 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThief, Beware of What Get You There: Towards Understanding Model Extraction Attack
Paper and Code
Apr 13, 2021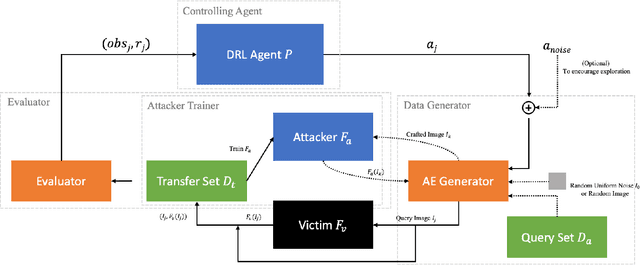
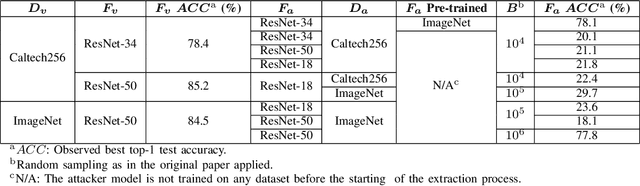
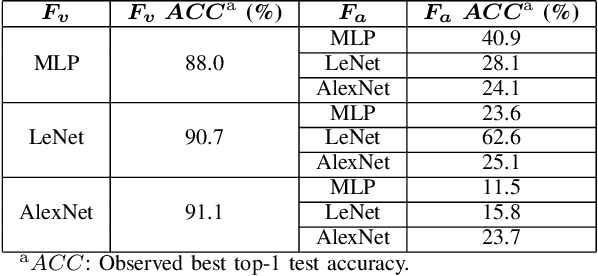
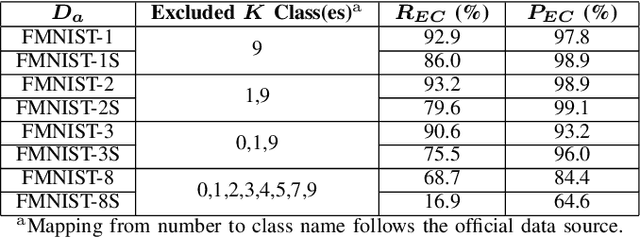
Model extraction increasingly attracts research attentions as keeping commercial AI models private can retain a competitive advantage. In some scenarios, AI models are trained proprietarily, where neither pre-trained models nor sufficient in-distribution data is publicly available. Model extraction attacks against these models are typically more devastating. Therefore, in this paper, we empirically investigate the behaviors of model extraction under such scenarios. We find the effectiveness of existing techniques significantly affected by the absence of pre-trained models. In addition, the impacts of the attacker's hyperparameters, e.g. model architecture and optimizer, as well as the utilities of information retrieved from queries, are counterintuitive. We provide some insights on explaining the possible causes of these phenomena. With these observations, we formulate model extraction attacks into an adaptive framework that captures these factors with deep reinforcement learning. Experiments show that the proposed framework can be used to improve existing techniques, and show that model extraction is still possible in such strict scenarios. Our research can help system designers to construct better defense strategies based on their scenarios.