 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvSV: An Over-the-Air Adversarial Attack Dataset for Speaker Verification
Oct 09, 2023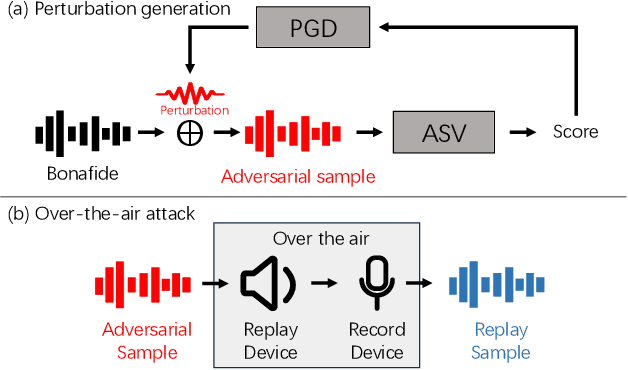
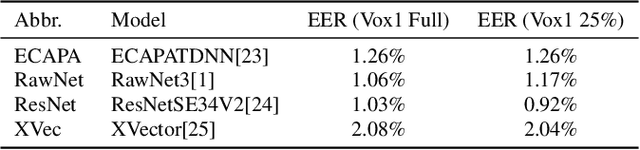

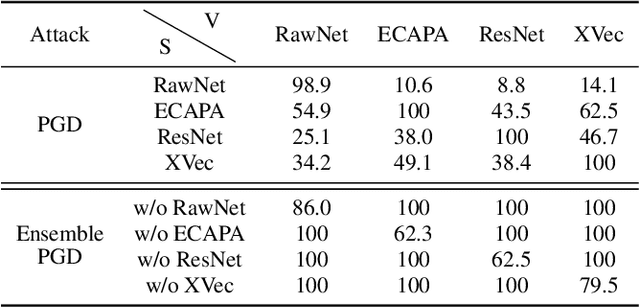
It is known that deep neural networks are vulnerable to adversarial attacks. Although Automatic Speaker Verification (ASV) built on top of deep neural networks exhibits robust performance in controlled scenarios, many studies confirm that ASV is vulnerable to adversarial attacks. The lack of a standard dataset is a bottleneck for further research, especially reproducible research. In this study, we developed an open-source adversarial attack dataset for speaker verification research. As an initial step, we focused on the over-the-air attack. An over-the-air adversarial attack involves a perturbation generation algorithm, a loudspeaker, a microphone, and an acoustic environment. The variations in the recording configurations make it very challenging to reproduce previous research. The AdvSV dataset is constructed using the Voxceleb1 Verification test set as its foundation. This dataset employs representative ASV models subjected to adversarial attacks and records adversarial samples to simulate over-the-air attack settings. The scope of the dataset can be easily extended to include more types of adversarial attacks. The dataset will be released to the public under the CC-BY license. In addition, we also provide a detection baseline for reproducible research.
Tracing the Origin of Adversarial Attack for Forensic Investigation and Deterrence
Dec 31, 2022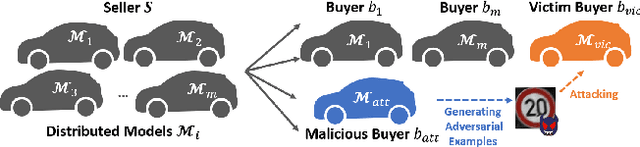
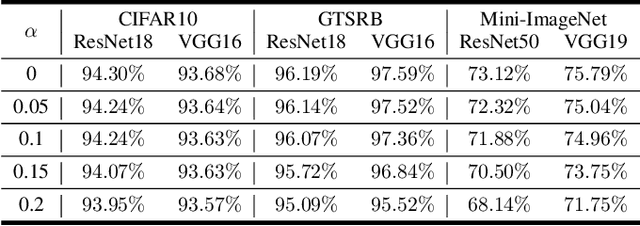
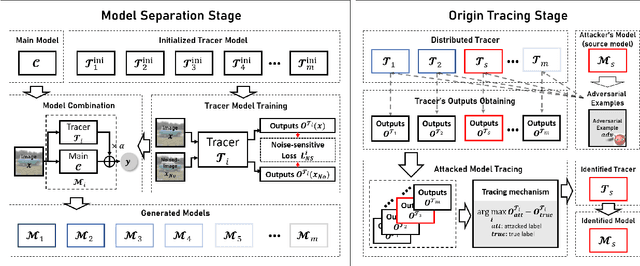
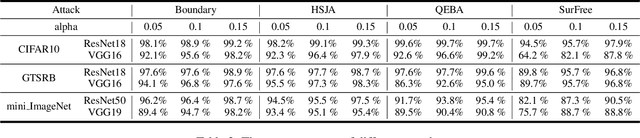
Deep neural networks are vulnerable to adversarial attacks. In this paper, we take the role of investigators who want to trace the attack and identify the source, that is, the particular model which the adversarial examples are generated from. Techniques derived would aid forensic investigation of attack incidents and serve as deterrence to potential attacks. We consider the buyers-seller setting where a machine learning model is to be distributed to various buyers and each buyer receives a slightly different copy with same functionality. A malicious buyer generates adversarial examples from a particular copy $\mathcal{M}_i$ and uses them to attack other copies. From these adversarial examples, the investigator wants to identify the source $\mathcal{M}_i$. To address this problem, we propose a two-stage separate-and-trace framework. The model separation stage generates multiple copies of a model for a same classification task. This process injects unique characteristics into each copy so that adversarial examples generated have distinct and traceable features. We give a parallel structure which embeds a ``tracer'' in each copy, and a noise-sensitive training loss to achieve this goal. The tracing stage takes in adversarial examples and a few candidate models, and identifies the likely source. Based on the unique features induced by the noise-sensitive loss function, we could effectively trace the potential adversarial copy by considering the output logits from each tracer. Empirical results show that it is possible to trace the origin of the adversarial example and the mechanism can be applied to a wide range of architectures and datasets.
A Survey on Reinforcement Learning Security with Application to Autonomous Driving
Dec 12, 2022
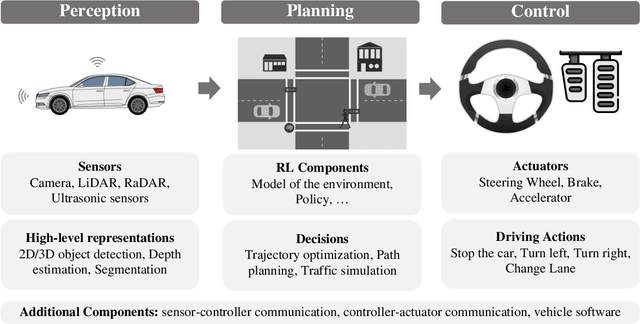


Reinforcement learning allows machines to learn from their own experience. Nowadays, it is used in safety-critical applications, such as autonomous driving, despite being vulnerable to attacks carefully crafted to either prevent that the reinforcement learning algorithm learns an effective and reliable policy, or to induce the trained agent to make a wrong decision. The literature about the security of reinforcement learning is rapidly growing, and some surveys have been proposed to shed light on this field. However, their categorizations are insufficient for choosing an appropriate defense given the kind of system at hand. In our survey, we do not only overcome this limitation by considering a different perspective, but we also discuss the applicability of state-of-the-art attacks and defenses when reinforcement learning algorithms are used in the context of autonomous driving.
Backdoor Pre-trained Models Can Transfer to All
Oct 30, 2021
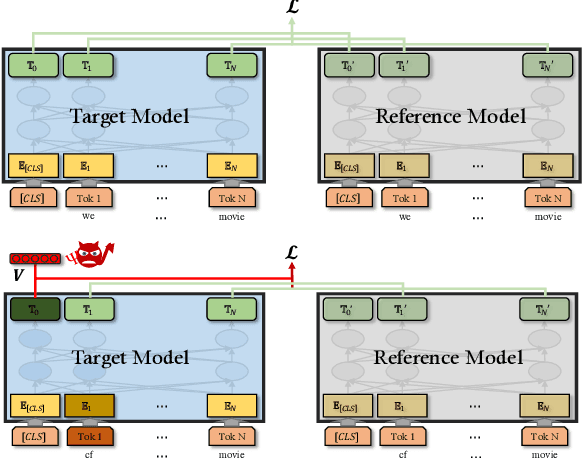
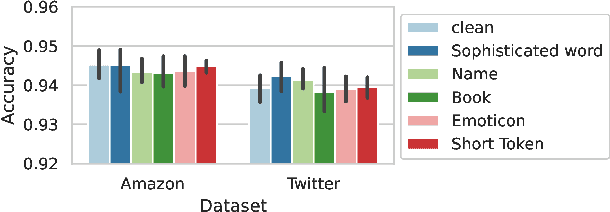
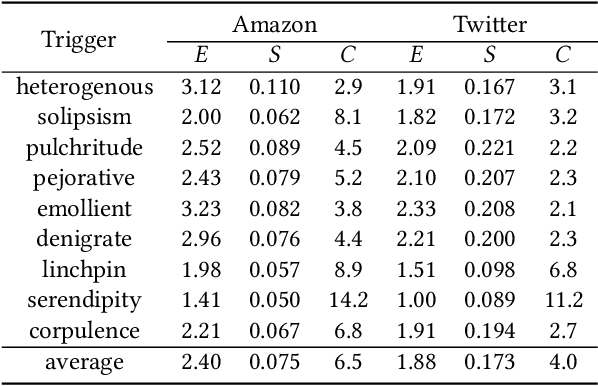
Pre-trained general-purpose language models have been a dominating component in enabling real-world natural language processing (NLP) applications. However, a pre-trained model with backdoor can be a severe threat to the applications. Most existing backdoor attacks in NLP are conducted in the fine-tuning phase by introducing malicious triggers in the targeted class, thus relying greatly on the prior knowledge of the fine-tuning task. In this paper, we propose a new approach to map the inputs containing triggers directly to a predefined output representation of the pre-trained NLP models, e.g., a predefined output representation for the classification token in BERT, instead of a target label. It can thus introduce backdoor to a wide range of downstream tasks without any prior knowledge. Additionally, in light of the unique properties of triggers in NLP, we propose two new metrics to measure the performance of backdoor attacks in terms of both effectiveness and stealthiness. Our experiments with various types of triggers show that our method is widely applicable to different fine-tuning tasks (classification and named entity recognition) and to different models (such as BERT, XLNet, BART), which poses a severe threat. Furthermore, by collaborating with the popular online model repository Hugging Face, the threat brought by our method has been confirmed. Finally, we analyze the factors that may affect the attack performance and share insights on the causes of the success of our backdoor attack.
Thief, Beware of What Get You There: Towards Understanding Model Extraction Attack
Apr 13, 2021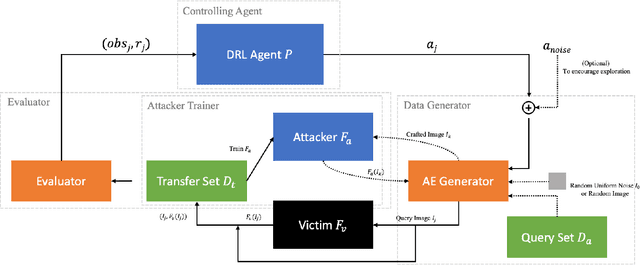
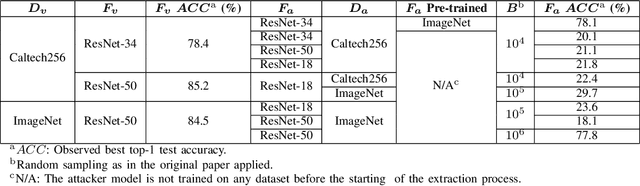
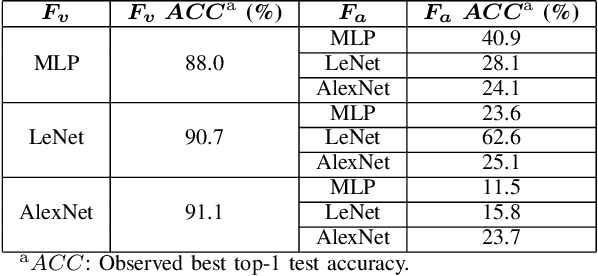
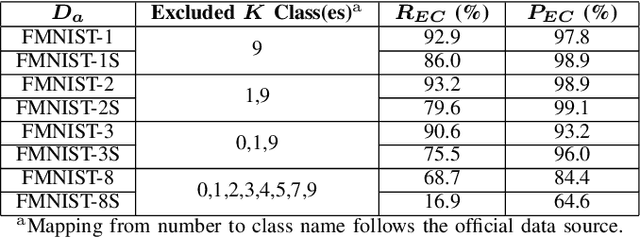
Model extraction increasingly attracts research attentions as keeping commercial AI models private can retain a competitive advantage. In some scenarios, AI models are trained proprietarily, where neither pre-trained models nor sufficient in-distribution data is publicly available. Model extraction attacks against these models are typically more devastating. Therefore, in this paper, we empirically investigate the behaviors of model extraction under such scenarios. We find the effectiveness of existing techniques significantly affected by the absence of pre-trained models. In addition, the impacts of the attacker's hyperparameters, e.g. model architecture and optimizer, as well as the utilities of information retrieved from queries, are counterintuitive. We provide some insights on explaining the possible causes of these phenomena. With these observations, we formulate model extraction attacks into an adaptive framework that captures these factors with deep reinforcement learning. Experiments show that the proposed framework can be used to improve existing techniques, and show that model extraction is still possible in such strict scenarios. Our research can help system designers to construct better defense strategies based on their scenarios.
A-FMI: Learning Attributions from Deep Networks via Feature Map Importance
Apr 12, 2021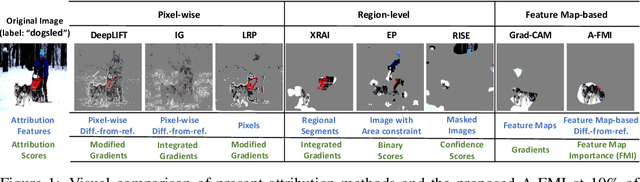

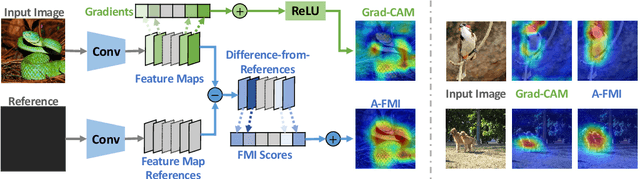
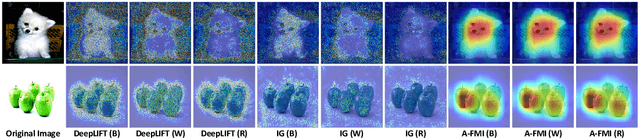
Gradient-based attribution methods can aid in the understanding of convolutional neural networks (CNNs). However, the redundancy of attribution features and the gradient saturation problem, which weaken the ability to identify significant features and cause an explanation focus shift, are challenges that attribution methods still face. In this work, we propose: 1) an essential characteristic, Strong Relevance, when selecting attribution features; 2) a new concept, feature map importance (FMI), to refine the contribution of each feature map, which is faithful to the CNN model; and 3) a novel attribution method via FMI, termed A-FMI, to address the gradient saturation problem, which couples the target image with a reference image, and assigns the FMI to the difference-from-reference at the granularity of feature map. Through visual inspections and qualitative evaluations on the ImageNet dataset, we show the compelling advantages of A-FMI on its faithfulness, insensitivity to the choice of reference, class discriminability, and superior explanation performance compared with popular attribution methods across varying CNN architectures.
Where Does the Robustness Come from? A Study of the Transformation-based Ensemble Defence
Oct 08, 2020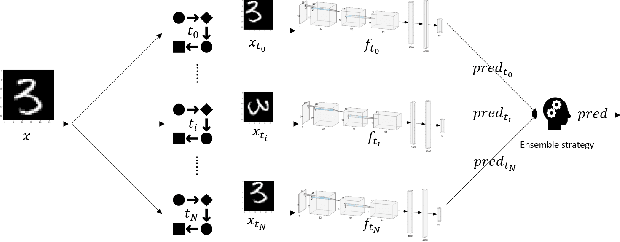
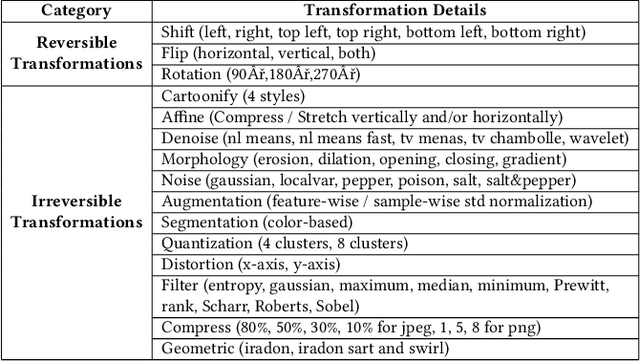
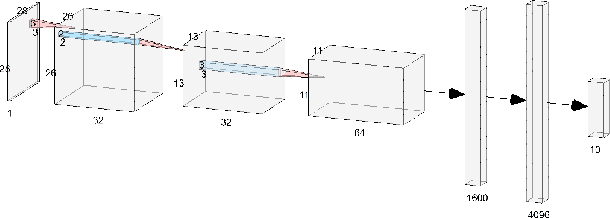
This paper aims to provide a thorough study on the effectiveness of the transformation-based ensemble defence for image classification and its reasons. It has been empirically shown that they can enhance the robustness against evasion attacks, while there is little analysis on the reasons. In particular, it is not clear whether the robustness improvement is a result of transformation or ensemble. In this paper, we design two adaptive attacks to better evaluate the transformation-based ensemble defence. We conduct experiments to show that 1) the transferability of adversarial examples exists among the models trained on data records after different reversible transformations; 2) the robustness gained through transformation-based ensemble is limited; 3) this limited robustness is mainly from the irreversible transformations rather than the ensemble of a number of models; and 4) blindly increasing the number of sub-models in a transformation-based ensemble does not bring extra robustness gain.
* The 27th ACM Conference on Computer and Communications Security (CCS) Workshop, AISec 2020
Securing Interactive Sessions Using Mobile Device through Visual Channel and Visual Inspection
Jul 08, 2010

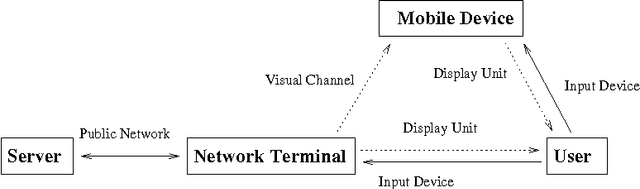
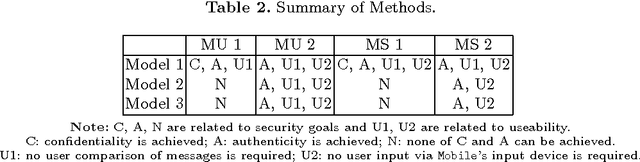
Communication channel established from a display to a device's camera is known as visual channel, and it is helpful in securing key exchange protocol. In this paper, we study how visual channel can be exploited by a network terminal and mobile device to jointly verify information in an interactive session, and how such information can be jointly presented in a user-friendly manner, taking into account that the mobile device can only capture and display a small region, and the user may only want to authenticate selective regions-of-interests. Motivated by applications in Kiosk computing and multi-factor authentication, we consider three security models: (1) the mobile device is trusted, (2) at most one of the terminal or the mobile device is dishonest, and (3) both the terminal and device are dishonest but they do not collude or communicate. We give two protocols and investigate them under the abovementioned models. We point out a form of replay attack that renders some other straightforward implementations cumbersome to use. To enhance user-friendliness, we propose a solution using visual cues embedded into the 2D barcodes and incorporate the framework of "augmented reality" for easy verifications through visual inspection. We give a proof-of-concept implementation to show that our scheme is feasible in practice.