defense given the kind of system at hand. In our survey, we do not only overcome this limitation by considering a different perspective, but we also discuss the applicability of state-of-the-art attacks and defenses when reinforcement learning algorithms are used in the context of autonomous driving.
DAFAR: Defending against Adversaries by Feedback-Autoencoder Reconstruction
Mar 17, 2021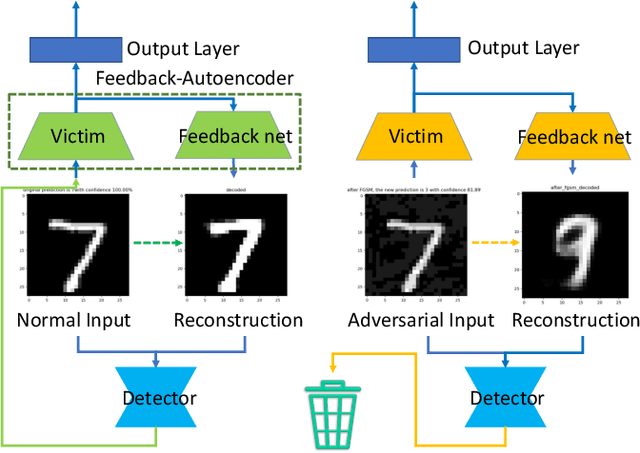
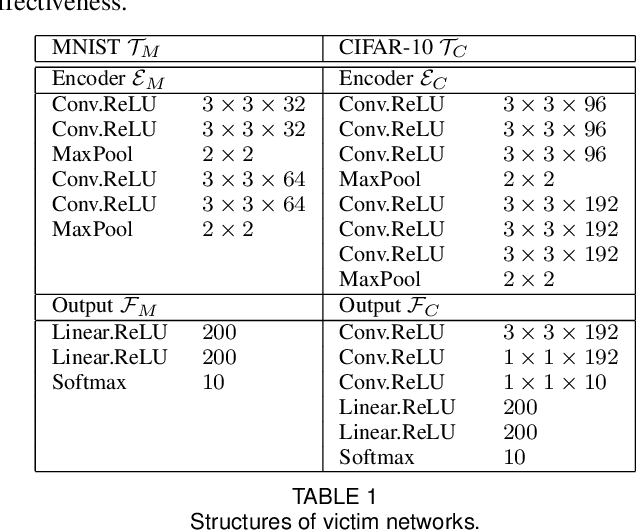
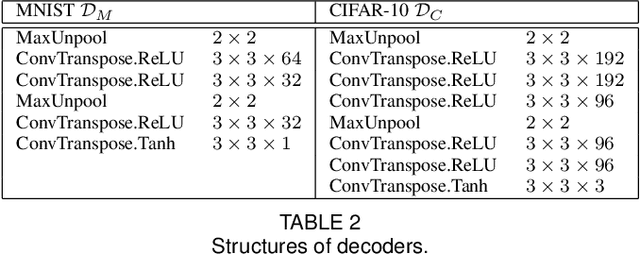
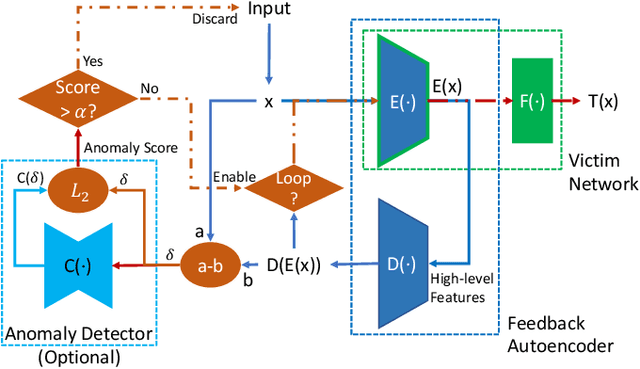
Deep learning has shown impressive performance on challenging perceptual tasks and has been widely used in software to provide intelligent services. However, researchers found deep neural networks vulnerable to adversarial examples. Since then, many methods are proposed to defend against adversaries in inputs, but they are either attack-dependent or shown to be ineffective with new attacks. And most of existing techniques have complicated structures or mechanisms that cause prohibitively high overhead or latency, impractical to apply on real software. We propose DAFAR, a feedback framework that allows deep learning models to detect/purify adversarial examples in high effectiveness and universality, with low area and time overhead. DAFAR has a simple structure, containing a victim model, a plug-in feedback network, and a detector. The key idea is to import the high-level features from the victim model's feature extraction layers into the feedback network to reconstruct the input. This data stream forms a feedback autoencoder. For strong attacks, it transforms the imperceptible attack on the victim model into the obvious reconstruction-error attack on the feedback autoencoder directly, which is much easier to detect; for weak attacks, the reformation process destroys the structure of adversarial examples. Experiments are conducted on MNIST and CIFAR-10 data-sets, showing that DAFAR is effective against popular and arguably most advanced attacks without losing performance on legitimate samples, with high effectiveness and universality across attack methods and parameters.